大学毕业一年收获还是满满的!手动滑稽
今天呢,来记录一个爬虫项目,用的web-magic实现,不说Java和Python那个更强,只看那个代价更小,与现在我而言自然是Java喽!同时呢magic也是参考了Scrapy框架的。
先把git地址掏出来:https://gitee.com/xxxx/magicFetch.git(留言给地址)
言归正传,先说爬虫需要什么:
1、明确要做的事情:爬虫,爬哪个网站。
2、从哪里开始:爬虫的入口(启停配)Spider
3、接下来便是如何进行爬取和爬取结果的处理。
详细:
如何启动,如何配置,如何停止:
Spider.create(new Getxgluo())
.thread(10) //线程,magic是支持多线程的
.addUrl(t) //t:要爬取的网站URL
.addPipeline(new MyPipeline()) //添加一个对爬取结果的处理操作类--输出到console
.addPipeline(new MyFilePipeline()) //再添加一个对爬取结果的处理操作类--输出到文件
.run(); //爬虫诞生,去吧皮卡丘,把我想要的拿回来.
靓仔,你没猜错,create方法是静态的,所以可以用类名直接调用,run方法就是入口,该方法执行的时候爬虫就启动了。
这些是Spider最常用的配置了,至于骚操作作者就……,大家可以问问度娘,或者直接从 https://github.com/code4craft/webmagic.git获取项目,直接分析代码(如果觉着作者陋,欢迎吐槽)。
启动了,基本配置有了,我们该设计自己的逻辑了,这个时候我们就要找自己想要爬取的内容在网页的什么位置。
找到网页查看源代码找到需要爬取的内容的标签如:
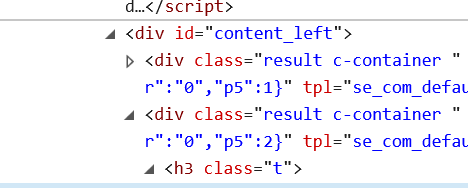
这里我们有id属性,那么我们知道在一个网页中的id属性是唯一的,因此我们可以借助这个属性,进行匹配
String xpathFB = "[@id=content_left]/div[2]/h3/text()";
我们利用html提供的xpath便可以根据上面提供的网页中的位置,找到h3标签中的内容。
现在位置找到了,要开始抓数据了,我们上面说到Spider.run的时候爬虫已经放出去了,刚刚我们有指定了爬虫的目标,现在要开始采蜜了。
请你回头看看我,Spider.create(new Getxgluo())这里我们创建了一个对象作为参数,但这个类可是作者自己写的(当然你也可以),但是这个类可是需要实现PageProcess借口的,而且要重写process方法,而这个方法就是我们采蜜动作的设计。
在这里我们需要对爬的网址进行正则匹配,不然地址都错了,那还玩个球啊。地址正确就用到网页中的位置xpathFB了。
html.xpath(xpathFB).toString();
通过Xpath我们就能获取到了h3中的内容存到字符串中了,那岂不是可以为所欲为了。
哈哈,只剩一步了,对获取内容的保存或者输出。
这个时候拿出最后一把宝剑:Pipeline 来进行后续的操作,比如用于输出到console中的consoPipeline类和FilePipeline类,当然我们也可以自己重写Pipeline来创建自己的逻辑。
如果我们用了Pipeline及其子类,我们还需要new吗?记住不需要,不需要,不需要,这里用的回调函数,你需要在实现Pipeline的时候重写process方法,你写的逻辑就能被自动调用(真香)。
好了,现在我们三个步骤都完成了。愉快的试一下吧