在第七章我们学习了查找算法:
查找主要包括三种结构:①线性表 ②树表 ③哈希表
一、线性表:
| 顺序查找 | 折半查找 | 分块查找 | |
| 查找时间复杂度 | O(n) | O(log2n) | ASL = L查块 + L块内查找 |
| 特点 | 毫无特点 | 效率高一点点咯 | 甚至不如折半查找 |
| 通用情况 | 任何结构都行 | 有序的顺序表 | 块间有序、块内无序的顺序表 |
二、树表:
1.二叉排序树:平衡二叉树最好
2.B-树:是一种外存文件系统中常用的动态索引技术;
3.B+树:更适合做文件索引系统。严格来讲,它不属于第五章定义的树(其实我觉得有点像块内有序的分块查找)
三、哈希表(散列表):
1.术语介绍:
1)散列函数和散列地址:p = H(key) 对应关系(H);p(散列地址);关键字(key)
2)冲突和同义词:冲突现象;同义词是对于关键字而言的
2.散列函数的构造方法:
1)数字分析法的适用情况:明确知道所有关键字的每一位上各种数字的分布情况。
2)平方取中法:不能事先了解所有关键字的情况,或难于直接从关键字中找到取值较分散的几位。
3)折叠法:分为移位叠加和边界叠加。适用于散列地址位数较少,而关键字的位数较多,且难于直接从关键字中找到取值较分散的几位的情况。
3.处理冲突的方法:
1)开放地址法:线性探测法、二次探测法和伪随机探测法。缺点:会产生“二次聚集”现象。
2)链地址法:基本思想是构造一个邻接表一样的存储结构,把具有相同散列地址的关键字放在同一个单链表中(同义词链表),再把各个单链表的表头放到数组中。
4.平均查找长度(ASL):散列表的ASL是 α(裝填因子)的函数,而不是 n(记录个数)的函数。
在查找概率相等的前提下,直接计算查找成功的平均查找长度: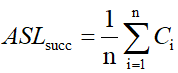
查找失败的平均查找长度: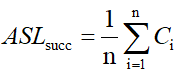
##---------------------------分割线--------------------------##
上次目标,在我的标准中达成了,上两周在树蛙的DDL压力下完成了一篇关于NLP的论文阅读以及关于这篇论文的演讲。
接下来的目标就是好好学习python的基础知识。另外、要在这两周构建这个学期关于DS的完整知识框架体系。