R-CNN系列核心思想简单记录
1. R-CNN
R-CNN系列的开山之作,思想很重要。
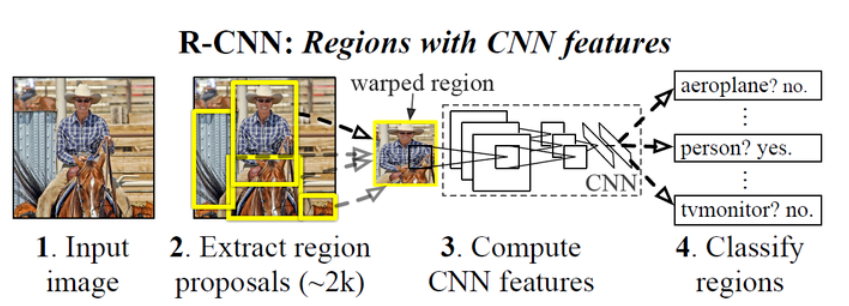
- 输入一张图像
- 提取一定数量的候选框
- 将候选框变形到固定的尺寸
- 将变形后的候选框送入CNN进行提特征
- 将特征送入SVM进行分类
- 将特征送入回归器进行回归BBox
如何提取2000个候选框?
用Selective search算法选取,兼顾各个尺度。下面这个算法图说的很清楚,其中初始化方法另一篇论文有说。

如何变形到固定尺寸?
原论文里有比较了几种方式,采用了不考虑图像原始比率,变形到给定的固定的尺寸的办法。
如何训练?
CNN提特征的网络,先用ImageNet预训练,然后在目标数据集微调,输出21个类别(20物体+1背景)。然后再用训练好的CNN去提特征训练SVM分类器和回归器。
关于CNN和SVM训练样本的问题
CNN把和GT(Ground Truth)IoU >=0.5的数据作为正样本,IoU < 0.5的作为负样本(背景)。而SVM在训练的时候,用IoU < 0.3的数据作为负样本,GT作为正样本,其他的区间内的数据直接忽略不使用。
关于去除重复的候选框
NMS,非极大值抑制,核心思想是,在一个局部极值的邻域内,将某个指标足够大的区域剔除,只保留当前的极值区域。因为极值区域就足够代表当前这个邻域的特征了。
2. Fast R-CNN
改进R-CNN,主要在候选区域提特征,和多任务训练这里。
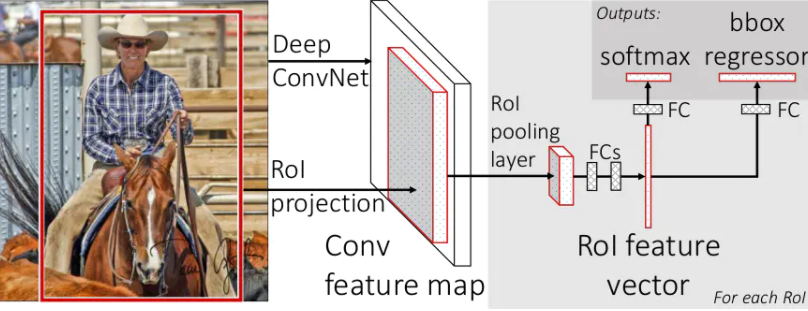
- 输入一张图像
- 提取一定数量的候选框
- 将候选框区域映射到最后的featureMap上,提取对应的feature(每次尺寸都不一致)。
- 采用ROI pooling,就是将不同尺寸的feature划分成相同尺寸的网格,然后没有网格内取最大值,所以不同尺寸的feature可以统一变换到相同的尺寸。
- 将特征向量经过全连接层进行分类、回归。
RoI pooling?
就是类似传统CV的划分区域的思想,虽然size各不相同,但是我都平均划分成一样的区域网格,最后得到的feature vector都是一样的,便于后续网络的训练。
ROI projection?
本质上图像变成featuremap后,featuremap和原始图像的对应关系还是可以找到,所以可以在featuremap上找到和候选框对应的区域,然后选取这块区域进行后续的计算。
Multi-Task?
将分类和回归放在一起进行,可以证明,提高了准确率,可以说相互促进吧。
相比于R-CNN
- 减少了CNN训练时的冗余,原来是一张图分成多个区域,每个区域从头进入CNN训练,现在是图片先进入CNN得到featuremap,然后在featuremap上用候选框选择特征然后进行计算。
- 将分类和回归整合在一起训练,不用分开训练。
- 还有SVD分解的小贡献,提升速度,也不算核心的贡献。
3. Faster R-CNN
继续改进Fast R-CNN,候选框提取依然很慢(Selective Search),Faster R-CNN对候选框选取这里进行优化。主要提出了RPN (Region Proposal Network)网络,用来提取候选框。
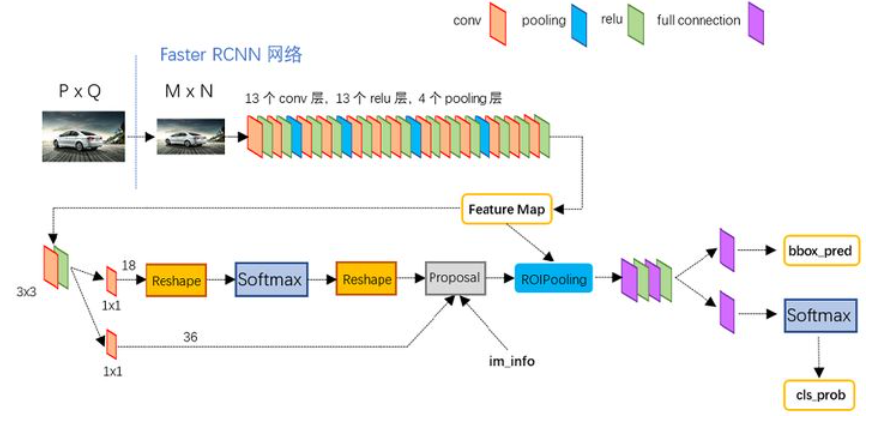
- 输入一张图像
- 经过CNN提取特征
- 对于特征,每个位置对应9种不同的Anchor(候选框,尺寸人为提前规定)。
- 对每个候选框进行分类和回归BBox,最后得出候选框。
- 有了featuremap和候选框,后面就和Fast R-CNN一样了。
RPN?
核心贡献,将候选框的选择和加入到网络的训练中,认为规定的Anchor基本可以覆盖大多数目标。
相比于Faster R-CNN?
提升了速度和准确度,可以end to end训练。
4. Mask R-CNN
对Faster R-CNN改进,可以进行实例分割任务,而且改动很简单,主要是更换了ROI Pooling->ROI Align,以及增了一个分割的任务。

- Faster R-CNN 的步骤,提取feature map和候选框,其中ROI Pooling更换成了ROI Align。
- 后面,除了分类和回归,还额外增加了几层网络,用来输出Mask。
ROI Align?
ROI Pooling在划分网格的时候,不是均匀的划分的,就是可能有的子区域大,有的小,但是最终都被一个数值来表示,例如3x3被pool成一个最大值,而2x2的区域也被pool成一个值,这样可能让feature产生了偏移。ROI Algin采用插值的思想,均匀的划分,然后用插值来得到最后的值,可以缓解ROI Align的问题。