参考链接: https://www.cnblogs.com/liwenzhou/p/9398959.html
rest framework中提供了三种分页模式: from rest_framework.pagination import PageNumberPagination, LimitOffsetPagination, CursorPagination
PageNumberPagination
分页规则
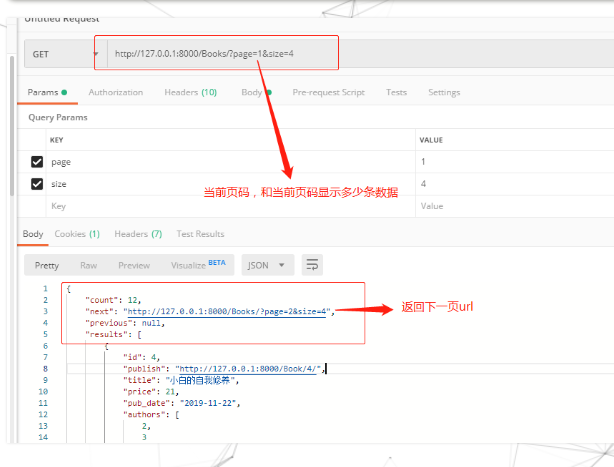
按页码数分页,第n页,每页显示m条数据
例如:http://127.0.0.1:8000/api/article/?page=2&size=1
配置分页类:
class MyPageNumber(PageNumberPagination): page_size = 2 # 每页显示多少条 page_size_query_param = 'size' # URL中每页显示条数的参数 page_query_param = 'page' # URL中页码的参数 max_page_size = None # 最大页码数限制
视图:
# 分页 from rest_framework.pagination import PageNumberPagination class MyPageNumberPagination(PageNumberPagination): page_size = 10 # 每页显示多少条 max_page_size = 10 # # 最大页码数限制 page_size_query_param = 'size' # URL中每页显示条数的参数 page_query_param = 'page' # URL中页码的参数 # 分页 class BookView(APIView): def get(self, request): book_list = Book.objects.all() # # 分页(原理) page_obj = MyPageNumberPagination() # # 在序列化之前就进行分页 # books_pag = pnp.paginate_queryset(book_list, request,self) books_pag = page_obj.paginate_queryset(queryset=book_list, request=request, view=self) bs = BookModelSerializers(books_pag, many=True) return Response(bs.data)

返回带下一页页码链接的响应
路由:
urlpatterns = [ re_path(r"^Books/$", views.BookView.as_view(), name='book'), # re_path(r"^Book/(?P<pk>d+)/$", views.BookDetailView.as_view(), name='book'), re_path(r"^Book/(?P<id>d+)/$", views.BookDetaiView.as_view(), name='books'), ]
序列化:
from rest_framework import serializers class BookModelSerializers(serializers.ModelSerializer): # 自定义publish字段超链接路径 depth = 1 # 0 ~ 10 publish = serializers.HyperlinkedIdentityField(view_name='books', lookup_field='publish_id', lookup_url_kwarg='id') """ # view_name参数 进行传参的时候是参考路由匹配中的name与namespace参数 # lookeup_field参数是根据在UserInfo表中的连表查询字段group_id # look_url_kwarg参数在做url反向解析的时候会用到 """ class Meta: model = Book # fields = ['id', 'title', 'pub_date', 'publish', 'authors']# 这个是可以自定义字段的 fields = "__all__" depth = 0 # 自动向内部进行深度查询,就是查询的比较详细 depth表示查询层数
配置分页类:
# 分页 from rest_framework.pagination import PageNumberPagination class MyPageNumberPagination(PageNumberPagination): page_size = 10 # 每页显示多少条 max_page_size = 10 # # 最大页码数限制 page_size_query_param = 'size' # URL中每页显示条数的参数 page_query_param = 'page' # URL中页码的参数
视图:
查询所有:
class BookView(APIView): def get(self, request, *args, **kwargs): book_list = Book.objects.all() page_obj = MyPageNumberPagination() # 在序列化之前就进行分页 books_pag = page_obj.paginate_queryset(queryset=book_list, request=request, view=self) # context十分关键,如果不将request传递给它,在序列化的时候,图片与文件这些Field不会再前面加上域名,也就是说,只会有/media/img...这样的路径! bs = BookModelSerializers(instance=books_pag, many=True, context={'request': request}) # 在做链接的时候需要添加context参数 print(bs) # 默认就返回json格式的字符串 return page_obj.get_paginated_response(bs.data)
查询单个:
class BookDetaiView(APIView): # inquire database def get(self, request, id, *args, **kwargs): book_list = Book.objects.filter(id=id) bs = BookModelSerializers(instance=book_list, many=True, context={'request': request}) # 在做链接的时候需要添加context参数 print(bs) # 默认就返回json格式的字符串 return Response(bs.data)
LimitOffsetPagination
分页规则:
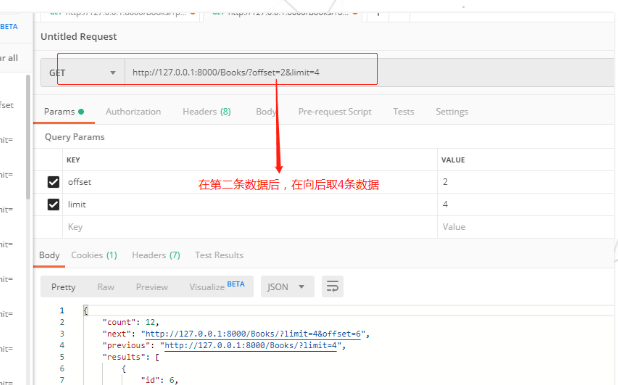
分页,在n位置,向后查看m条数据
例如:http://127.0.0.1:8000/api/article/?offset=2&limit=2
配置分页类:
# offset分页 class MyLimitOffset(LimitOffsetPagination): default_limit = 1 # 默认向后看1条数据 limit_query_param = 'limit' # url向后取多少条数据 offset_query_param = 'offset' # url 以它为基准向后取数据 max_limit = 999 # 最大看几条数据
路由:
urlpatterns = [ re_path(r"^Books/$", views.BookView.as_view(), name='book'), # re_path(r"^Book/(?P<pk>d+)/$", views.BookDetailView.as_view(), name='book'), re_path(r"^Book/(?P<id>d+)/$", views.BookDetaiView.as_view(), name='books'), ]
序列化:
from rest_framework import serializers class BookModelSerializers(serializers.ModelSerializer): # 自定义publish字段超链接路径 depth = 1 # 0 ~ 10 publish = serializers.HyperlinkedIdentityField(view_name='books', lookup_field='publish_id', lookup_url_kwarg='id') """ # view_name 参数 进行传参的时候是参考路由匹配中的name与namespace参数 # lookeup_field 参数是根据在UserInfo表中的连表查询字段group_id # look_url_kwarg 参数在做url反向解析的时候会用到 """ class Meta: model = Book # fields = ['id', 'title', 'pub_date', 'publish', 'authors']# 这个是可以自定义字段的 fields = "__all__" depth = 0 # 自动向内部进行深度查询,就是查询的比较详细 depth表示查询层数
视图:
查询所有:
from rest_framework.pagination import PageNumberPagination, LimitOffsetPagination # offset分页 class MyLimitOffset(LimitOffsetPagination): default_limit = 1 # 默认向后看1条数据 limit_query_param = 'limit' # url向后取多少条数据 offset_query_param = 'offset' # url 以它为基准向后取数据 max_limit = 999 # 最大看几条数据 class BookView(APIView): def get(self, request, *args, **kwargs): book_list = Book.objects.all() # 分页 page_obj = MyLimitOffset() page_article = page_obj.paginate_queryset(queryset=book_list, request=request, view=self) # 序列化 bs = BookModelSerializers(instance=page_article, many=True, context={'request': request}) # 在做链接的时候需要添加context参数 # 返回分页 url return page_obj.get_paginated_response(bs.data)
查询单个:
class BookDetaiView(APIView): # inquire database def get(self, request, id, *args, **kwargs): book_list = Book.objects.filter(id=id) bs = BookModelSerializers(instance=book_list, many=True, context={'request': request}) # 在做链接的时候需要添加context参数 print(bs) # 默认就返回json格式的字符串 return Response(bs.data)
CursorPagination
分页规则:
加密分页,把上一页和下一页的id值记住
配置分页类:
# 加密分页 class MyCursorPagination(CursorPagination): cursor_query_param = 'cursor' # 查询的key值 page_size = 3 # #每页显示的大小 ordering = '-id' # 重写要排序的字段
视图:
查询所有:
class BookView(APIView): def get(self, request, *args, **kwargs): book_list = models.Book.objects.all().order_by("id") # 实例化产生一个偏移分页对象 page_obj = MyCursorPagination() page_article = page_obj.paginate_queryset(queryset=book_list, request=request, view=self) # 序列化 bs = BookModelSerializers(instance=page_article, many=True, context={'request': request}) # 在做链接的时候需要添加context参数 # # 去setting中配置每页显示多少条 return page_obj.get_paginated_response(bs.data)
查询单个:
class BookDetaiView(APIView): # inquire database def get(self, request, id, *args, **kwargs): book_list = models.Book.objects.filter(id=id) bs = BookModelSerializers(instance=book_list, many=True, context={'request': request}) # 在做链接的时候需要添加context参数 print(bs) # 默认就返回json格式的字符串 return Response(bs.data)
