前面已经描述了大型网站系统的特点,而对一个大型网站系统,其架构也是重要的一个环节。
大型网站技术主要的挑战来自于庞大的用户、高并发以及海量的数据这三个方面。大型网站的形成就像一颗大树的成长,历尽长时间的磨练,最后枝繁叶茂,服务他人。
初始网站架构结构
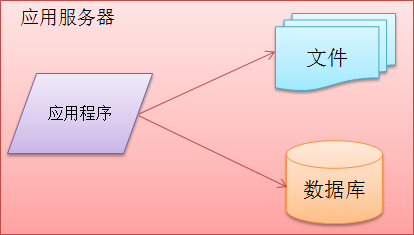
起初的网站鉴于用户量、访问量较少,只需要一台服务器足以,应用程序、数据库、文件等其所有资源放在一太服务器上就已经足够满足此时的需求,这时候网站的架构就几个简单组成部分如下图
应用和数据服务分离
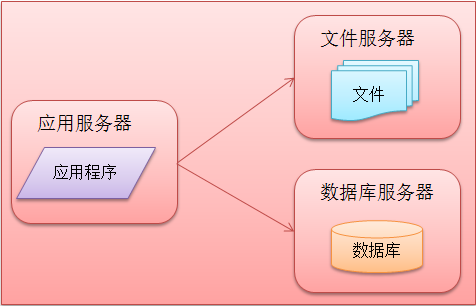
随着网站业务需求的发展,越来越多的用户进行访问,此时一台服务器渐渐不能满足需求,数据的存储空间出现屏障。于是应用程序、数据库、文件三者面临分离,各自为首分配一台服务器,这三台服务器对硬件的要求各取所需,应用服务器处理大量的业务逻辑,需求更快更大的CPU;数据库服务器对数据库的处理需要快速搜索以及缓存,需求对内存更大,对硬盘读写能力更迅速;文件服务器需求放入大量的用户资源,对硬盘空间要求更大。此时的网站的架构组成部分展示如下图
使用缓存
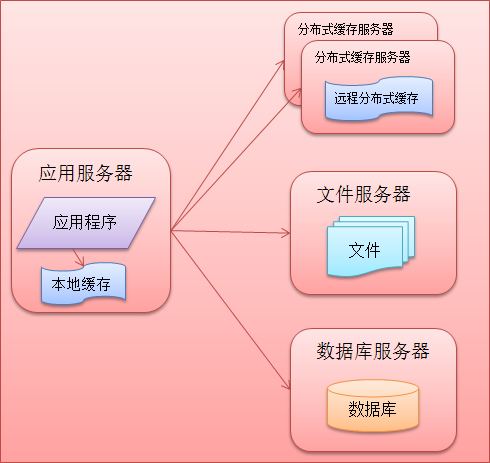
网站的架构进一步改进后可以满足了业务的发展,但是随着网站知名度提升,用户量的进一步增加,访问数据相比之前愈加频繁,数据库压力急剧上升导致网站访问出现延迟,用户的性能体验出现下滑,面临此时网站出现的性能问题,网站架构设计需要再一次的进化,鉴于网站访问也遵循二八定律,例如:新浪微博,只有经常登录的用户才会发微博,看微博,而这些用户对于总用户数只是冰山一角。既然出现这一现象,那么缓存这部分的数据是不是可以解决这现象呢?网站缓存可以分为本地缓存和分布式缓存这两种,二者的区别是本地缓存速度快但是受服务器内存限制缓存的数量有限,而分布式缓存采用的是集群处理,理论上是可以避免内存瓶颈。此时网站的架构组成部分如下图
应用服务器集群改善网站并发能力
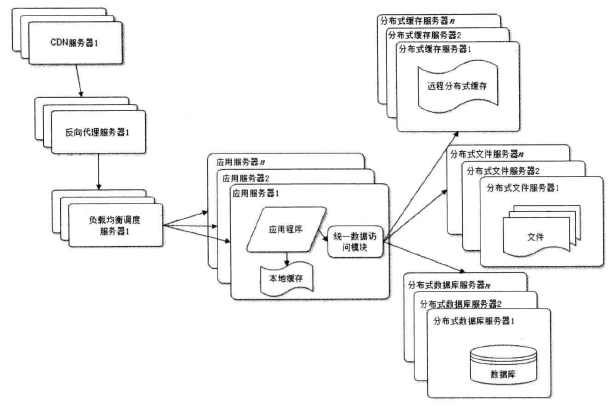
使用缓存后,数据库的压力得到缓解,但是在面临网站高峰期时,应用服务器处理单一的请求连接出现瓶颈,万事都有解决的办法,只是看你愿不愿去想,愿不愿去尝试做,采用集群,集群多台应用程序服务器分布原有的应用程序服务器,从而实现了系统的可伸缩性,网站架构此时演化成这样如下图

数据库读写分离
使用缓存,虽然使用户请求数据操作大部分不直接通过数据库,但是仍有一部分数据(缓存过期、缓存数据没有命中)读写操作需要访问数据库,面对这部分数据,可能出现数据访问负载压力,把数据库读写操作分离性能效果理当会如何呢?效果无言而喻。

CDN和反向代理加速网站响应
网络覆盖范围地区广泛,造就了网络环境复杂,从而用户访问网站性能体现也各有差异,鉴于这问题,网站架构使用CDN和反向代理以技术加速网站响应,二者原理都是缓存,CDN可以从距离用户最近网络提供点获取数据;反向代理则是首先从反向代理服务器中获取数据。
分布式文件、数据库系统
任何单一的服务器最后都是满足不了业务需求发展。虽然前面数据库读写分离能够改善数据库负载压力但是随着业务不断壮大最终还是难以维持此时使用分布式数据库,该技术不到不得以建议不使用,而对于这个技术解决方案更常用的使用业务拆分,将不同的业务数据库部署在不同的物理服务器上。
NoSQL和搜索引擎
该技术对于可伸缩的分布式提供更好的支持,减轻应用程序管理诸多数据源的麻烦。

业务拆分
大型网站日益发展壮大,业务需求越来越复杂,使用分而治之手段分离整个网站的业务变成不同的产品线。具体到技术上,将一个网站拆分成许多不同的应用,每个应用独立部署,而应用与应用之间通过超链接关联,不过最多的还是通过访问同一个数据存储来构成一个关联的完整系统。

分布式服务
一个应用系统需要执行相同业务操作,那么可以将共同的业务提取出来,独立部署,由这些可复用的业务连接数据库,提供共用业务服务,而应用系统只需要管理用户界面,通过分布式调用共用业务服务完成具体业务操作。
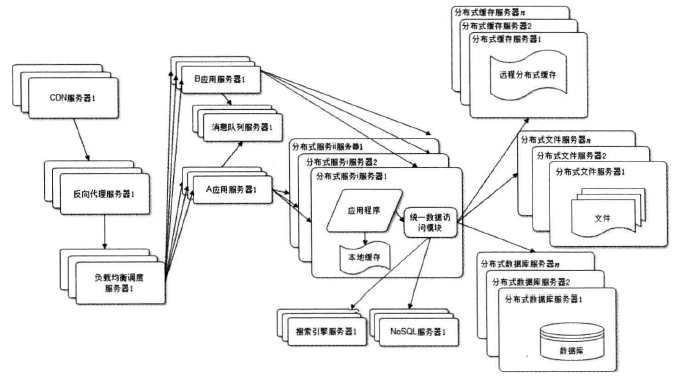
大型网站结构演化到这里,基本上大多数的技术问题都得以解决了,但是事物发展到一定的阶段就会摆脱初衷向更强的方向发展。目前许多的大型网站都建立自己的云平台,将计算作为一种资源进行出售。
大型网站架构演化历经了长时间磨练才发展如此,在过程中也是出现一些易步入的误区
一味的追随大公司解决方案,大公司的经验和成功固然重要,但是不能盲目的追从,要与实际的具体业务需求有所改动;
为了技术而技术,网站技术是为业务而存在的,但是一味的追求新技术,可能会导致结构技术之路越走越难;
企图用技术解决所有问题,技术虽是解决业务问题的,但也不是万能钥匙,有些业务的问题也是可以通过业务手段解决。
参考资料:《大型网站技术架构核心原理与案例分析》