数据库学习笔记
关系数据库类型
Oracle,SQL Server,DB2,Sybase,MySQL,PostgreSQL,SQlite,mongoDB
使用python操作SQLite数据库
优点
1、已内嵌在Python中,使用时需要导入sqlite3。
2、使用c语言开发,支持大多数SQL标准,不支持外键限制。
3、支持原子的、一致的、独立和持久的事务。
4、通过数据库级上的独占性和共享锁定来实现独立事务,当多个线程和进程同一时间访问同一数据库时,只有一个可以写入数据。
5、支持140TB的数据库,每个数据库完全存储在单个磁盘文件中,以B+数据结构的形式存储,一个数据库就是一个文件,通过复制即可实现备份。
常用的SQLite可视化管理工具
www.sqlabs.com==>SQLiteManager
SQLite Database Browser
访问和操作SQLite数据
需要首先导入sqlite3模块,然后创建一个与数据库关联的Connection对象:
import sqlite3 #导入模块 conn = sqlite3.connect('example.db') #连接数据库 # 连接到SQLite数据库 # 数据库文件是example.db # 如果文件不存在,会自动在当前目录创建:
成功创建Connection对象以后,再创建一个Cursor对象,并且调用Cursor对象的execute()方法来执行SQL语句创建数据表以及查询、插入、修改或删除数据库中的数据:
c = conn.cursor() # 创建表, c.execute('''CREATE TABLE stocks (date text, trans text, symbol text, qty real, price real)''') # 插入一条记录 c.execute("INSERT INTO stocks VALUES ('2006-01-05','BUY', 'RHAT', 100, 35.14)") # 提交当前事务,保存数据 conn.commit() # 关闭数据库连接 conn.close()
如果需要查询表中内容,那么重新创建Connection对象和Cursor对象之后,可以使用下面的代码来查询。
for row in c.execute('SELECT * FROM stocks ORDER BY price'): print(row)
connect(database[, timeout, isolation_level, detect_types, factory]) :连接数据库文件,也可以连接":memory:"在内存中创建数据库。
sqlite3.Connection.execute():执行SQL语句
sqlite3.Connection.cursor():返回游标对象
sqlite3.Connection.commit():提交事务
sqlite3.Connection.rollback():回滚事务
sqlite3.Connection.close():关闭连接
connection对象
在sqlite3连接中创建并调用自定义函数
import sqlite3 import hashlib # 自定义Python函数 def md5sum(t): return hashlib.md5(t).hexdigest() # 在内存中创建临时数据库 conn = sqlite3.connect(":memory:") # 创建可在SQL调用的函数,其中第二个参数表示函数的参数个数 conn.create_function("md5", 1, md5sum) cur = conn.cursor() # 在SQL语句中调用自定义函数 cur.execute("select md5(?)", ["中国山东烟台".encode()]) print(cur.fetchone()[0])
row对象
创建并插入数据
conn = sqlite3.connect("D:\test.db") c = conn.cursor() c.execute('''CREATE TABLE stocks(date text, trans text, symbol text, qty real, price real)''') c.execute("""INSERT INTO stocks VALUES ('2006-01-05','BUY','RHAT',100,35.14)""") conn.commit() c.close()
使用fetchone()方法读取数据
conn.row_factory = sqlite3.Row c = conn.cursor() c.execute('SELECT * FROM stocks') r = c.fetchone() print(type(r)) print(tuple(r)) print(r[2]) print(r.keys()) print(r['qty']) for field in r: print(field)
数据库的应用
1、上篇博客的CSV文件存在数据库
代码
import sqlite3 import openpyxl lists=sqlite3.connect('best college.db') c=lists.cursor() c.execute('''CREATE TABLE rankg("序号","排名","学校名称","省市","总分","生源质量","培养结果","科研规模","科研质量","顶尖成果","顶尖人才","科技服务","产学研合作","成果转化" )''') listinsheet=openpyxl.load_workbook(r'university.xlsx') datainlist=listinsheet.active #获取excel文件当前表格 data_truck=('''INSERT INTO rankg("序号","排名","学校名称","省市","总分","生源质量","培养结果","科研规模","科研质量","顶尖成果","顶尖人才","科技服务","产学研合作","成果转化") VALUES (?,?,?,?,?,?,?,?,?,?,?,?,?,?)''') for row in datainlist.iter_rows(min_row=2,max_col=14,max_row=datainlist.max_row): #使excel各行数据成为迭代器 cargo=[cell.value for cell in row] #敲黑板!!使每行中单元格成为迭代器 c.execute(data_truck,cargo) #敲黑板!写入一行数据到数据库中表rankf for row in c.execute('SELECT * FROM rankg ORDER BY "序号"'): print(row) lists.commit() lists.close()
运行结果(部分截图)
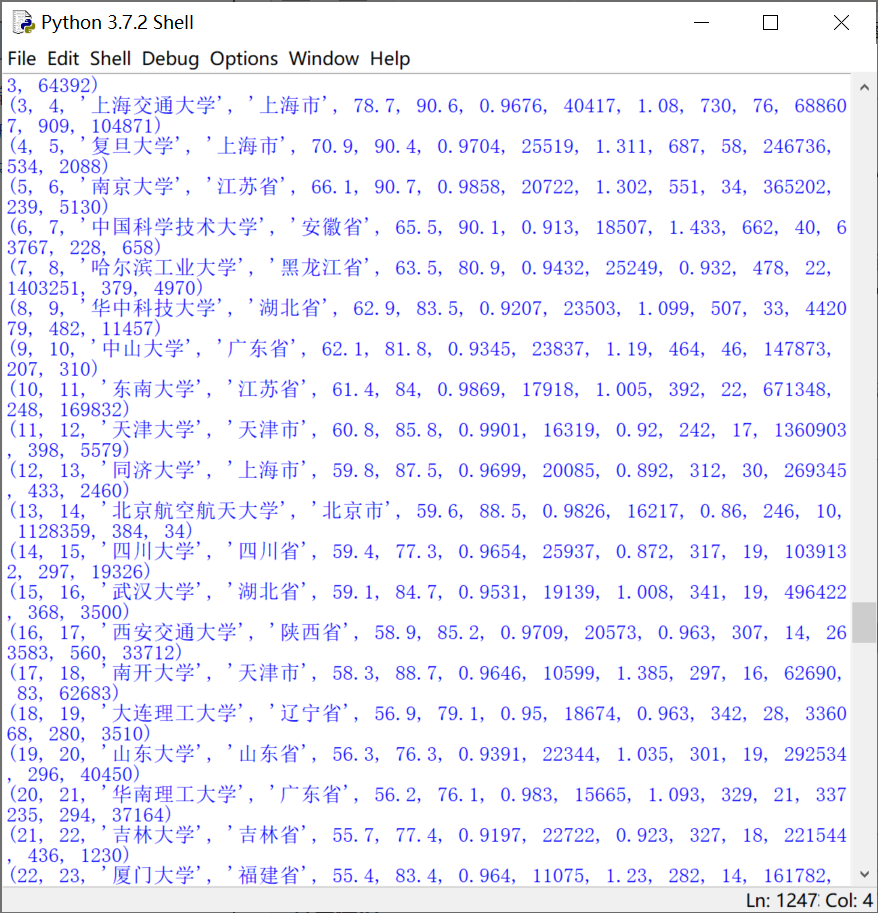
2、并查询我们学校的排名
代码
import sqlite3 import openpyxl lists=sqlite3.connect('best college.db') c=lists.cursor() c.execute('''CREATE TABLE rankh("序号","排名","学校名称","省市","总分","生源质量","培养结果","科研规模","科研质量","顶尖成果","顶尖人才","科技服务","产学研合作","成果转化" )''') listinsheet=openpyxl.load_workbook(r'university.xlsx') datainlist=listinsheet.active #获取excel文件当前表格 data_truck=('''INSERT INTO rankh("序号","排名","学校名称","省市","总分","生源质量","培养结果","科研规模","科研质量","顶尖成果","顶尖人才","科技服务","产学研合作","成果转化") VALUES (?,?,?,?,?,?,?,?,?,?,?,?,?,?)''') for row in datainlist.iter_rows(min_row=2,max_col=14,max_row=datainlist.max_row): #使excel各行数据成为迭代器 cargo=[cell.value for cell in row] #敲黑板!!使每行中单元格成为迭代器 c.execute(data_truck,cargo) #敲黑板!写入一行数据到数据库中表rankh c.execute('SELECT * FROM rankh WHERE "学校名称"="广州大学"')#由于我们学校没有上榜就查询了广州大学的排名 r = c.fetchall() print(r) lists.commit() lists.close()
结果

3、将广东省的学校进行排名
代码
import sqlite3 import openpyxl lists=sqlite3.connect('best college.db') c=lists.cursor() c.execute('''CREATE TABLE rank9("序号","排名","学校名称","省市","总分","生源质量","培养结果","科研规模","科研质量","顶尖成果","顶尖人才","科技服务","产学研合作","成果转化" )''') listinsheet=openpyxl.load_workbook(r'university.xlsx') datainlist=listinsheet.active #获取excel文件当前表格 data_truck=('''INSERT INTO rank9("序号","排名","学校名称","省市","总分","生源质量","培养结果","科研规模","科研质量","顶尖成果","顶尖人才","科技服务","产学研合作","成果转化") VALUES (?,?,?,?,?,?,?,?,?,?,?,?,?,?)''') for row in datainlist.iter_rows(min_row=2,max_col=14,max_row=datainlist.max_row): #使excel各行数据成为迭代器 cargo=[cell.value for cell in row] #敲黑板!!使每行中单元格成为迭代器 c.execute(data_truck,cargo) #敲黑板!写入一行数据到数据库中表rank9 c.execute('SELECT * FROM rank9 WHERE "省市"="广东省" ORDER BY "生源质量"')#由于2016的数据中没有“社会声誉”,因此用“生源质量”来排序 r = c.fetchall() print(r) lists.commit() lists.close()
结果显示
