丢弃法

dropout可能会比之前讲的权重衰退效果更好,应用于防止模型过拟合。

像上图,不管加入多少个点,都要让图片是可以看清的。
使用有噪音的数据,就等价于一个叫做T正则。(正则就是是的权重的值不要太大,避免模型过拟合)
在数据中加入噪音,等价于一个正则。跟之前加入的噪音不一样,之前是固定噪音,这里加入的是随机噪音,不断地加入随机噪音。
丢弃法就是不在输入的时候加入噪音,而是在层之间加入噪音,这就是丢弃法。这里也有一个隐含选项,也就是丢弃法是一个正则。

假设x是我们一层到下一层的输出,我们希望对x加入噪音得到x',虽然是加了噪音,但是不要改变期望,也就是对x'求平均,这个值还是对的,这个就是唯一的要求。
然后丢弃法的扰动方式可以就是上面公式,给定一个概率p,然后按照公式进行改变。同时这样改变是不会让期望变化的,原理如上图红色公式。
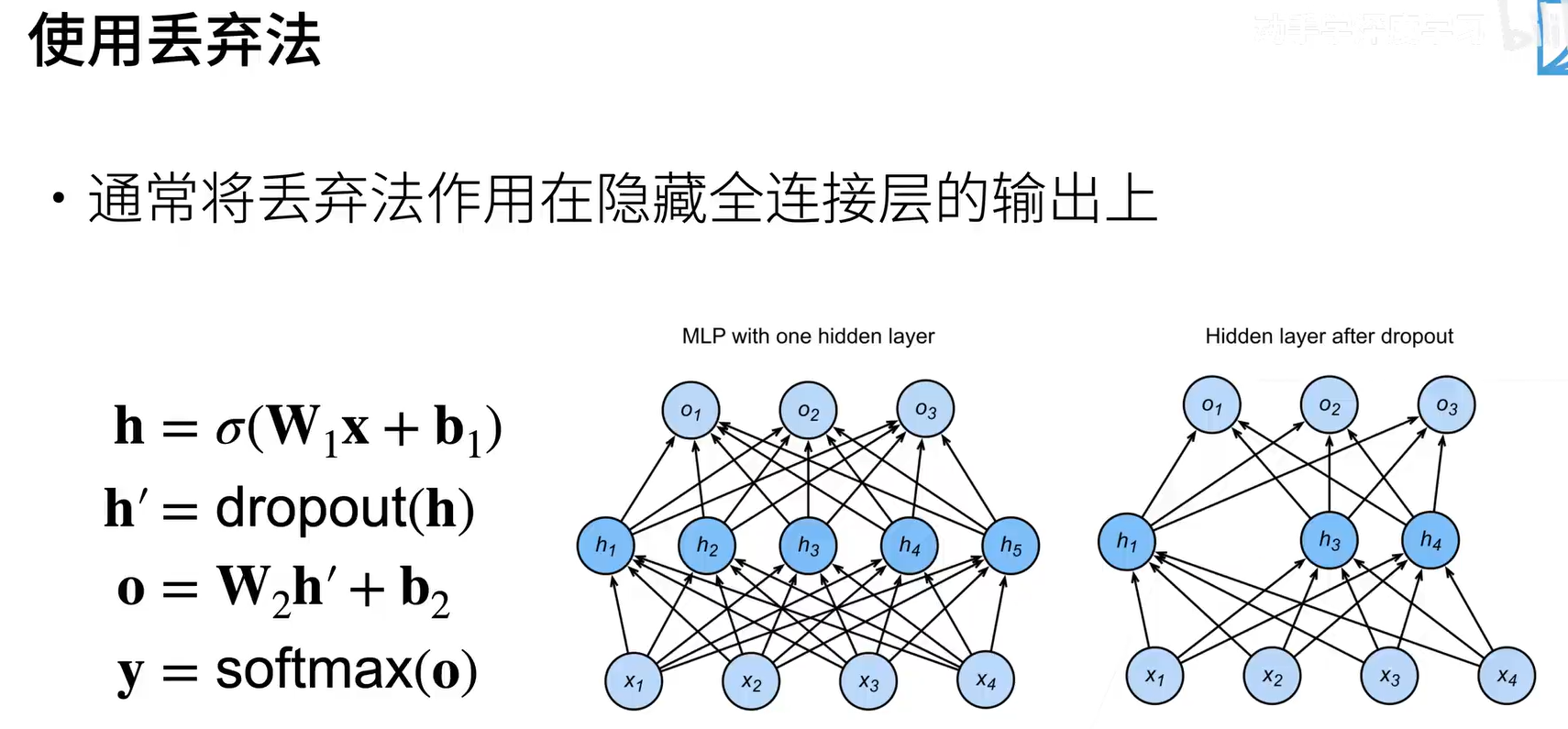
dropout是作用在隐层的全连接输出上,有的单元会被丢弃(置零),有的单元会被放大。
每一个batch都会进行dropout,当初作者在论文中解释是每次都会激活不同的一个子网络,最后相当于就是多个子网络求平均,所以效果会好。
但是现在在主流看来,其实dropout更像是一个正则,而不像作者所说的那样。(理论和工程之间是一个gap的,就像热力学是在蒸汽机发明100多年后才出来的,有时候就是工程会去倒逼理论进步,而理论可以反过来更好的指导工程)

推理,也就是在预测的过程中,是不会使用dropout的,这是因为dropout是一个正则项,正则项只在训练中使用,正则会对权重产生影响。当我们在预测的时候,也就是权重不需要发生变化的时候,我们是不需要正则的,所以在推理中我们是不需要使用dropout的。
推理过程中,dropout输出的是值本身,这样也能保证有一个确定性的输出。

dropout就是作用做多层感知机(MLP)的隐层输出上,像CNN(CNN有池化)之类的很少会使用dropout。
其中丢弃概率是控制模型复杂度的超参数(0.1,0.5,0.9这三个是最常见的丢弃概率)。
代码实现
操作总结
# 定义具有两个隐藏层的多层感知机,每个隐藏层包含256个单元
dropout1, dropout2 = 0.2, 0.5
net = nn.Sequential(nn.Flatten(),nn.Linear(784,256),nn.ReLU(),nn.Dropout(dropout1),nn.Linear(256,256),nn.ReLU(),nn.Dropout(dropout2),nn.Linear(256,10))
# 初始化参数
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);
# 进行训练
num_epochs, lr, batch_size = 10, 0.5, 256
loss = nn.CrossEntropyLoss()
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
QA
- dropout应该是放在relu前面还是后面?
其实放在前面还是放在后面都是一样的,当时习惯是讲dropout放在relu后面。
- 关于dropout对MLP,以及模型控制
dropout是现在最主流的对于多层感知机的控制,所以你是很有可能会遇到dropout这个技术的。
对于深度学习来说,你通常可以把模型弄得复杂一点,然后在通过正则化来控制模型的复杂度。也就是你把隐层弄大点,dropout的值也弄大点,说不定效果比小一点隐层会好,大家是可以试试的。
- dropout随机置0对求梯度和反向传播的影响是什么?
如果在这个batch的某个单元被置零了,那么这个batch对于这个单元是不会进行参数更新的。
其实如果某个单元被置零,按照子网络来理解会简单一些。
- 在使用BN的时候,还有必要使用dropout吗?
我们还没讲BN,BN有点点正则的意思在里面,但是BN是作用在卷积层上的。BN是给卷积层用的,dropout是给全连接用的,在卷积层我们是不会使用dropout的,不一样,所以dropout和BN没有太多的相关性。
- dropout每次随机选几个子网络,最后做平均的做法是不是类似于随机申领多决策树做投票的这种思想?
是的,Hinton之前就是这么认为的。
- 在解决过拟合问题上,dropout和regularization的主要区别是什么?
其实你就可以认为dropout就是一种正则,和L1、L2正则是一样的,其目的都是为把权重的取值范围给限制,减小模型的复杂度,只是通过的手段不同。
- dropout已经被google申请专利,产品开发有替代方法吗?
其实这个真的... 其实能申请的,google都已经帮你申请好了,像transformer。
但是我在AWS律师也没有说可以用,也没有说不能用... 我还是一直有用,所以你也不要太担心这个事情。
- dropout和weight decay都是属于正则,为何dropout效果更好现在更常用呢?
其实dropout没有weight decay常用,其实weight decay大家都在用,我们一般都会开weight decay,dropout主要是对全连接层的隐层输出使用,但weight decay对后面的卷积,transformer都是可以使用的。
为什么效果好?就是老中医!
比如一个MLP只有一个隐层,64 units,然后你将其加到128 units,在加上一个p=0.5的dropout,那么在感觉上,好像前后两者是一样的,但是很有可能后者更加的work。就是深度学习是可以让模型过拟合,然后通过正则让模型不要学偏。
- 在同样的lr下,dropou的介入会不会造成参数收敛更慢?需要比没有dropout的情况下适当调大lr吗?
dropout还真有可能会使得收敛变慢,因为想相当于每次更少的权重在更新梯度。
但是lr并不用因为有dropout而去调整,dropout不会去改变期望,而lr主要是对期望和方差敏感一点。
- transformer可以看做是一种特殊的MLP吗?
目前还没有,transformer可以看做是一个kernel machine。