接口
--------------------------------------------------------------------------------
一、接口(是一种规范)
1.接口名/接口文件与类类似,也是用.java文件编写
2.关键字 interface 接口名命名规范与类名相同 习惯上可以使用I开头表示
3. 接口额访问修饰符只能使用public和default修饰不能使用private和protected
在接口中默认缺省为public
4.接口中的所有属性只能为公开的静态的常量
而且public/static/final都可省略
5.接口中的所有方法必须为公共的抽象方法 且抽象方法中的abstract/public可省略
省略后依然是公开的
--------------------------------------------------------------------------------
二、实现类实现接口
1.一个类实现接口使用Implements关键字
实现类实现一个接口必须重写接口中的所有抽象方法 除非是抽象类
2.一个类可以实现多个接口 多个接口之间用逗号间隔
3.接口的引用可以指向其实现类的对象。类似于父类引用指向子类对象
因此可以使用接口实现多态
--------------------------------------------------------------------------------
三、接口继承接口
1.接口可以继承接口,使用extends关键字;接口的继承与类相同
2.接口可以多继承 使用多个父接口,使用逗号分割,
子接口继承父接口将拥有父接口的所有抽象方法
--------------------------------------------------------------------------------
四、接口的优点
1.可以被多继承
2.设计和实现完全分离
3.更自然的使用多肽
4.更容易搭建程序框架
5.更容易更换实现
--------------------------------------------------------------------------------
五、接口和抽象类的区别
1.本质区别 关键字不同 class interface
子类继承抽象类 子类必须与父类是一类事物 必须符合"is a"关系
例如Chinese are peope
接口只是对功能的扩展,多个实现类实现接口时
并不要求所有的抽象类是一类事物
接口符合"like a"关系,理解为X具备一个X功能
例 人狗 都有吃饭功能 都可以实现吃饭接口
但是两者吃饭功能不能从同一父类中继承
2.抽象类是类 接口是规范
3.接口可继承接口 并可多继承接口可多实现 但类只能单根继承
4.接口只能做方法声明,抽象类中可以做方法声明,也可以做方法实现
5.抽象类能够保证实现的层次关系,而借口则是能够更有效地分离行为和实现
6.抽象类可以有自己属性 接口智能有静态常量
7.接口中智能有抽象方法,抽象类中可以有抽象方法
集合框架
对常用的数据结构和算法做一些规范(接口)和实现(具体实现接口的类)
--------------------------------------------------------------------------------
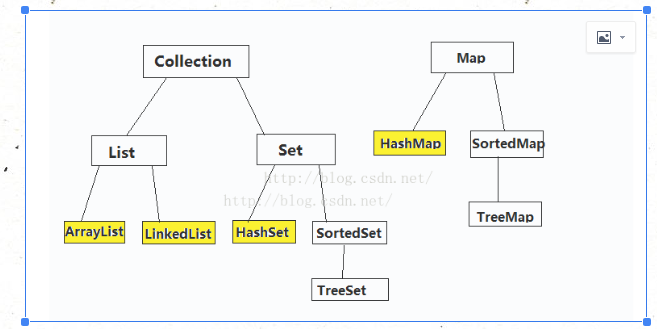
一、集合框架的接口
Collection:存储一组不唯一 无序的对象
List:存储一组不唯一 有序
Set存储一组唯一 无序的对象
Map存储一组键值对象,提供key到value的映射(key不能重复)
--------------------------------------------------------------------------------
二、List 常用方法 (ArraysList:长度可变的数组)
【List接口】
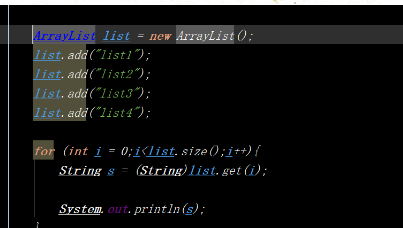
1、常用方法:
① add():在列表的最后添加元素;
② add(int index,E element):在列表的指定位置插入元素;
③ size():返回当前列表的元素个数;
④ get(int index):返回下标为index的元素。
如果没有泛型约束,返回Object类型,需要强转;如果有泛型约束,直接返回泛型类型,无需强转。
⑤ clear():清除列表中的所有数据
isEmpty():检测列表是否为空
⑥ contains():传入一个对象,检测列表中是否包含该对象。
如果传入的是String和基本数据类型,可以直接比对
如果传入的是实体类,则默认只比对两个对象的地址。因此,需要在实体类重写equals()方法;
Tips:
String s = "123";
="123".equals(s);//这个顺序可以防止空指针
⑦ indexOf():传入一个对象,返回该对象在列表中首次出现的地址。
lastIdexOf():传入一个对象,返回该对象在列表中最后一次出现的地址。
⑧remove():传入一个下标,或者一个对象,删除指定元素;
如果传入下标,返回被删除的对象,如果下标大于size(),会报下标越界异常;
如果传入对象,则要求重写equals方法,返回true或false表示删除是否成功
⑨set(index, obj):用新传入的对象,将指定位置的元素替换掉;
返回被替换掉的元素对象。
⑩subList(1,3):截取一个子列表,返回List类型
⑪toArray() 将列表转为数组 返回一个object类型的数据
--------------------------------------------------------------------------------
三、使用iterator迭代器遍历列表
1.使用列表调用 .iterator()返回一个迭代器对象
2.使用迭代器对象调用.hasNext()判断是否有下一条数据
3.使用迭代器对象调用.next()取出下一条数据
--------------------------------------------------------------------------------
四、ArrayList LinkedList
1.ArrayList 实现一个长度可变的数组,在内存空间中开辟一串连续的空间,
与数组的区别在于长度可以随意的改变,
这只能存储结构在寻欢遍历和随机访问元素的速度比较快
2.LinkedList 使用链表结构存储数据,再插入和删除元素时速度非常快
特有方法
①addFirst():开头插入元素
addLast():结尾插入元素
②removeFirst() 删除第一个元素,并返回被删除的元素
removeLast()删除最后一个元素,并返回被删除的元素
③getFirst()返回列表的第一个元素 不删除
getLast()返回列表的最后一个元素 不删除
Set接口
1.常用方法:与List接口基本相同
但是,由于set接口中的元素是无序的,因此没有与下标相关的方法
2.Set接口的特点:唯一,无序
取出set方法
使用for each遍历
使用迭代器遍历
3.HashSet 底层调用HashMap的方法 传入数据后 根据数据的hashcode进行散列运算
得到一个散列值后在进行运算,确定数据在序列中存储的位置
4.HashSet如何确定一个对象是否相等
先判断对象的hashcode()是否相等 若不等 肯定不是一个对象
若相等 继续判断equals()方法;
重写equals()方法
所以使用HashSet存储实体对象时,必须重写对象的hashCode() 和equals()两个方法
LinkedHashSet 在HashSet的基础上,新增一个链表
用链表来记录HashSet中元素放入的顺序,因此使用迭代器遍历时,可以按照放入的顺序依次
读出元素
comparator 需要单独一个比较类进行实现,重写compare()的方法,实例化TreeSet的对象,需要哦转入这个比较类的对象
Map
1.Map 接口特点 以键值对的形式存储数据,以键取值,键不能重复值可以重复
2.put(key value) 最后追加一个键值
get 通过键取值
clear清除所有数据
HashMap 与Hashtable区别
1.后者线程安全 前者不安全
2.后者键不能为null 前者可以
HashMap和Hashtable的区别
两者最主要的区别在于Hashtable是线程安全,而HashMap则非线程安全。Hashtable的实现方法里面都添加了synchronized关键字来确保线程同步,因此相对而言HashMap性能会高一些,我们平时使用时若无特殊需求建议使用HashMap,在多线程环境下若使用HashMap需要使用Collections.synchronizedMap()方法来获取一个线程安全的集合(Collections.synchronizedMap()实现原理是Collections定义了一个SynchronizedMap的内部类,这个类实现了Map接口,在调用方法时使用synchronized来保证线程同步,当然了实际上操作的还是我们传入的HashMap实例,简单的说就是Collections.synchronizedMap()方法帮我们在操作HashMap时自动添加了synchronized来实现线程同步,类似的其它Collections.synchronizedXX方法也是类似原理。
HashMap可以使用null作为key,不过建议还是尽量避免这样使用。HashMap以null作为key时,总是存储在table数组的第一个节点上。而Hashtable则不允许null作为key。
HashMap继承了AbstractMap,HashTable继承Dictionary抽象类,两者均实现Map接口。
HashMap的初始容量为16,Hashtable初始容量为11,两者的填充因子默认都是0.75。
HashMap扩容时是当前容量翻倍即:capacity*2,Hashtable扩容时是容量翻倍+1即:capacity*2+1。
HashMap和Hashtable的底层实现都是数组+链表结构实现。
两者计算hash的方法不同:
Hashtable计算hash是直接使用key的hashcode对table数组的长度直接进行取模:
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
HashMap计算hash对key的hashcode进行了二次hash,以获得更好的散列值,然后对table数组长度取摸:
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
static int indexFor(int h, int length) {
return h & (length-1);
}
在HashMap 中,null 可以作为键,这样的键只有一个;可以有一个或多个键所对
应的值为null。当get()方法返回null 值时,既可以表示HashMap 中没有该键,也可
以表示该键所对应的值为null。因此,在HashMap 中不能用get()方法来判断HashM
ap 中是否存在某个键,而应该用containsKey()方法来判断。Hashtable 的键值都不能
为null,所以可以用get()方法来判断是否含有某个键。
LinkedHashMap
可以使用链表 计入数据放入的次序
Collections是Java中专门用于操作的集合工具类
Collection是一个接口
sort方法 对 集合中的数据进行排序
如果集合存储的是一个实体对象那么
1 实体类实现Comparable接口,并重写CompareTo方法
2.在sort的第二个参数,传入比较器,比较器需实现comparable接口,并重写compare方法
【泛型】
1、泛型就是“参数化类型”。在定义类型时,不将类型定死。而是采用泛型参数的形式进行定义。调用时传入具体的泛型参数。
【泛型类的特点】
在声明类的时候,进行泛型约束,这样的类叫泛型类。
class Test<T>{
//<T>可以理解为泛型声明时的形参,可以用任何字母代替。常用T N E
//在泛型类中,T就可以当做特殊的数据类型进行使用
private T arg;
}
//泛型调用时,需要将实际的数据类型进行传入
Test<String> test1 = new Test<String> ("姜浩真帅!");
Test<Integer> test2 = new Test<Integer>(123);
1、泛型只在编译阶段生效。同一个类通过不同泛型拿到的对象,使用getClass()判断是属于同一个类的。
System.ou.println(test1.getClass() == test2.getClass());
//取到的test1的类为Test类,不是Test<T>类
2、同一个类,通过不同泛型拿到的对象,相互不兼容。不能互相赋值。
test2 = test1;//test1与test2不兼容
3.泛型类 在实例化的时候,可以不传入泛型,类中的数据类型,在赋值的时候传入的变量类型为空
4.实例化泛型时,智能传入类名,可以是系统类也可以是自定义实体类
泛型通配符上边界,使用?extends类名表示通配符只支持指定类的子类
Test<?extends Number>testS = new Test<Number>();
泛型通配符下边界,使用?super类名,表示通配符只支持指定类及其超类;
泛型的接口
1.声明
interface inter<T>{
void Test(T t );
}
2.实现类 如果实现泛型接口,那么不能直接使用接口的泛型,那么需要重新声明
class Test3<T> implements inter<T>{
@Override
public void Test(T t){}
}
3.如果实现类,不想作为泛型类,那么,可以在实现接口时,直接给接口的泛型赋值
class Test3 implements inter<String>{
@Override
public void Test(String t){}
}
泛型方法
1.不一定在泛型类中 可以独立于泛型类在任何类中都可以单独使用
class Test{
public static <T> void test(T t){}
}
调用 Test.test("String");
2.使用泛型方法可以实现可变参数的方法
class Test{
/使用...表示可以接受n个任意类型的参数也可以是数组
public static <T> void test(T......t){}
}
通用:Test.test("String","String2",123,true)
3.只有在方法中声明了<T>的方法 才能是泛型方法
而如果在方法中,使用额类的泛型 则不是泛型方法
注意:
静态方法不能使用类的泛型
智能将静态方法单独声明为泛型方法
递归
1.在函数自身内部,调用函数本身的方式,称为递归
2.包括递进去 归出来两部分

3.递归必须通过合适的语句,及时退出 否则出现死循环
++BuffererdInputStream
1.作用:
在基本流的基础上进行包装 读取或者写入文件时 将通过缓存进行
即现将内容写入到缓存区 缓存区已满才进行读取或者写入操作
优点: 可以大大减少文件的操作次数,提高写入效率
2.缓存流的使用、
在基础流之上进行包装
new BufferedInputStream(new FileInputStream())
为IO链 ,关闭只需要你关闭最外层流,内容将自动关闭
3.BufferedOutputStream在关闭前通常bos.flush();
在程序最后刷新缓存流 将缓存流中未满的内容错写入到文件中,调用close方法 将自动刷新
DataOutputStream DataInputStream
采用二进制对文件进行操作
与基本数据流相比,可以直接读写java中的基本数据类型
另外 如果操作的文件是一个二进制文件 需要使用DataOutputSream替代FileOutputStream
同样 Data系列的流,也有read和write方法,操作与基本相同
注意 DataOutputStream 写入二进制文件 只能使用 DataInputStream文件读取
ObjectOutputStream ObjecInputStream
作用
直接继承自:java.IO.OutputStream
1.与基本流相同 可以用read write 方法进行读写
2.与DataOutputStream相同 乐意对java基本数据类型进行读写 :readInt() writeDouble()
3可以使用readObject() 和 直接对对象进行操作
对象的序列化和反序列化
1.对象的序列化 将程序中的对象 持久化保存在文件中的过程
2.反序列化 将文件中保存的对象 重新读取到程序中的过程
private static final long serialVersionUID = 6869255210100342059L;
添加以后 ,可以用ID表示序列化和反序列化时操作的对象,是同一个对象
如果不添加版本ID,当序列化一个对象后,如果实体类属性有增删,在进行反序列化时,会造成错误,因为系统认为这已经不是一个类
I/O操作
1.File类
(1)作用:用于对磁盘文件进行操作。删除、创建等。
(2)三种构造函数:
①File file1 = new File("F:\test\test.txt");
直接传入一个路径,拿到一个文件或者是文件夹
②File file2 = new File("F:\test","test.txt");
第一个参数传入一个父路径、第二个参数传入子路径或者文件。
③File file3 = new File(file1,"test.txt");
第一个参数传入一个父路径的file对象,第二个参数传入子路径或者文件。
(3)路径的表示:.
文件夹的分隔,可以使用"/"(通常用于Linux,Windows也适用)也可以使用"\"(通常用于Windows),注意一个需要转义。
/**
* 按照字节一个一个读取文件
*/
int n = -1;
while((n=fis.read()) != -1){
sb.append((char)n);
}
System.out.println(sb);
/**
* 将比特数组直接声明为输入流的长度,一次性读出所有文字
*/
byte[] bytes = new byte[fis.available()];
fis.read(bytes);
sb.append(new String(bytes));
System.out.println(sb);
/**
* 一次性读取1024个字节
*/
byte[] bytes = new byte[1024];
int n=-1;
while ((n = fis.read(bytes))>-1) {
sb.append(new String(bytes));
}
System.out.println(sb);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
/*
File类
*/
File file1 = new File("F");
File file3 = new File("F");
System.out.println();
/*
检测文件是否刻度
*/
System.out.println(file1.canRead());
/*
检测文件是否可写
*/
System.out.println(file1.canWrite());
/*
检测两个对象是否相等
*/
System.out.println(file1.equals(file3));
/*
检测文件是否存在
*/
System.out.println(file1.exists());
/*
取到文件的绝对路径
*/
System.out.println(file1.getAbsoluteFile());
/*
取到文件夹名
*/
System.out.println(file1.getName());
/*
取到文件的父路径
*/
System.out.println(file1.getParent());
/*
检测文件是否为绝对路径
*/
System.out.println(file1.isAbsolute());
/*
检测当前文件是否是目录
*/
System.out.println(file1.isDirectory());
/*
检测当前文件是否是文件
*/
System.out.println(file1.isFile());
/*
删除文件
删除成功为true
*/
System.out.println(file1.delete());
/*
删除文件
*/
try {
System.out.println(file1.createNewFile());
} catch (IOException e) {
e.printStackTrace();
}
/*
创建文件夹,只有当文件不存在时,才能创建成功
mkdir: 只能创建一层目录,但是倒数第二层目录也不存在 将创建失败
mkdirs: 可以创建多层目录,无论有几层不存在都可以依次创建
*/
System.out.println(file1.mkdir());
/*
获得文件所在分区的总大小和可用大小 以字节为单位
*/
System.out.println(file1.getTotalSpace());
System.out.println(file1.getUsableSpace());
/*
返回当前文件或文件夹的大小
*/
System.out.println(file1.length());
/*
返回当前文件所有文件和文件夹名字 返回String数组
*/
String[] list = file1.list();
for (String item : list){
System.out.println(item);
}
/*
返回当前目录所有的文件和文件夹路径 返回File数组
*/
File[] files = file1.listFiles();
for (File file:files
) {
System.out.println(file.getParent()+"--------"+file.getName());
}
Reader&Writer
字符流
1.在处理数据单元时,以一个字符作为单位而字节流以字节为单位
2.字符流基类: Reader Writer 为抽象类
FileReader FileWriter是直接继承自抽象类的两个字符流的基类
3.FileReader FileWriter在读写文件的时候
只能使用系统默认的编码格式 无法制定编码 如果文件格式和系统默认格式不一致 那使用这两种方式读写 将产生乱码
InputStringReader outputStringWriter
1.将字符流转为字节流 同时支持自定义读写编码格式
2.常见编码格式
ASCII:美国标准信息码
ISO8859-1:欧洲码
ANSU编码:可以分为多种】
简体中文:
GB2312
GBK
繁体中文
big_5
Unicode编码:国际标准码 :兼容绝大部分国家编码格式
可以分为:UTF-6 UTF-8 UTF-16
BufferedReader BufferedWriter
缓存流存储。
异常及日志
--------------------------------------------------------------------------------
学习目标
使用try_catch_finally处理异常
使用throw throws抛出异常
使用log4j记录日志
--------------------------------------------------------------------------------
一、异常
--------------------------------------------------------------------------------
1.定义:在程序的运行中多发生的不正常的事,会中断正在运行的程序。
2.Java中所有异常和错误的基类:Throwable.
3.Java中的异常分为运行时异常和检查时异常;
运行时异常是表示RuntimeException以及所有子类,
这些异常无需在程序中进行捕获,大多可以通过代码进行控制避免。
检查时异常表示除了RuntimeException以及所有子类,
这些异常必须进行捕获。
--------------------------------------------------------------------------------
4.使用try—catch进行异常的捕获
try :包裹可能出现异常的代码
catch多个: 进行不同的异常处理操作
当try中的程序出现异常时,将进行对应的catch进行操作,而不会再执行try块里剩余打的代码
捕获异常后,若出现异常,将不会中断程序运行
catch块可以有多个 最后使用Exception结束,表示捕获所有异常,但是多个catch块在顺序上必须从小到大
5.e.getMessage()拿到错误信息
e.printStackTrace();打印错误堆栈信息
6.try-catch结构,如果要确保运行不被中断,必须确保捕获所有异常。
7.finally表示无论程序是否出现异常,都必须执行的语句.即使try中有return语句,也必须执行。通常用于流的关闭,资源将不再释放。
但是System.exit(0);退出程序 finally不再执行
8.try-finally可以组合存在去,而不一定包含catch
表示异常不进行出路,但是finally必须执行
--------------------------------------------------------------------------------
1.异常的第二种处理机制 抛出异常
使用throws在方法的声明上进行抛出,由调用该方法的方法进行捕获 或继续抛出,在main方法中进行处理 若继续抛出将会导致城西出现异常无法被发现。
2.throws如果抛出多个异常 使用逗号分隔!
3.throw在程序中,手动抛出异常。
4.如果使用throw抛出的是一个检查型异常,那么必须在方法体上,使用theows进行抛出声明,若为运行时异常,则不必。
5.自定义异常类:必须继承自现有异常
通常继承Exception或者RuntimeException,分别表明了检查和运行时异常
--------------------------------------------------------------------------------
日志
1.通过Logger.getLogger()拿到一个日志对象,参数传入本类.class
2. 导入log4j.jar
3.在src目录同级下,创建log4j.properties配置文件
4.使用日志对象,分别调用不同级别的打印语句,进行日志的输出
log.debug("打印一条测试信息");
log.info("打印一条info信息");
log.warn("打印一条warn信息");
log.error("打印一条error信息");
5.Appender 为日志输出目的地,Log4j提供的appender有以下几种:
org.apache.log4j.ConsoleAppender(控制台),
org.apache.log4j.FileAppender(文件),
org.apache.log4j.DailyRollingFileAppender(每天产生一个日志文件),
org.apache.log4j.RollingFileAppender(文件大小到达指定尺寸的时候产生一个新的文件),
org.apache.log4j.WriterAppender(将日志信息以流格式发送到任意指定的地方)
6.Layout:日志输出格式,Log4j提供的layout有以下几种:
org.apache.log4j.HTMLLayout(以HTML表格形式布局),
org.apache.log4j.PatternLayout(可以灵活地指定布局模式),
org.apache.log4j.SimpleLayout(包含日志信息的级别和信息字符串),
org.apache.log4j.TTCCLayout(包含日志产生的时间、线程、类别等等信息)
7.打印参数: Log4J采用类似C语言中的printf函数的打印格式格式化日志信息,如下:
%m 输出代码中指定的消息
%p 输出优先级,即DEBUG,INFO,WARN,ERROR,FATAL
%r 输出自应用启动到输出该log信息耗费的毫秒数
%c 输出所属的类目,通常就是所在类的全名
%t 输出产生该日志事件的线程名
%n 输出一个回车换行符,Windows平台为“
”,Unix平台为“
”
%d 输出日志时间点的日期或时间,默认格式为ISO8601,也可以在其后指定格式,比如:%d{yyy MMM dd HH:mm:ss , SSS},输出类似:2002年10月18日 22 : 10 : 28 , 921
%l 输出日志事件的发生位置,包括类目名、发生的线程,以及在代码中的行数。举例:Testlog4.main(TestLog4.java: 10 )
8.在代码中初始化Logger:
1)在程序中调用BasicConfigurator.configure()方法:给根记录器增加一个ConsoleAppender,输出格式通过PatternLayout设为"%-4r [%t] %-5p %c %x - %m%n",还有根记录器的默认级别是Level.DEBUG.
2)配置放在文件里,通过命令行参数传递文件名字,通过PropertyConfigurator.configure(args[x])解析并配置;
3)配置放在文件里,通过环境变量传递文件名等信息,利用log4j默认的初始化过程解析并配置;
4)配置放在文件里,通过应用服务器配置传递文件名等信息,利用一个特殊的servlet来完成配置。
9.
### set log levels ###
log4j.rootLogger = debug , stdout , D , E
### 输出到控制台 ###
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = %d{ABSOLUTE} %5p %c{ 1 }:%L - %m%n
### 输出到日志文件 ###
log4j.appender.D = org.apache.log4j.DailyRollingFileAppender
log4j.appender.D.File = logs/log.log
log4j.appender.D.Append = true
log4j.appender.D.Threshold = DEBUG ## 输出DEBUG级别以上的日志
log4j.appender.D.layout = org.apache.log4j.PatternLayout
log4j.appender.D.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n
### 保存异常信息到单独文件 ###
log4j.appender.D = org.apache.log4j.DailyRollingFileAppender
log4j.appender.D.File = logs/error.log ## 异常日志文件名
log4j.appender.D.Append = true
log4j.appender.D.Threshold = ERROR ## 只输出ERROR级别以上的日志!!!
log4j.appender.D.layout = org.apache.log4j.PatternLayout
log4j.appender.D.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n