一、GIL锁(在Cpython解释器下)
1.定义
GIL本质就是一把互斥锁,所以其原理与互斥锁基本上是一致的,都是让多个并发线程同一时间只能有一个执行。
即在同一个进程同一时间内只能有一个线程在运行,这个就意味着在Cpython 解释器中一个进程下的多线程是没有办法实现并行的,这样就导致了无法使用多核的优势了。
GIL可以比喻成执行的权限,在同一个进程下,多个线程若想要运行,都必须先抢到这个执行权限即可正常运行。
2.为何要有GIL锁
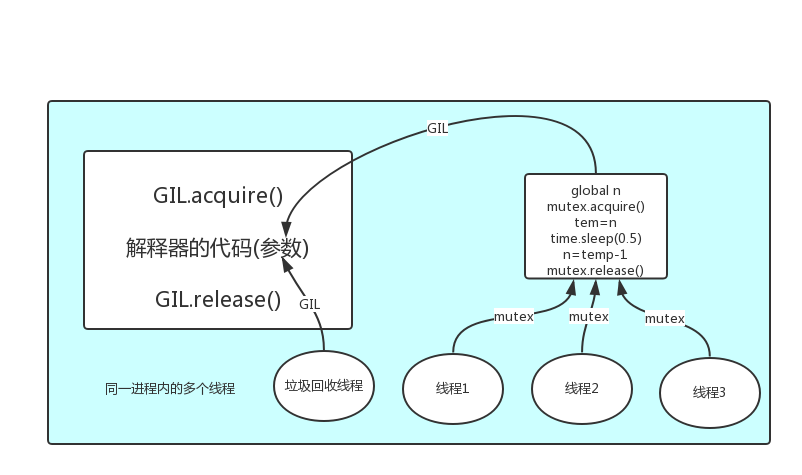
在Cpython解释器中自带的垃圾回收机制不是线程安全的。
原因是,假若没有GIL锁的情况下,程序员在同一个进程下开了多个线程,这些多个线程在取得同样的一份代码之后,并不是自己执行这些代码,而是交给Cpython解释器去执行,由于多个线程都可以同时或者先后交代码给Cpython解释器,此时就会产生一个时间差。
但是同时,Cpython解释器自带的垃圾回收机制会随时的出来巡逻,若某个线程不幸的碰到了,该线程中的代码在执行时,会给某些值赋值,向操作系统申请新的空间,在恰恰刚要赋值的前段时间,垃圾回收机制会认为该值的引用计数为0,就会将这个值当成垃圾回收掉,此时就造成了数据的丢失。
这是由于多个线程与Cpython自带的垃圾回收机制线程同时运行产生的冲突。所以,我们就需要一把锁将垃圾回收线程与程序员搞出来的多个线程分隔开来,而GIL锁就是用来干这件事的。
3.如何使用
在讲如何使用之前,我们先了解下GIL锁和自定义互斥锁的区别
GIL锁:它是相当于执行的权限,即一个任务想要顺利运行,该任务得首先得到GIL锁;GIL锁会在任务无法执行的时候,被操作系统强行释放;GIL锁保护的是解释器级别的数据。
自定义:自定义互斥锁一般是加在需要执行计算的代码前后,即便是无法执行,也不会自动释放;自定义互斥锁保护的是自己的数据。
在多个线程将需要执行的代码交给Cpython解释器之后,GIL锁会自动启动,以确保垃圾回收线程和其余多个线程间只能运行一个,所以说,GIL锁管理的是Cpyhon解释器的垃圾回收线程而不是需要执行的代码块线程。
3.1 在需要计算较多的时候,使用多进程效率会高于多线程
理由:cpu的作用就是用来计算的。当需要较复杂的计算的时候,同时开启多个进程,这些多个进程将会分配给计算机的多个cpu内核;这个时候我们就可以使用并行的方式来快速计算出结果,因为各个cpu之间是没有任何关联的,即使它们进行了短暂的IO操作,它也能保证是同时有多个CPU在执行,即并行。


1 from multiprocessing import Process 2 from threading import Thread 3 import time,os 4 5 6 def Foo(): 7 res=0 8 for i in range(99999999): 9 res*=i 10 11 def Bar(): 12 time.sleep(1) 13 print('----------') 14 15 if __name__ == '__main__': 16 print(os.cpu_count()) # 计算本机的cpu数 17 lists=[] 18 start_time=time.time() 19 for i in range(4): 20 x=Process(target=Foo,) # 6.077376127243042 21 # x=Thread(target=Foo,) # 16.704910039901733 22 # 多进程的运行时间明显少于多线程运行时间 23 lists.append(x) 24 x.start() 25 for list in lists: 26 list.join() 27 stop_time=time.time() 28 print('cost_time:',stop_time-start_time)
1 from multiprocessing import Process 2 from threading import Thread 3 import time,os 4 5 6 def Foo(): 7 res=0 8 for i in range(99999999): 9 res*=i 10 11 def Bar(): 12 time.sleep(1) 13 print('----------') 14 15 if __name__ == '__main__': 16 print(os.cpu_count()) 17 lists=[] 18 start_time=time.time() 19 for i in range(200): # 随着线程数的增加,多线程与多进程间的时间差会逐渐增大 20 # x=Process(target=Bar,) # 5.0585033893585205 21 x=Thread(target=Bar,) # 1.0244433879852295 22 lists.append(x) 23 x.start() 24 for list in lists: 25 list.join() 26 stop_time=time.time() 27 print('cost_time:',stop_time-start_time)
3.2 在进行IO操作较多的时候,使用多线程效率会高于多进程
理由:因为GIL的存在导致了同一个进程下的多个线程无法实现并行,即无法利用多核的优势。所以当需要IO操作较多的时候,大部分的时间都是在等待操作系统进行IO操作,所以内核数量的多少是不会对速度的快慢产生影响的。
二、进程池与线程池
1.定义
池的作用就是限制启动的进程或者线程的数量
2.为何有?
当并发的任务远远的超过了计算机所能承受的能力时,即该计算机无法一次性开启过多的进程或者线程;这时就需要用到进程池来限制启动的进程数或者线程数了。
3.如何使用?
说使用方式之前,我们先了解下,同步和异步的概念,它们指的都是提交任务的两种方式。
同步:提交完任务之后会在原地等待,直到任务运行完毕,取到返回值之后再运行下一行代码。
异步:提交完任务(绑定了一个回调函数)之后直接就撤,执行下一行代码,当任务有返回值之后就会自动触发回调函数。
1 from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor 2 import os,time 3 def task(n): 4 print('%s run...'%os.getpid()) 5 time.sleep(5) 6 return n**2 7 def parse(future): 8 print(',,,') 9 if __name__ == '__main__': 10 11 # 创建数量为4的进程池,参数可以自己设置 12 pool=ProcessPoolExecutor(4) 13 l=[] 14 start_time=time.time() 15 for i in range(5,9): 16 17 # 接收到一个返回值(对象) 18 future=pool.submit(task,i) 19 l.append(future) 20 21 #关闭进程池的入口 22 pool.shutdown(wait=True) 23 for future in l: 24 parse(future.result()) 25 stop_time = time.time() 26 print('---main---,cost_time:%s'%(stop_time-start_time)) 27 28 29 # 结果是先打印task函数的结果,然后等待打印完parse函数的结果之后,打印主进程的结# 果,所以该方式是同步
1 from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor 2 import os 3 import time 4 import random 5 6 def task(n): 7 print('%s run...' %os.getpid()) 8 time.sleep(10) 9 return n**2 10 def parse(res): 11 print('...') 12 if __name__ == '__main__': 13 pool=ProcessPoolExecutor(4) 14 l=[] 15 for i in range(1,5): 16 future=pool.submit(task,i) 17 l.append(future) 18 print('主') 19 20 # 主进程不会等子进程的结果
# 进程池
1 from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor 2 import os,time 3 def task(n): 4 print('%s run...'%os.getpid()) 5 time.sleep(5) 6 return n**2 7 def parse(future): 8 time.sleep(1) 9 10 # res的值会跟着i的改变而改变 11 res=future.result() 12 print('%s 处理了 %s '%(os.getpid(),res)) 13 14 if __name__ == '__main__': 15 16 # 创建数量为4的进程池,参数可以自己设置 17 pool=ProcessPoolExecutor(4) 18 l=[] 19 start_time=time.time() 20 for i in range(5,9): 21 22 # 接收到一个返回值(对象) 23 future=pool.submit(task,i) 24 25 # 将返回值(对象)通过回调函数中的进一步处理得到结果,而不阻塞其他线程的正常运行 26 # 造线程和线程运行时间大概是5s(并行),处理对象的时候,得到每个值都需要经过1s才能得到,所以总共是9s左右. 27 # future.add_done_callback(parse) 28 l.append(future) 29 30 # 关闭进程池的入口 31 pool.shutdown(wait=True) 32 stop_time=time.time() 33 for future in l: 34 # 此时future已经是数字了,它是没有result这个属性的 35 parse(future.result()) 36 print('---main---,cost_time:%s'%(stop_time-start_time))
3.2 线程池
线程池的创建于进程池是一样的方式
3.3 线程Queue
分三种方式:
(1)队列:先进先出
(2)堆栈:先进后出
(3)优先级队列:优先级较高的先出来,数字越小优先级越高