一 交叉验证
交叉验证的目的
在实际训练中,模型通常对训练数据好,但是对训练数据之外的数据拟合程度差。用于评价模型的泛化能力,从而进行模型选择。
交叉验证的基本思想
把在某种意义下将原始数据(dataset)进行分组,一部分做为训练集(train set),另一部分做为验证集(validation set or test set),首先用训练集对模型进行训练,再利用验证集来测试模型的泛化误差。另外,现实中数据总是有限的,为了对数据形成重用,从而提出k-折叠交叉验证。
对于个分类或回归问题,假设可选的模型为M={M1,M2,M3……Md}。k-折叠交叉验证就是将训练集的1/k作为测试集,每个模型训练k次,测试k次,错误率为k次的平均,最终选择平均率最小的模型Mi。
1、 将全部训练集S分成k个不相交的子集,假设S中的训练样例个数为m,那么每一个子集有m/k个训练样例,相应的子集称作{S1,S2,S3……Sk}。
2、 每次从模型集合M中拿出来一个Mi,然后在训练子集中选择出k-1个
{S1,S2,Sj-1,Sj+1,Sk}(也就是每次只留下一个Sj),使用这k-1个子集训练Mi后,得到假设函数hij。最后使用剩下的一份Sj作测试,得到经验错误。
3、 由于我们每次留下一个Sj(j从1到k),因此会得到k个经验错误,那么对于一个Mi,它的经验错误是这k个经验错误的平均。
4、 选出平均经验错误率最小的Mi,然后使用全部的S再做一次训练,得到最后的hi。
K折交叉验证
- 将数据集平均分割成K个等份
- 使用1份数据作为测试数据,其余作为训练数据
- 计算测试准确率
- 使用不同的测试集,重复2、3步骤
- 对测试准确率做平均,作为对未知数据预测准确率的估计
网格搜索GridSearchCV
GridSearchCV用于系统地遍历多种参数组合,通过交叉验证确定最佳效果参数。
classsklearn.model_selection.GridSearchCV(estimator,param_grid, scoring=None, fit_params=None, n_jobs=1, iid=True, refit=True,cv=None, verbose=0, pre_dispatch='2*n_jobs', error_score='raise',return_train_score=True)常用参数解读
estimator:所使用的分类器,如estimator=RandomForestClassifier(min_samples_split=100, min_samples_leaf=20, max_depth=8, max_features='sqrt', random_state=10) 并且传入除需要确定最佳的参数之外的其他参数。每一个分类器都需要一个scoring参数,或者score方法。
param_grid:值为字典或者列表,即需要最优化的参数的取值,param_item = {'n_estimators':range(10,71,10)} param_grid =param_item
scoring :准确度评价标准,默认None,这时需要使用score函数;或者如scoring=’roc_auc’,根据所选模型不同,评价准则不同。字符串(函数名),或是可调用对象,需要其函数签名形如:scorer(estimator, X, y);如果是None,则使用estimator的误差估计函数。
cv :交叉验证参数,默认None,使用三折交叉验证。指定fold数量,默认为3,也可以是yield训练/测试数据的生成器。
refit :默认为True,程序将会以交叉验证训练集得到的最佳参数,重新对所有可用的训练集与开发集进行,作为最终用于性能评估的最佳模型参数。即在搜索参数结束后,用最佳参数结果再次fit一遍全部数据集。
iid:默认True,为True时,默认为各个样本fold概率分布一致,误差估计为所有样本之和,而非各个fold的平均。
verbose:日志冗长度,int:冗长度,0:不输出训练过程,1:偶尔输出,>1:对每个子模型都输出。
n_jobs: 并行数,int:个数,-1:跟CPU核数一致, 1:默认值。
pre_dispatch:指定总共分发的并行任务数。当n_jobs大于1时,数据将在每个运行点进行复制,这可能导致OOM,而设置pre_dispatch参数,则可以预先划分总共的job数量,使数据最多被复制pre_dispatch次
随机参数优化RandomizedSearchCV
尽管使用参数设置的网格法是目前最广泛使用的参数优化方法, 其他搜索方法也具有更有利的性能。 RandomizedSearchCV 实现了对参数的随机搜索, 其中每个设置都是从可能的参数值的分布中进行取样。 这对于穷举搜索有两个主要优势:
- 可以选择独立于参数个数和可能值的预算
- 添加不影响性能的参数不会降低效率
指定如何取样的参数是使用字典完成的, 非常类似于为 GridSearchCV 指定参数。 此外, 通过 n_iter 参数指定计算预算, 即取样候选项数或取样迭代次数。 对于每个参数, 可以指定在可能值上的分布或离散选择的列表 (均匀取样):
{'C': scipy.stats.expon(scale=100), 'gamma': scipy.stats.expon(scale=.1),
'kernel': ['rbf'], 'class_weight':['balanced', None]}搜索的输出值
cv_results_:给出不同参数情况下的评价结果的记录
best_params_:描述了已取得最佳结果的参数的组合
best_score_:成员提供优化过程期间观察到的最好的评分
from sklearn.datasets import load_iris # 自带的样本数据集
from sklearn.neighbors import KNeighborsClassifier # 要估计的是knn里面的参数,包括k的取值和样本权重分布方式
import matplotlib.pyplot as plt # 可视化绘图
from sklearn.model_selection import GridSearchCV,RandomizedSearchCV # 网格搜索和随机搜索
iris = load_iris()
X = iris.data # 150个样本,4个属性
y = iris.target # 150个类标号
#######################################################
k_range = range(1, 30) # 优化参数k的取值范围
weight_options = ['uniform', 'distance'] # 代估参数权重的取值范围。uniform为统一取权值,distance表示距离倒数取权值
# 下面是构建parameter grid,其结构是key为参数名称,value是待搜索的数值列表的一个字典结构
params = {'n_neighbors':k_range,'weights':weight_options} # 定义优化参数字典,字典中的key值必须是分类算法的函数的参数名
knn = KNeighborsClassifier(n_neighbors=5) # 定义分类算法。n_neighbors和weights的参数名称和params字典中的key名对应
# ================================网格搜索=======================================
# 这里GridSearchCV的参数形式和cross_val_score的形式差不多,其中params是 parameter grid所对应的参数
# GridSearchCV中的n_jobs设置为-1时,可以实现并行计算(如果你的电脑支持的情况下)
grid = GridSearchCV(estimator = knn, param_grid = params, cv=10, scoring='accuracy') #针对每个参数对进行了10次交叉验证。scoring='accuracy'使用准确率为结果的度量指标。可以添加多个度量指标
grid.fit(X, y)
#print('网格搜索-度量记录:',grid.cv_results_) # 包含每次训练的相关信息
print('网格搜索-最佳度量值:',grid.best_score_) # 获取最佳度量值
print('网格搜索-最佳参数:',grid.best_params_) # 获取最佳度量值时的代定参数的值。是一个字典
print('网格搜索-最佳模型:',grid.best_estimator_) # 获取最佳度量时的分类器模型
# 使用获取的最佳参数生成模型,预测数据
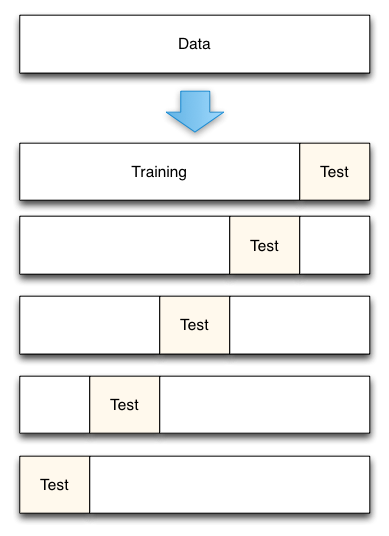
knn_grid = KNeighborsClassifier(n_neighbors=grid.best_params_['n_neighbors'], weights=grid.best_params_['weights']) # 取出最佳参数进行建模
knn_grid.fit(X, y) # 训练模型
print(knn_grid.predict([[3, 5, 4, 2]])) # 预测新对象

# =====================================随机搜索===========================================
rand = RandomizedSearchCV(knn, params, cv=10, scoring='accuracy', n_iter=10, random_state=5) #
rand.fit(X, y)
#print('随机搜索-度量记录:',grid.cv_results_) # 包含每次训练的相关信息
print('随机搜索-最佳度量值:',grid.best_score_) # 获取最佳度量值
print('随机搜索-最佳参数:',grid.best_params_) # 获取最佳度量值时的代定参数的值。是一个字典
print('随机搜索-最佳模型:',grid.best_estimator_) # 获取最佳度量时的分类器模型
# 使用获取的最佳参数生成模型,预测数据
knn_random = KNeighborsClassifier(n_neighbors=grid.best_params_['n_neighbors'], weights=grid.best_params_['weights']) # 取出最佳参数进行建模
knn_random.fit(X, y) # 训练模型
print(knn_random.predict([[3, 5, 4, 2]])) # 预测新对象
当你的调节参数是连续的,比如回归问题的正则化参数,有必要指定一个连续分布而不是可能值的列表,这样RandomizeSearchCV就可以执行更好的grid search。
调参神器hyperopt
http://hyperopt.github.io/hyperopt-sklearn/
Hyperopt库为python中的模型选择和参数优化提供了算法和并行方案。机器学习常见的模型有KNN, SVM,PCA,决策树,GBDT等一系列的算法,但是在实际应用中,我们需要选取合适的模型,并对模型调参,得到一组合适的参数。尤其是在模型的调参阶段,需要花费大量的时间和精力,却又效率低下。但是我们可以换一个角度来看待这个问题,模型的选取,以及模型中需要调节的参数,可以看做是一组变量,模型的质量标准(比如正确率,AUC)等等可以看做是目标函数,这个问题就是超参数的优化的问题。我们可以使用搜索算法来解决。
如果我们要确定某个算法模型的最佳参数,通常会使用网格搜索(GridSearch),即假如有两个参数A和B,它们分别有NA和NB个取值(人为设定),那么我们则需要依次枚举这些取值的所有组合情况(在这里是共NA∗NB
种),然后取准确率最高的那一个作为最终这个算法模型的最优参数。
显然,如果要枚举的组合情况非常多,网格搜索将变得十分低效,甚至不可接受。那么本文要介绍的hyperopt可以理解为一个智能化的网格搜索,能大大缩短调参所需的时间。
#!/usr/bin/env python
# encoding: utf-8
"""
@version: v1.0
@author: zwqjoy
@contact: zwqjoy@163.com
@site: https://blog.csdn.net/zwqjoy
@file: para
@time: 2018/7/7 17:00
"""
from hyperopt import fmin, tpe, hp, rand
import numpy as np
from sklearn.metrics import accuracy_score
from sklearn import svm
from sklearn import datasets
# SVM的三个超参数:C为惩罚因子,kernel为核函数类型,gamma为核函数的额外参数(对于不同类型的核函数有不同的含义)
# 有别于传统的网格搜索(GridSearch),这里只需要给出最优参数的概率分布即可,而不需要按照步长把具体的值给一个个枚举出来
parameter_space_svc ={
# loguniform表示该参数取对数后符合均匀分布
'C':hp.loguniform("C", np.log(1), np.log(100)),
'kernel':hp.choice('kernel',['rbf','poly']),
'gamma': hp.loguniform("gamma", np.log(0.001), np.log(0.1)),
}
# 鸢尾花卉数据集,是一类多重变量分析的数据集
# 通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类
iris = datasets.load_digits()
#--------------------划分训练集和测试集--------------------
train_data = iris.data[0:1300]
train_target = iris.target[0:1300]
test_data = iris.data[1300:-1]
test_target = iris.target[1300:-1]
#-----------------------------------------------------------
# 计数器,每一次参数组合的枚举都会使它加1
count = 0
def function(args):
print(args)
# **可以把dict转换为关键字参数,可以大大简化复杂的函数调用
clf = svm.SVC(**args)
# 训练模型
clf.fit(train_data,train_target)
# 预测测试集
prediction = clf.predict(test_data)
global count
count = count + 1
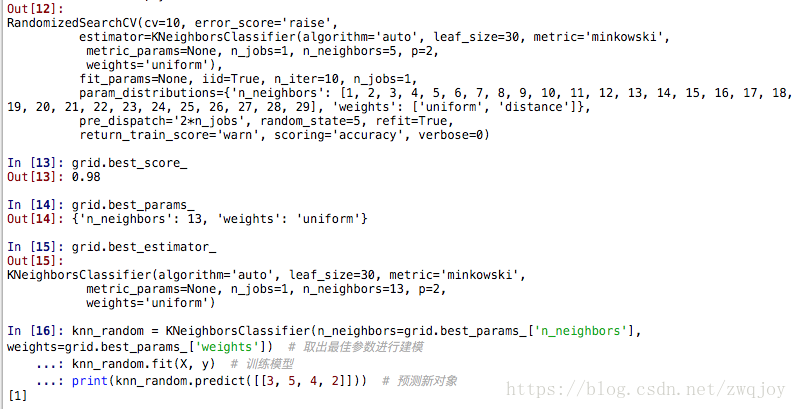
score = accuracy_score(test_target,prediction)
print("[{0}], Test acc: {1})".format(str(count), score))
# 由于hyperopt仅提供fmin接口,因此如果要求最大值,则需要取相反数
return -score
# algo指定搜索算法,目前支持以下算法:
# ①随机搜索(hyperopt.rand.suggest)
# ②模拟退火(hyperopt.anneal.suggest)
# ③TPE算法(hyperopt.tpe.suggest,算法全称为Tree-structured Parzen Estimator Approach)
# max_evals指定枚举次数上限,即使第max_evals次枚举仍未能确定全局最优解,也要结束搜索,返回目前搜索到的最优解
best = fmin(function, parameter_space_svc, algo=tpe.suggest, max_evals=100)
# best["kernel"]返回的是数组下标,因此需要把它还原回来
kernel_list = ['rbf','poly']
best["kernel"] = kernel_list[best["kernel"]]
print("best params: ",best)
clf = svm.SVC(**best)
print(clf)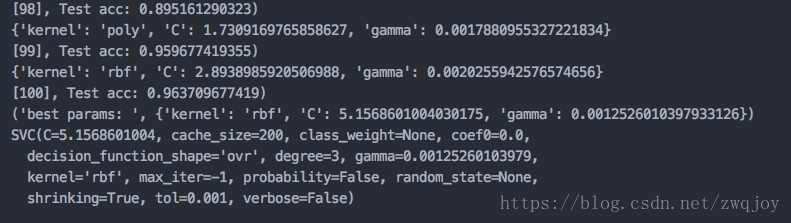
注意:
tuning with Hyperopt- TypeError: 'generator' object has no attribute '__getitem__'
The issue is incompatibility of Hyperopt with networkxx2. One needs to downgrade to "networkx 1.11". (pip intall networkx==1.11)
参考: