本文翻译自官网:https://flink.apache.org/news/2020/02/11/release-1.10.0.html
11 Feb 2020 Marta Paes (@morsapaes)
Apache Flink 社区很激动的表示 Flink 的版本达到2位数,并宣布发布 Flink 1.10.0!这是迄今为止最大社区努力的结果,有超过 1.2 K 个 issues 被合并和超过 200 位的贡献者,此版本对Flink任务的整体性能和稳定性都进行了重大改进,原生 Kubernetes 集成的预览和 Python 支持(PyFlink)的巨大进步。
Flink 1.10 也标志着完成 Blink 的集成,通过生产就绪的Hive集成和TPC-DS覆盖,强化 StreamingSQL并将成熟的批处理引入Flink。这篇博客文章描述了所有主要的新功能和改进,需要注意的重要更改以及预期的发展方向。
- New Features(新功能) and Improvements(改进)
- Improved Memory Management and Configuration(已改善的内存管理和配置)
- Unified Logic for Job Submission(任务提交的统一逻辑)
- Native Kubernetes Integration (Beta)(原生 Kubemetes 集成)
- Table API/SQL: Production-ready Hive Integration(生成就绪的 Hive 集成)
- Other Improvements to the Table API/SQL(Table API/SQL 的其他提高)
- PyFlink: Support for Native User Defined Functions (UDFs)(支持用户定义的函数)
- Important Changes(重要变化)
- Release Notes
- List of Contributorss
现在可以在Flink网站下载页面上找到二进制分发版和源码包。更多细节,请查看完整的 realease changelog 和 已更新的文档。我们鼓励你下载 Flink 1.10.0 的 release 包和通过邮件列表和 JIRA 分享您的反馈。
New Features and Improvements(新功能和改进)
Improved Memory Management and Configuration(已改善的内存管理和配置)
当前 Flink 的 TaskExecutor 内存配置存在一些缺陷使得难以推理(about)或优化资源利用(make it hard to reason about or optimize resource utilization),例如:
- 流和批处理执行中用于内存占用的不同配置模型
- 流执行中复杂且取决于用户的堆外状态后端(即RocksDB)配置
使内存选项对用户更明确和直观,Flink 1.10 引进 TaskExecutor 内存模型和配置逻辑的重大改变 (FLIP-49)。这些改变让 Flink 更适合各种各样的部署环境(例如:Kubernetes, Yarn, Mesos),让用户严格控制其内存消耗。
Managed Memory Extension(管理内存扩展)
扩展了托管内存,以解决RocksDBStateBackend的内存使用问题。然而批处理任务可以使用on-heap(堆内) 或 off-heap(堆外) 内存,RocksDBStateBackend 的流处理任务只能使用 off-heap 内存。因此,为了让用户在流处理和批处理执行直接切换,而不修改集群配置,托管内存现在始终处于 off-heap 状态。
Simplified RocksDB Configuration(简化 RocksDB 配置)
配置 off-heap 的状态后端如RocksDB 曾经需要大量的手动调整,如减少 JVM 堆内存大小 或 设置 Flink 使用 off-heap 内存。现在可以通过 Flink 的现成配置来实现,调整 RocksDBStateBackend 的内存预算就像调整托管内存大小的一样简单。
另一个重要的改进是允许Flink 绑定 RocksDB的内存使用(FLINK-7289),防止其超出总内存预算——这在Kubernetes等容器化环境中尤其重要(注:kubernetes容器内存超出会被kill)。有关如何启用和调整此功能的详细信息,参考Tuning RocksDB。
注意:FLIP-49 改变了集群资源配置过程,这可能需要调整群集以从以前的Flink版本进行升级,有关引入的更改和调整指南的全面概述,参考此设置。
Unified Logic for Job Submission(任务提交的统一逻辑)
这次发布之前,任务提交是执行环境(Execution Environments)职责的一部分并与不同的部署目标紧密联系 (e.g. Yarn, Kubernetes, Mesos)。这导致关注点分离不佳,并且随着时间的流逝,越来越多的用户需要单独配置和管理的定制环境。
在 Flink 1.10,作业提交逻辑被抽象到通用的Executor接口中 (FLIP-73).。ExecutorCLI(FLIP-81)的添加引入了一种统一的方式来为任何执行目标指定配置参数。为了完成这项工作,结果检索的过程也与作业提交脱钩,引入了负责获取JobExecutionResult的JobClient(FLINK-74)。
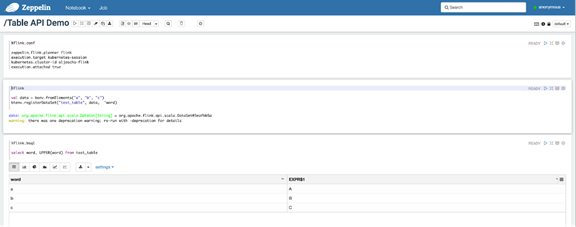
总之,这些改变让在下游框架中以编程的方式使用 Flink 变得更加容易—例如:Apache Beam或Zeppelin交互式笔记本—通过为用户提供Flink的统一入口点。对应跨多个模板环境使用 Flink 的用户,过渡到基于配置的执行过程还大大减少了样板代码和可维护性开销。
Native Kubernetes Integration (Beta)(原生的Kubernetes 集成)
对于希望在容器化环境上开始使用 Flink 的用户,在Kubernetes之上部署和管理独立集群需要一些有关容器,操作和特定于环境的工具(如kubectl)的前期知识。
在Flink 1.10中,我们推出了Active Kubernetes集成(FLINK-9953)的第一阶段,该阶段支持会话集群(with per-job planned)。 在这种情况下,“active”表示 Flink 的ResourceManager(K8sResMngr)与Kubernetes进行本地通信以按需分配新的Pod,类似于Flink的Yarn和Mesos集成。 用户还可以利用命名空间为聚合资源消耗有限的多租户环境启动Flink集群。 事先配置具有足够权限的RBAC角色和服务帐户。
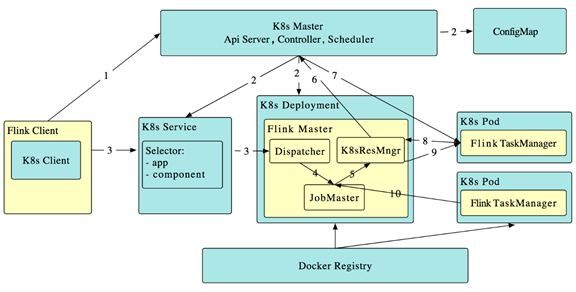
就像引入任务提交的统一逻辑一样,在 Flink 1.10的所有命令行选项都映射成统一的配置。因为这个原因,用户可以简单地参考Kubernetes配置选项,然后使用CLI在Kubernetes上将作业提交到现有的Flink会话(users can simply refer to the Kubernetes config options and submit a job to an existing Flink session on Kubernetes in the CLI using)。
./bin/flink run -d -e kubernetes-session -Dkubernetes.cluster-id=<ClusterId> examples/streaming/WindowJoin.jar
如果你想尝试这个预览的分支,我们鼓励你通过这个 原生的 Kubernetes 设定,尝试它并且向社区分享您的反馈。
Table API/SQL: Production-ready Hive Integration(生产就绪的 Hive 集成)
在 Flink 1.9 中 Hive 集成发布为预览分支。Flink 1.9 版本允许用户使用 SQL DDL 持久化 Flink-specific 元数据 (e.g. Kafka tables) 到 Hive元数据库,调用在Hive 中定义的UDFs,和使用 Flink 读和写 Hive 表,Flink 1.10通过进一步的发展完善了这项工作,将与生产就绪的Hive集成到Flink,并与大多数Hive版本 完全兼容。
Native Partition Support for Batch SQL(批处理SQL的本地(Native)分区支持)
到目前为止,只支持写到非分区的 Hive 表。在 Flink 1.10,Flink SQL语法已通过INSERT OVERWRITE和PARTITION(FLIP-63)进行了扩展,使用户能写到Hive 的静态和动态分区表。
Static Partition Writing
INSERT { INTO | OVERWRITE } TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement;
Dynamic Partition Writing
INSERT { INTO | OVERWRITE } TABLE tablename1 select_statement1 FROM from_statement;
完全支持的分区表使用户可以利用读取时的分区修剪功能,通过减少需要扫描的数据量来显着提高这些操作的性能。
Further Optimizations(进一步优化)
除了分区修剪,Flink 1.10 在 Hive 集成中引入了更多读优化,例如:
- Projection pushdown:Flink利用投影下推功能,通过从表扫描中删除不必要的字段来最大程度地减少Flink和Hive表之间的数据传输。这对有很多字段的表很有效。
- · LIMIT pushdown:对应有 LIMIT 的查询语句,Flink将尽可能限制输出记录的数量,以最大程度地减少通过网络传输的数据量。
- ORC Vectorization on Read:为了提升ORC文件的读取性能,Flink现在默认使用本机ORC矢量化阅读器用于2.0.0或更高版本的Hive版本以及具有非复杂数据类型的列。
Pluggable Modules as Flink System Objects (Beta)(可插拔模块作为Flink系统对象)
Flink 1.10为Flink表核心中的可插入模块引入了一种通用机制,首先关注系统功能(FLIP-68)。使用模块,用户可以扩展Flink的系统对象—例如使用Hive 内置函数就像Flink 系统函数。此版本附带一个预先实现的HiveModule,支持多个Hive版本,但用户也可以编写自己的可插拔模块。
Other Improvements to the Table API/SQL
Watermarks and Computed Columns in SQL DDL(SQL DDL中的水印和计算列)
Flink 1.10支持特定于流的语法扩展,以在Flink SQL DDL中定义时间属性和水印生成 (FLIP-66)。这允许基于时间的算子,比如窗口,以及在使用DDL语句创建的表上定义水印策略。
CREATE TABLE table_name ( WATERMARK FOR columnName AS <watermark_strategy_expression> ) WITH ( ... )
Additional Extensions to SQL DDL(SQL DDL的其他扩展)
现在,临时/持久功能与系统/catalog 功能(FLIP-57)之间有明显的区别。 这不仅消除了函数引用中的歧义,而且允许确定性的函数解析顺序(即,在命名冲突的情况下,系统函数将在catalog 函数之前,而临时函数在这两个维度上都将优先于持久函数)。
遵循FLIP-57的基础知识,我们扩展了SQL DDL语法以支持目录功能,临时功能和临时系统功能(FLIP-79)的创建:
CREATE [TEMPORARY|TEMPORARY SYSTEM] FUNCTION [IF NOT EXISTS] [catalog_name.][db_name.]function_name AS identifier [LANGUAGE JAVA|SCALA]
有关Flink SQL中DDL支持的当前状态的完整概述,请查看更新的文档。
注意:为了将来正确处理并保证跨元对象(表,视图,函数)的行为一致,不推荐使用Table API中的某些对象声明方法,而推荐使用更接近标准SQL DDL的方法(FLIP-64)。
Full TPC-DS Coverage for Batch
TPC-DS是一种广泛使用的行业标准决策支持基准,用于评估和衡量基于SQL的数据处理引擎的性能。 在Flink 1.10中,所有TPC-DS查询均受端到端支持(FLINK-11491),反映了其SQL引擎已准备就绪,可以满足类似现代数据仓库的工作负载的需求。
PyFlink: Support for Native User Defined Functions (UDFs)
在以前的版本中引入了PyFlink的预览版,朝着Flink中全面支持Python的目标迈进了一步。 对于此发行版,重点是使用户能够在Table API / SQL(FLIP-58)中注册和使用Python用户定义的函数(UDF,已计划UDTF / UDAF)。

如果您对基础实现感兴趣(利用Apache Beam的可移植性框架),请参考FLIP-58的“架构”部分,也请参考FLIP-78。 这些数据结构为Pandas支持和PyFlink最终到达DataStream API奠定了必要的基础。
从Flink 1.10开始,用户还可以使用以下方法通过pip轻松安装PyFlink:
pip install apache-flink
有关PyFlink计划进行的其他改进的预览,请查看FLINK-14500并参与有关所需用户功能的讨论。
Important Changes
- [FLINK-10725] Flink Java 11 编译和运行.
- [FLINK-15495] Blink planner 现在是默认的 SQL Client, 这样用户就可以从所有最新功能和改进中受益。 还计划在下一个版本中使用Table API中 old planner的切换,因此我们建议用户开始熟悉Blink planner。.
- [FLINK-13025] There is a new Elasticsearch sink connector, fully supporting Elasticsearch 7.x versions.
- [FLINK-15115] Kafka 0.8和0.9的连接器已标记为不推荐使用,将不再得到积极支持。 如果您仍在使用这些版本或有任何其他相关问题,请联系@dev邮件列表.
- [FLINK-14516] 与配置选项taskmanager.network.credit.model一起删除了非基于信用的网络流控制代码。 展望未来,Flink将始终使用基于信用的流量控制.
- [FLINK-12122] FLIP-6在Flink 1.5.0中推出,并引入了与TaskManagers分配 slot 方式有关的代码回归。 要使用更接近FLIP之前行为的调度策略(Flink尝试将工作负载分散到所有当前可用的TaskManager中),用户可以在flink-conf.yaml中设置cluster.evenly-spread-out-slots:true。.
- [FLINK-11956]
s3-hadoop和s3-presto文件系统不再使用类重定位,而应通过插件加载,但现在可以与所有凭据提供程序无缝集成。强烈建议将其他文件系统仅用作插件,因为我们将继续删除重定位. - Flink 1.9附带了重构的Web UI,保留了旧版的UI,以备不时之需。 到目前为止,尚未报告任何问题,因此社区投票决定放弃Flink 1.10中的旧版Web UI。.
Release Notes
如果您打算将设置升级到Flink 1.10,请仔细查看发行说明,以获取详细的更改和新功能列表。 该版本与以前的1.x版本的API兼容,这些版本的API使用@Public注释进行了注释。
List of Contributors
The Apache Flink community would like to thank all contributors that have made this release possible:
Achyuth Samudrala, Aitozi, Alberto Romero, Alec.Ch, Aleksey Pak, Alexander Fedulov, Alice Yan, Aljoscha Krettek, Aloys, Andrey Zagrebin, Arvid Heise, Benchao Li, Benoit Hanotte, Benoît Paris, Bhagavan Das, Biao Liu, Chesnay Schepler, Congxian Qiu, Cyrille Chépélov, César Soto Valero, David Anderson, David Hrbacek, David Moravek, Dawid Wysakowicz, Dezhi Cai, Dian Fu, Dyana Rose, Eamon Taaffe, Fabian Hueske, Fawad Halim, Fokko Driesprong, Frey Gao, Gabor Gevay, Gao Yun, Gary Yao, GatsbyNewton, GitHub, Grebennikov Roman, GuoWei Ma, Gyula Fora, Haibo Sun, Hao Dang, Henvealf, Hongtao Zhang, HuangXingBo, Hwanju Kim, Igal Shilman, Jacob Sevart, Jark Wu, Jeff Martin, Jeff Yang, Jeff Zhang, Jiangjie (Becket) Qin, Jiayi, Jiayi Liao, Jincheng Sun, Jing Zhang, Jingsong Lee, JingsongLi, Joao Boto, John Lonergan, Kaibo Zhou, Konstantin Knauf, Kostas Kloudas, Kurt Young, Leonard Xu, Ling Wang, Lining Jing, Liupengcheng, LouisXu, Mads Chr. Olesen, Marco Zühlke, Marcos Klein, Matyas Orhidi, Maximilian Bode, Maximilian Michels, Nick Pavlakis, Nico Kruber, Nicolas Deslandes, Pablo Valtuille, Paul Lam, Paul Lin, PengFei Li, Piotr Nowojski, Piotr Przybylski, Piyush Narang, Ricco Chen, Richard Deurwaarder, Robert Metzger, Roman, Roman Grebennikov, Roman Khachatryan, Rong Rong, Rui Li, Ryan Tao, Scott Kidder, Seth Wiesman, Shannon Carey, Shaobin.Ou, Shuo Cheng, Stefan Richter, Stephan Ewen, Steve OU, Steven Wu, Terry Wang, Thesharing, Thomas Weise, Till Rohrmann, Timo Walther, Tony Wei, TsReaper, Tzu-Li (Gordon) Tai, Victor Wong, WangHengwei, Wei Zhong, WeiZhong94, Wind (Jiayi Liao), Xintong Song, XuQianJin-Stars, Xuefu Zhang, Xupingyong, Yadong Xie, Yang Wang, Yangze Guo, Yikun Jiang, Ying, YngwieWang, Yu Li, Yuan Mei, Yun Gao, Yun Tang, Zhanchun Zhang, Zhenghua Gao, Zhijiang, Zhu Zhu, a-suiniaev, azagrebin, beyond1920, biao.liub, blueszheng, bowen.li, caoyingjie, catkint, chendonglin, chenqi, chunpinghe, cyq89051127, danrtsey.wy, dengziming, dianfu, eskabetxe, fanrui, forideal, gentlewang, godfrey he, godfreyhe, haodang, hehuiyuan, hequn8128, hpeter, huangxingbo, huzheng, ifndef-SleePy, jiemotongxue, joe, jrthe42, kevin.cyj, klion26, lamber-ken, libenchao, liketic, lincoln-lil, lining, liuyongvs, liyafan82, lz, mans2singh, mojo, openinx, ouyangwulin, shining-huang, shuai-xu, shuo.cs, stayhsfLee, sunhaibotb, sunjincheng121, tianboxiu, tianchen, tianchen92, tison, tszkitlo40, unknown, vinoyang, vthinkxie, wangpeibin, wangxiaowei, wangxiyuan, wangxlong, wangyang0918, whlwanghailong, xuchao0903, xuyang1706, yanghua, yangjf2019, yongqiang chai, yuzhao.cyz, zentol, zhangzhanchum, zhengcanbin, zhijiang, zhongyong jin, zhuzhu.zz, zjuwangg, zoudaokoulife, 砚田, 谢磊, 张志豪, 曹建华
欢迎关注Flink菜鸟公众号,会不定期更新Flink(开发技术)相关的推文
