GitHub:https://github.com/google/automl/tree/master/efficientdet
摘要
本文提出了双向的特征金字塔网络,合理调整网络的深度和宽度。单模型单尺度,EfficientDet D7在COCO 就能达到52.2AP 仅用52M的参数量,比之前检测器小4~9倍。
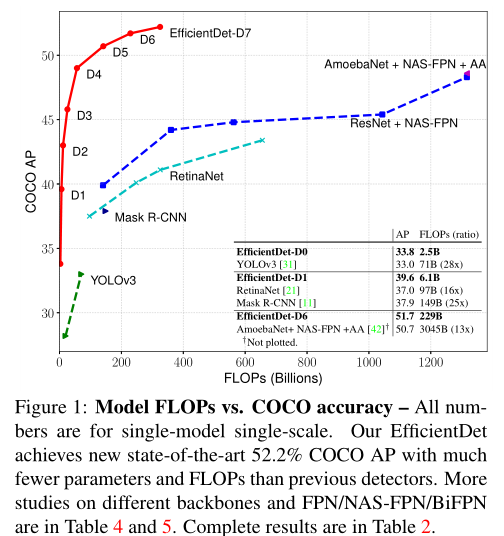
1.Introduction:
使检测网络更有效的一些方法:
(1)单阶段
(2)Anchor free:
Cornernet: Detecting objects as paired keypoints. ECCV, 2019
Fcos: Fully convolutional one-stage object detection. ICCV, 2019.
Objects as points.
(3)压缩现有的模型:
Rethinking the value of network pruning(ICLR2019).
Yolo-lite: a real-time object detection algorithm optimized for non-gpu computers
本文指出目前有两个难点:
1、有效的多尺度特征融合:继FPN后,陆续有PANet ,NAS-FPN
2、model scaling:依赖更大的backbone,或者更大图像大小输入。
3、Related Work
多尺度特征表示
(1)传统的自顶向下的FPN仅有单向的信息流动,(2)PANet增加了额外的自底向上的跨尺度的连接,
(3)M2Det使用了U型的结构 (4)G-FRNet 引入gate单元控制特征之间的信息流
(5)NAS-FPN 则是使用了神经网络结构搜索 (6)BiFPN双向特征金字塔
多尺度特征融合就是要将不同分辨率大小的特征图进行融合
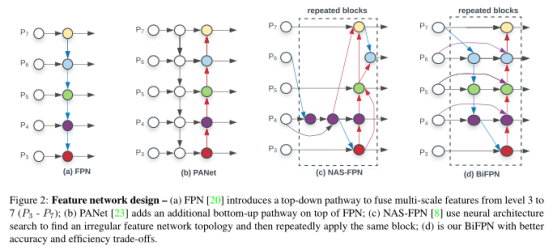
********************BiFPN的改进点*************************
(1) 从figure2 可以看出移除了只有一个输入的节点,这是因为单一输入的节点不存在特征融合所以对特征网络的贡献很小;
(2)相对于PANet 同一级的特征融合又增加了原始的特征,这样子就能加入更多的特征且不增加过多计算量;
(3)将top-down +bottom-up视作是一层,多次进行操作。
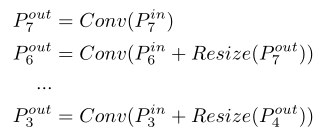
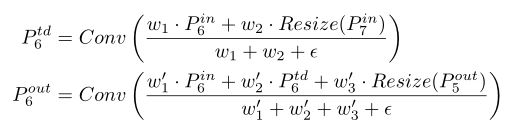
左边是传统的FPN; 右边是BiFPN的公式(td就是top-down)
权重控制的特征融合:
一种方法是直接resize到相同大小的特征图做sum操作,但不同输入特征对输出特征的贡献是不同的,所以本文让网络学习不同特征的重要性
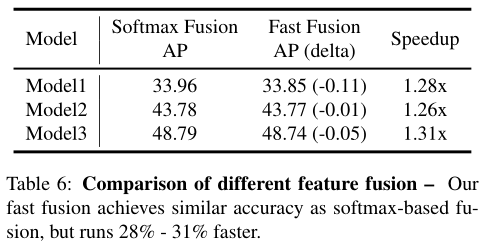
基于Softmax的融合:一种直观的idea是对没一个权重使用softmax,这样所有权重都标准化到-~1之间,但是softmax在GPU硬件上明显,我们需要一种更快捷的融合方法

快速的标准化融合:
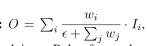
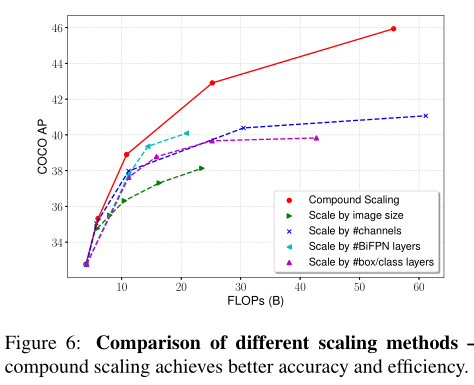
Compound scaling
目标检测比图像分类有更多的维度: 双向FPN的深度和宽度 ,回归分类网络(box/class network),图像输入分辨率大小(Image Resolution)
Backbone:
使用了efficientNet B0-B6 这样能够使用ImageNet的预训练模型
BiFPN:
对于深度使用线性增长的方式,宽度使用指数增长:
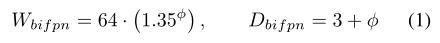
分类/边框回归网络宽度(通道数)设置和BiFPN的宽度相同,层数设置如下:
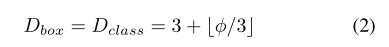
Image Resolution:因为使用的是level3-7的特征所以输入的分辨率要能被128整除:
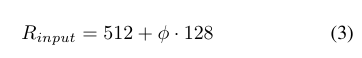
4、 Experiment
COCO 1.18万张图训练集,测试分别用了有公开GT的val验证集和无公开GT的test-devce
Weight decay设为5e-4 ,训练时学习率在第一个epoch从0线性增长到.0.16然后cosine下降。 每个模型训练300epoch,anchor ratio={0.5,1,2}
Table2. EfficientDet D0-D7
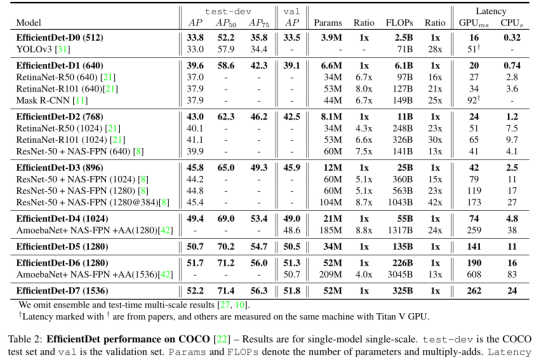
Table3 在Pascal VOC的语义分割的效果,目标检测用的特征是{P3-P7},,语义分割就是用P2-P7,

5 Ablation study
5.1 、Backbone和bifpn的有效性,使用更少的参数和运算量还能有4AP提升

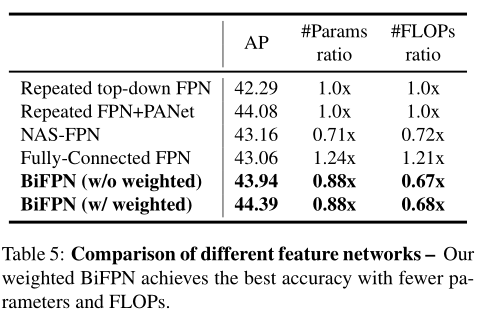
5.2、Table5 是模型的精度和复杂性。 为了公平对比 FPN PANet里都用深度可分离卷积
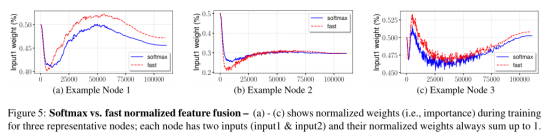
5.3、Fast normalized的方法可以快1.26到1.31倍且精度相近。训练过程中 fast的方法权重变化的比softmax要快
结论:
Compound scaling使用了一个系数同步的调节网络的各个维度参数。 其他都是单独只调一个维度,可以看出相同的运算量下,同时调各个维度效果最佳