李宏毅老师的机器学习课程和吴恩达老师的机器学习课程都是都是ML和DL非常好的入门资料,在YouTube、网易云课堂、B站都能观看到相应的课程视频,接下来这一系列的博客我都将记录老师上课的笔记以及自己对这些知识内容的理解与补充。(本笔记配合李宏毅老师的视频一起使用效果更佳!)
ML Lecture 4:Classification:Probabilistic Generative Model
在这堂课中,老师主要根据宝可梦各属性值预测其类型为例说明分类问题,其训练数据为若干宝可梦的各属性值及其类型。
1.分类问题不能当成回归问题来处理。
假设还不了解怎么做,但之前已经学过了regression。就把分类当作回归硬解。举一个二分类的例子:假设输入xx 属于类别1,或者类别2,把这个当作回归问题:类别1就当作target是1,类别2就当作target是-1。训进行训练:因为是个数值,如果数值比较接近1,就当作类别1,如果数值接近-1,就当做类别2。这样做遇到什么问题?如下图所示:
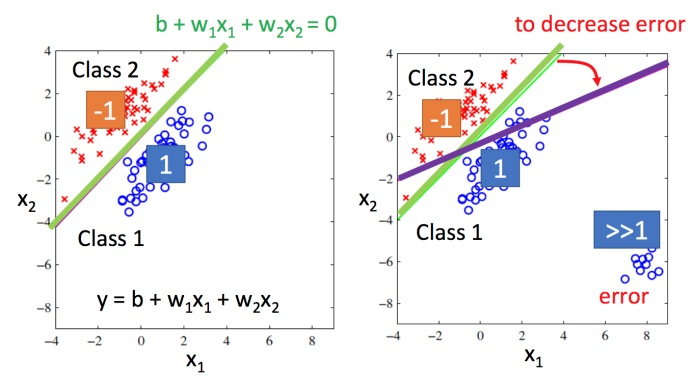
总结:左边绿色的线是分界线,绿色线左边红色点就是-1的,绿色线右边蓝色点就是1的。但是如果训练集有很多的距离远大于1的点,比如有图右下角所示,这样用回归的方式硬训练可能会得到紫色的这条。直观上就是将绿色的线偏移一点到紫色的时候,就能让右下角的那部分的值不是那么大了。但实际是绿色的才是比较好的,用回归硬训练并不会得到好结果。此时可以得出用回归的方式定义,对于分类问题来说是不适用的。还有另外一个问题:比如多分类,类别1当作target1,类别2当作target2,类别3当作target3…如果这样做的话,就会认为类别2和类别3是比较接近的,认为它们是有某种关系的;认为类别1和类别2也是有某种关系的,比较接近的。但是实际上这种关系不存在,它们之间并不存在某种特殊的关系。这样是没有办法得到好的结果。
2.Ideal Alternatives(理想替代品)-- Generative Model
假设现在宝可梦只有两类,要预测x属于哪类,若P(C1|x)>0.5则属于第一类,否则属于第二类。
计算P(C1|x)要用到贝叶斯公式,对Generative Model,P(x)=P(x|C1)P(C1)+P(x|C2)P(C2)是可算的,从训练数据中估计P(C1)、P(C2)、P(x|C1)、P(x|C2)这四个值。
P(C1)、P(C2)容易估计,算一下训练数据里两类各占多少就可以了。 要估计P(x|C1)、P(x|C2)就需要做一些假设。 我们假设训练数据中所有的第一类/第二类数据,都是分别从两类对应的高斯分布产生的。 理论上任何参数(μ,∑)的高斯分布都可以产生训练数据,只是likelihood不同。 用最大似然的方法可以得出,使得似然函数最大的参数(μ∗,∑∗)分别是训练数据中该类数据的平均值和协方差矩阵。 这样就可以求得P(C1|x)了。
Maximum Likelihood(最大似然估计)
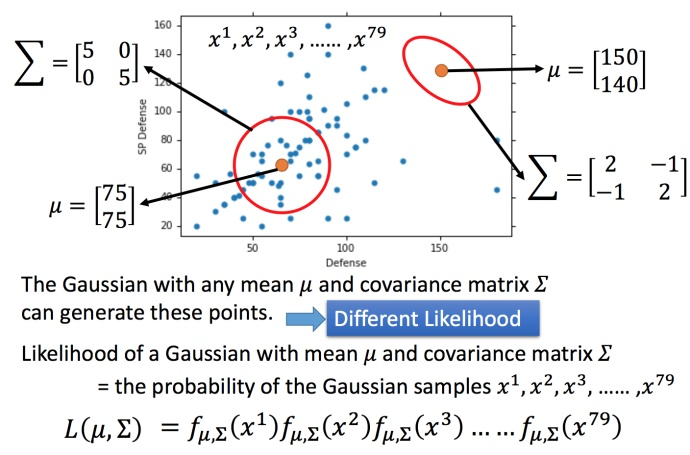
将使得 L(μ,Σ)最大的 (μ,Σ)记做 (μ∗,Σ∗),(μ∗,Σ∗)就是所有 (μ,Σ) 的 Maximum Likelihood(最大似然估计)!

这些解法很直接,直接对L(μ,Σ)L(μ,Σ) 求两个偏微分,求偏微分是0的点。
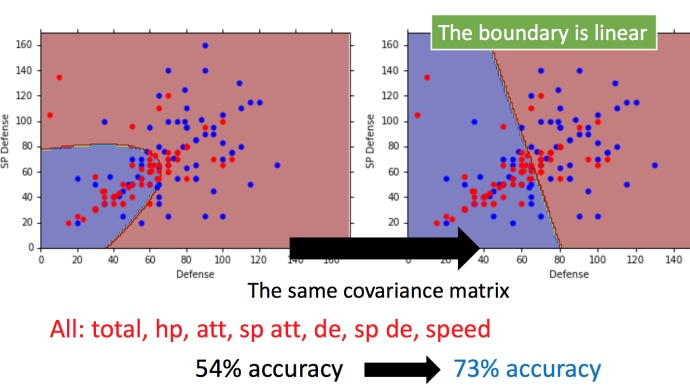
最后应用最大似然估计,在考虑了宝可梦的7种特征的情况下,这样的分类方法在测试集上的正确率只有54%。
Generative Model整个模型流程:
(1)要预测x属于哪类,若P(C1|x)>0.5则属于第一类,否则属于第二类。
(2)计算P(C1|x)要用到贝叶斯公式,对Generative Model,P(C1|x)=P(x|C1)P(C1)+P(x|C2)P(C2)是可算的
(3)理论上任何参数(μ,∑)的高斯分布都可以产生训练数据,所以可以估计P(x|C1)、P(x|C2)
(4)利用最大似然的方法,可以求出让似然函数最大的参数(μ∗,∑∗),这两个参数分别是训练数据中该类数据的平均值和协方差矩阵。 这样就可以求得P(C1|x)了
也就是第一节课说的三大步:

3.模型修改
通常来说,不会给每个高斯分布都计算出一套不同的最大似然估计,协方差矩阵是和输入feature大小的平方成正比,所以当feature很大的时候,协方差矩阵是可以增长很快的。此时考虑到model参数过多,容易Overfitting,为了有效减少参数,给描述这两个类别的高斯分布相同的协方差矩阵,如下图所示:
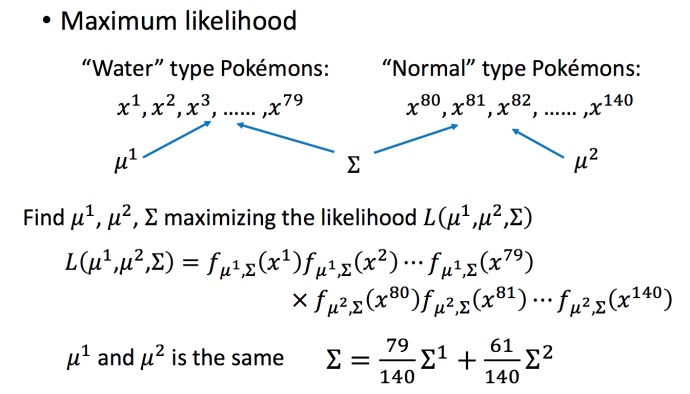
此时修改似然函数为 L(μ1,μ2,Σ)。μ1,μ2 计算方法和上面相同,分别加起来平均即可;而Σ的计算有所不同,∑=P(C1)∑1+P(C2)∑2
最终的分类结果为:
右图新的结果,分类的boundary是线性的,所以也将这种分类叫做 linear model。如果考虑所有的属性,发现正确率提高到了73%
4.Warning:数学推导
为什么当两个类别拥有相同的协方差矩阵的高斯分布时,分界线是一条直线呢?
将 P(C1|x)P(C1|x)整理,得到一个 σ(z)σ(z),这叫做Sigmoid function。如下图所示:

接下去一步一步推导出Z:




化简x的系数记做向量wT,后面3项结果都是标量,所以三个数字加起来记做b。最后P(C1|x)=σ(w⋅x+b)。从这个式子也可以看出上述当共用协方差矩阵的时候,为什么分界线是线性的。
Lecture 5: Logistic Regression
1.在Lecture 4中我们提到,当w、b取任意值的时候,P(C1|x)=σ(z)=σ(w⋅x+b)就构成了function set。
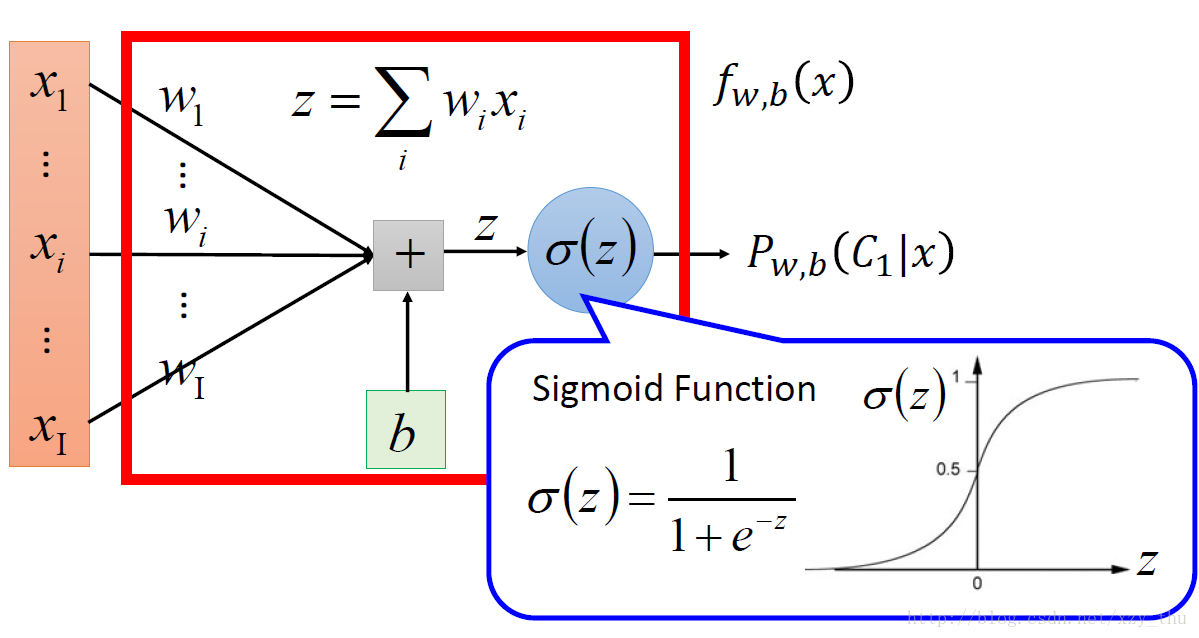
2.逻辑回归Logistic Regression与线性回归Linear Regression的区别
(1)Step1:选择model

(2)评价函数好坏((第二行等号右侧缺少一个负号) )

对训练数据(x1,C1)(x2,C1)(x3,C2)……用y^=1 表示C1,用y^=0表示C2。那么逻辑回归的似然函数可以表示为 :

最大化似然函数即是最小化交叉熵。交叉熵代表两个分布有多接近,若两个分布完全一样则交叉熵等于0。
逻辑回归Logistic Regression:评价function采用交叉熵损失
线性回归Linear Regression:评价function采用平方误差损失
(3) find the best function,都采用梯度下降
逻辑回归Logistic Regression与线性回归Linear Regression在用梯度下降法更新参数时公式相同。

3.Logistic Regression损失函数的选取
到目前为止,肯定很多人和我一样有个疑惑?为什么Logistic Regression用交叉熵损失而不用平方误差损失呢? 接下来就让我为你解惑:
如果用平方误差损失,在计算Logistic Regression损失函数对参数的微分时会出现如下情况:

上图充分表明了:在我们得出的结果far from target 时,微分很小。微分很小就代码的梯度下降变的很慢,甚至会出现错误。
为了更形象的说明问题,将交叉熵损失/平方误差损失与参数之间的关系画出来:
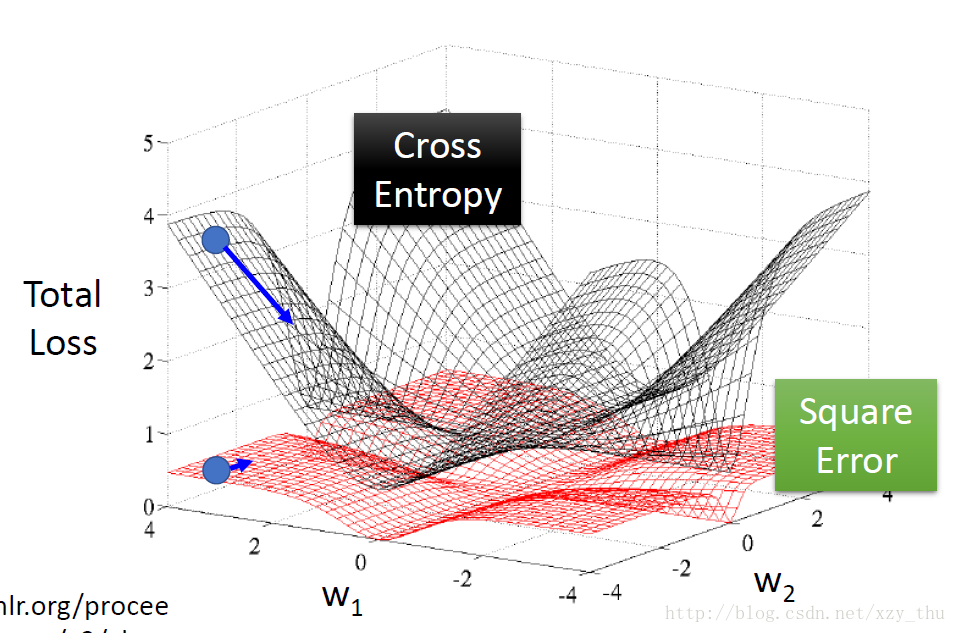
总结:
1.离目标远,cross entropy微分大,square error微分小。
2.离目标近,cross entropy微分小,square error微分小。
3.不管离目标远还是近,square error微分都小。所以微分小的时候,不知道离目标远还是近。
4.用cross entropy可以让training顺利很多。
4.Discriminative model(判别方法) VS Generative model(生成方法)
(1)通过这次学习,我们可以发现判别方法和生成方法的模型是一样的:
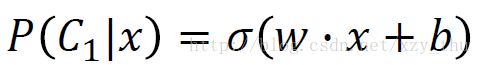
(2)区别在于:
判别方法,通过梯度下降,直接找到w,bw,b。
生成方法,通过估计N1,N2,μ1,μ2,∑ 来得到w,bw,b 。
那么问题来了,我们该如何选择模型呢?
同样的模型,同样的训练数据,采用两种方法所得结果(w,b)不同。因为生成方法对概率分布做了假设。 通常来说Discriminative model 比Generative model表现更好。下面看一个例子

我们能明显看出Testing Data应该属于class1,Discriminative model的结果也是class 1,然而朴素贝叶斯的结果是Class 2。
虽然生成模型的效果没有那么出色,那是不是生成模型就没有自己的优势呢?答案并不是。
(3)生成模型在一些情况下相对判别模型是有优势的:
1)、训练数据较少时。判别模型的表现受数据量影响较大,而生成模型受数据量影响较小。
2)、label有噪声时。生成模型的假设(“脑补”)反而可以把数据中的问题忽视掉。
3)、判别模型直接求后验概率,而生成模型将后验概率拆成先验和似然,而先验和似然可能来自不同来源。以语音识别(生成模型)为例,DNN只是其中一部分,还需要从大量文本(不需要语音)中计算一句话说出来的先验概率。
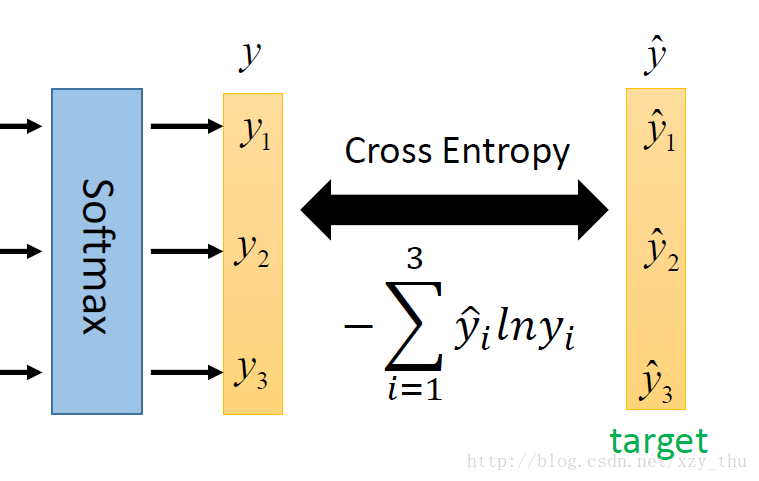
5.Multi-class Classification
在做Multi-class Classification时,需要softmax。原因可参考Bishop P209-210,或Google “maximum entropy”
6.到目前为止,我们了解的Logistic Regression是完美的,但它有没有局限性呢?答案是肯定有的,接下来让我们一起看看它的局限性。(说点题外话,在学到这的时候,我是非常佩服李宏毅老师,它完美的在此基础上引入了神经网络的概念!!!同时老师上课给的例子我觉得也是非常perfect)
(1)不能表示XOR。(边界是直线。)
解决方法:做feature transformation. (Not always easy to find a good transformation.)
希望机器自己找到 transformation:把多个Logistic Regression接起来。

一个Logistic Regression的input可以是其它Logistic Regression的output;一个Logistic Regression的output可以是其它Logistic Regression的input。这样,我们就完成了feature transformation。
如下图所示:
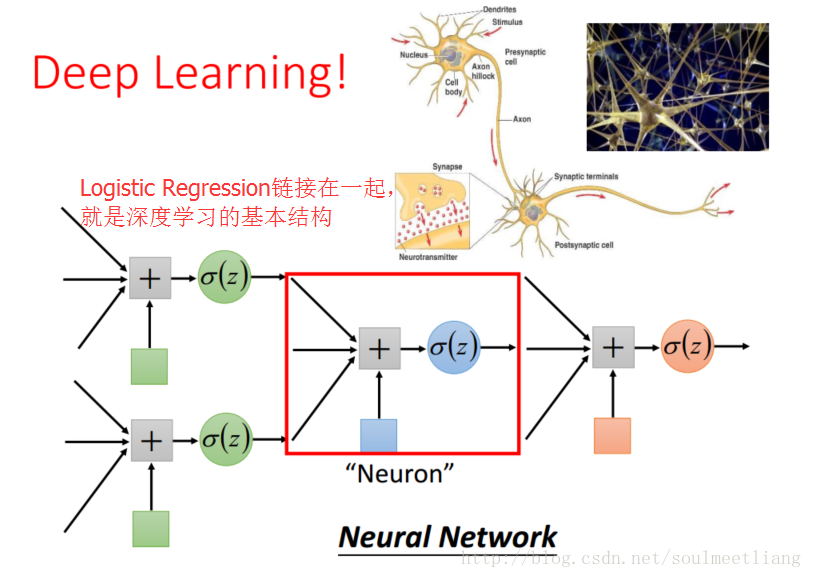
这样我们就得到了Neural Network,把其中每个Logistic Regression叫做一个Neuron.
参考:https://blog.csdn.net/zyq522376829/article/details/69216876
https://blog.csdn.net/xzy_thu/article/details/68067631
以上就是本节课的心得体会,欢迎交流!