前言:requests获取的都是最原始的html文档,有些浏览器的页面是通过js处理数据生产的结果,这些数据可能是通过Ajax加载的,可能是包含在HTML文档中,也可能通过js的一些算法算出来的;
其中有些数据不会存在在HTML文档中,而是在页面加载完之后,向服务器中申请得到的数据,然后吧这些得到的数据再进行处理从而呈现在网页中的,这其实就是发送了一个Ajax请求(这些数据都是通过Ajax的统一加载后再呈现出来的)
====这就使得如果单单用传统的requests来获得的数据的话,其实就无法得到通过ajax的这些数据了,但是假如可以用request来模拟Ajax请求的话,那我们就可以成功的爬取到这些数据了
本章就是了解如何取分析和爬取Ajax请求
6.1、什么是Ajax
它不是一门编程语言,而是利用js在保证页面不被刷新,页面链接不改变的情况下与服务器交换数据并更新部分网页的技术
1、===其实就相当于是一直往下看一个网页的时候,它就不断的帮我们加载,但是我们刚进来的时候肯定是不会吧后面的部分也提前加载了
是要看我们看到了哪里,才加载哪里的
2、基本原理
发送Ajax请求到网页更新这个过程可以简单分为三步:发送请求-》解析内容->渲染网页
①发送请求
前面都是用python来发送请求的,但是这里是直接用js来实现
js对Ajax最底层的实现,其实就是新建一个XMLHttpRequest 对象,然后调用onreadystatechange进行监听,通过这个对象来调用open和send对某个链接(服务器端的链接)发送请求,然后发送完请求之后,当服务器返回响应的时候,onreadystatechange里面的方法就会被触发,然后在这个方法里面解析内容
②解析内容
③渲染网页
解析完服务器响应的内容之后,就可以调用js来对解析的内容对网页进行进一步的处理了,其实这个步骤都是在用js来完成的,
6.2、Ajax分析方法
①要在哪里查看这些Ajax请求
下面是以本书作者的微博 :https://m.weibo.cn/u/2830678474 为例
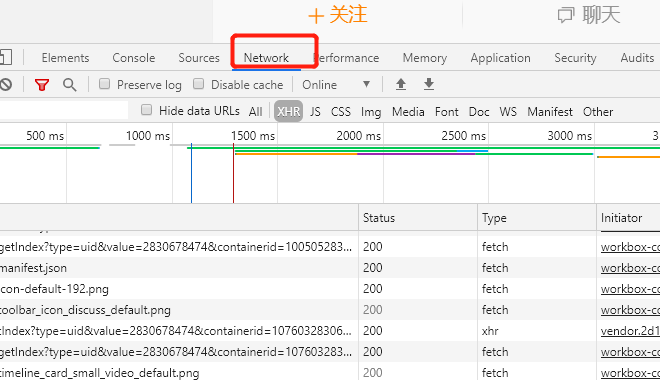
打开了这个网页之后,然后刷新一下,就可以看到network中出现了很多条目了
===这个network里面其实是页面加载过程中浏览器和服务器之间发送请求和接受响应的所有记录了
Ajax其实有它的特殊请求类型,type=XHR
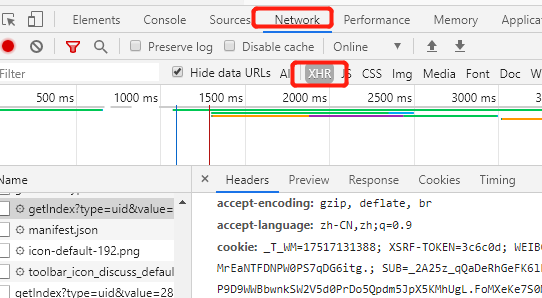
这种一般就是Ajax请求了
然后点击查看一个xhr请求的详情的时候,可以在Headers中
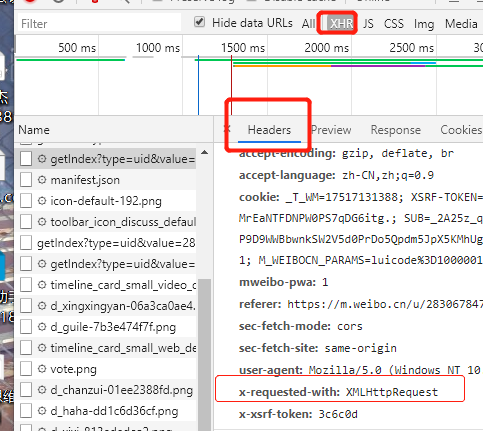
其实这就标记了这个请求其实是一个Ajax请求了
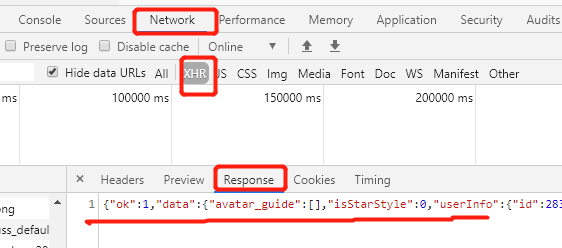
然后点击查看一个Preview,其实这就是响应的内容了,它其实是JSON格式的
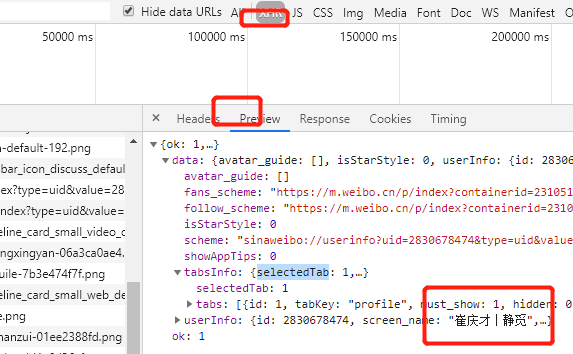
这些其实就是用来渲染博客主人的数据,js接受到这些数据之后,就会进行相应的渲染方法,然后把这个数据在网页中渲染出来了
(但是这个Preview其实是这个浏览器自动帮我们解析的了,并不是服务器真正传过来的相应了)
在Response中才是真实的返回数据了
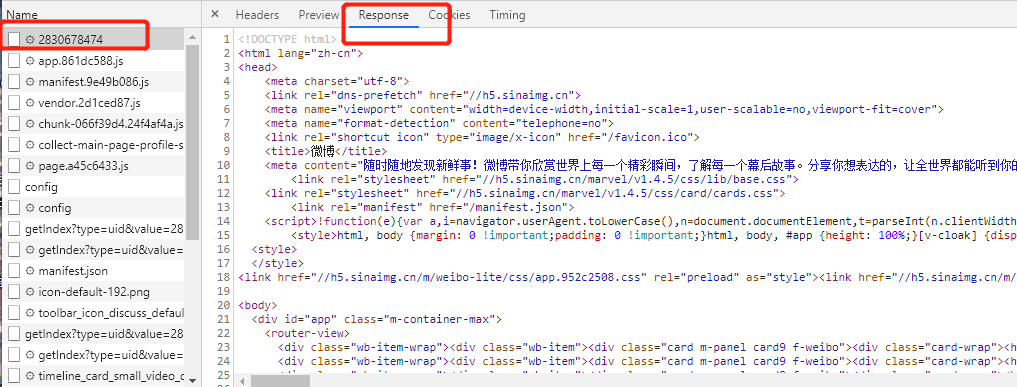
我们可以切回到这个网页中的第一个请求,这个请求对应的response中其实就是最原始的链接返回的请求,后面的都是另外的通过ajax向服务器返回的东西了
6.3、Ajax结果提取
(用python来模拟一下这些Ajax请求)
1、分析请求: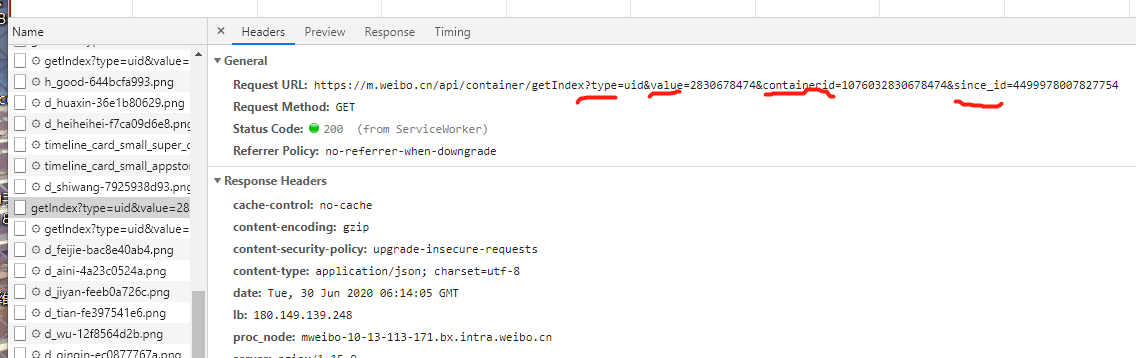
可以看到是一个get类型的请求,request URL就是请求的链接了,然后请求的参数有四个

然后就会发现,其实四个参数中,前面三个参数 type value containerid 其实都是一样的,变化的就是since._id这个参数其实是用来控制分页的
2、分析响应
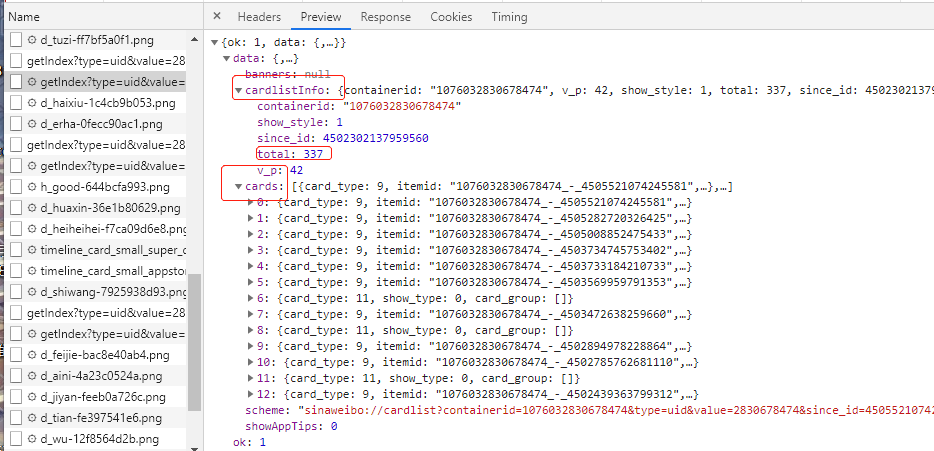
其中total其实是微博的总数量,我们可以通过这个数字来估算分页数,后面其实就是一个列表(包含了13个元素)
===我们展开列表中的其中一个响应内容来看的时候可以发现
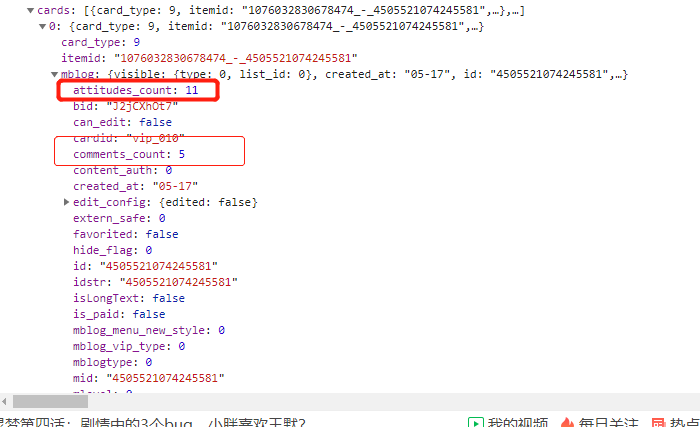
然后在mblog字段中,我们可以看到很多重要的信息,比如 attitudes_count(点赞数量) comments_count(评论数量)等等,这样我们请求一下这个服务器接口的话可以得到13跳微博的信息,那么我们只需要改变一下最后一个参数 since_id的话 简单做一个循环,就可以获取所有的微博了
(现在和教程中的情况不同的是,教程中的第四个参数是page,也就是页数,这个是可以预测的,但是现在的第四个参数是一个很长的数字,没法找到一些规律的)
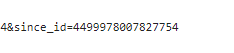
3、实战演练
①可以通过urlencode把一个对象变成 url后面的参数序列
②通过response.json()来把内容解析为json格式
③可以把python中的yield看成是return
④因为如果想要爬取一个text标签里面的文字的话,但是这个标签里面还有比如a标签等等其他标签的话,这个时候可以通过pyquery将其他的HTML标签去掉
(MySQL之2003-Can't connect to MySQL server on 'localhost'(10038)的解决办法)
===https://blog.csdn.net/qq_41140741/article/details/81395111
(提前下载一下pymongo库)
import requests from urllib.parse import urlencode from pyquery import PyQuery as pq from pymongo import MongoClient base_url = 'https://m.weibo.cn/api/container/getIndex?' headers = { 'Host': 'm.weibo.cn', 'Referer': 'https://m.weibo.cn/u/2830678474', 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36', 'X-Requested-With': 'XMLHttpRequest', } client = MongoClient() db = client['weibo'] collection = db['weibo'] max_page = 10 def get_page(page): params = { 'type': 'uid', 'value': '2830678474', 'containerid': '1076032830678474', 'page': page } url = base_url + urlencode(params) try: response = requests.get(url, headers=headers) if response.status_code == 200: return response.json() except requests.ConnectionError as e: print('Error', e.args) def parse_page(json): if json: items = json.get('data').get('cards') for item in items: item = item.get('mblog') weibo = {} weibo['id'] = item.get('id') weibo['text'] = pq(item.get('text')).text() weibo['attitudes'] = item.get('attitudes_count') weibo['comments'] = item.get('comments_count') weibo['reposts'] = item.get('reposts_count') yield weibo def save_to_mongo(result): if collection.insert(result): print('Saved to Mongo') if __name__ == '__main__': for page in range(1, max_page + 1): json = get_page(page) results = parse_page(json) for result in results: print(result) save_to_mongo(result)
6.4、分析Ajax 爬取今日头条街拍美图


import os from multiprocessing.pool import Pool import requests from urllib.parse import urlencode from hashlib import md5 def get_page(offset): params = { 'offset': offset, 'format': 'json', 'keyword': '街拍', 'autoload': 'true', 'count': '20', 'cur_tab': '1', } url = 'http://www.toutiao.com/search_content/?' + urlencode(params) try: response = requests.get(url) if response.status_code == 200: return response.json() except requests.ConnectionError: return None def get_images(json): if json.get('data'): for item in json.get('data'): title = item.get('title') images = item.get('image_detail') for image in images: yield { 'image': image.get('url'), 'title': title } def save_image(item): if not os.path.exists(item.get('title')): os.mkdir(item.get('title')) try: response = requests.get(item.get('image')) if response.status_code == 200: file_path = '{0}/{1}.{2}'.format(item.get('title'), md5(response.content).hexdigest(), 'jpg') if not os.path.exists(file_path): with open(file_path, 'wb') as f: f.write(response.content) else: print('Already Downloaded', file_path) except requests.ConnectionError: print('Failed to Save Image') def main(offset): json = get_page(offset) for item in get_images(json): print(item) save_image(item) GROUP_START = 1 GROUP_END = 20 if __name__ == '__main__': pool = Pool() groups = ([x * 20 for x in range(GROUP_START, GROUP_END + 1)]) pool.map(main, groups) pool.close() pool.join()