可以用java、python、scala、R来编写spark程序,spark是用scala编写的,所以更推荐使用scala,而且scala开发效率较高,所以示例使用scala开发一个简单的spark程序。
1.开发环境准备
1.1安装scala
本示例的开发环境是win10+jdk1.8+scala2.11.8;scala程序需要运行在jvm中,安装scala前需要先安装jdk,然后到scala官网https://www.scala-lang.org/download/下载安装包进行安装。
1.2安装hadoop
在清华镜像站 https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.8.5/ 下载hadoop的安装包,下载完成后,解压,并配置环境变量HADOOP_HOME;
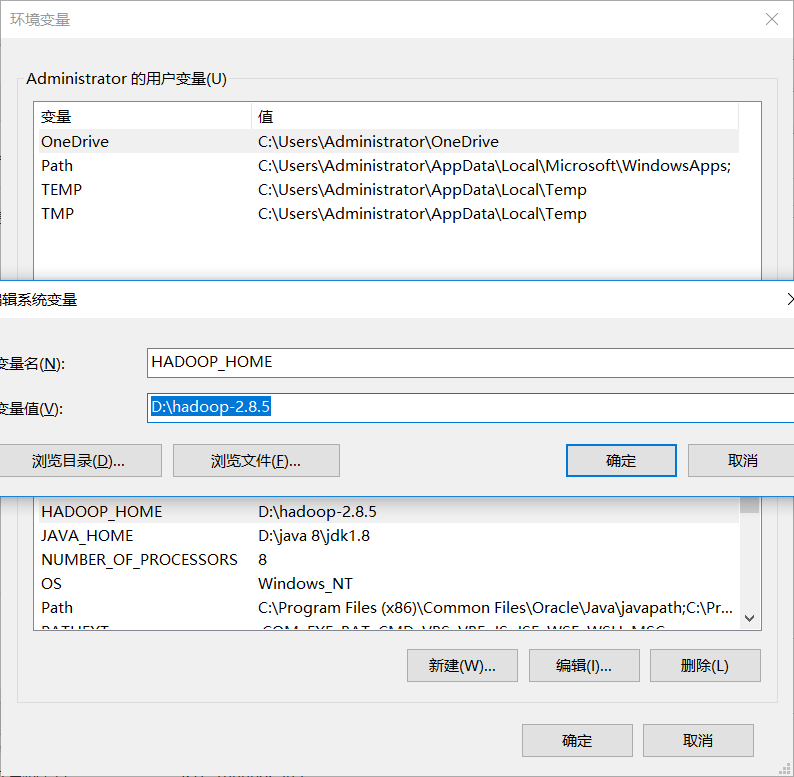
在github上 https://github.com/steveloughran/winutils 下载完整的包,并把对应hadoop/bin目录下的文件拷到hadoop的bin目录下。
1.3安装scala插件
目前idea对scala支持比较好,推荐使用idea开发scala程序;使用idea开发scala程序需要先安装scala的插件;
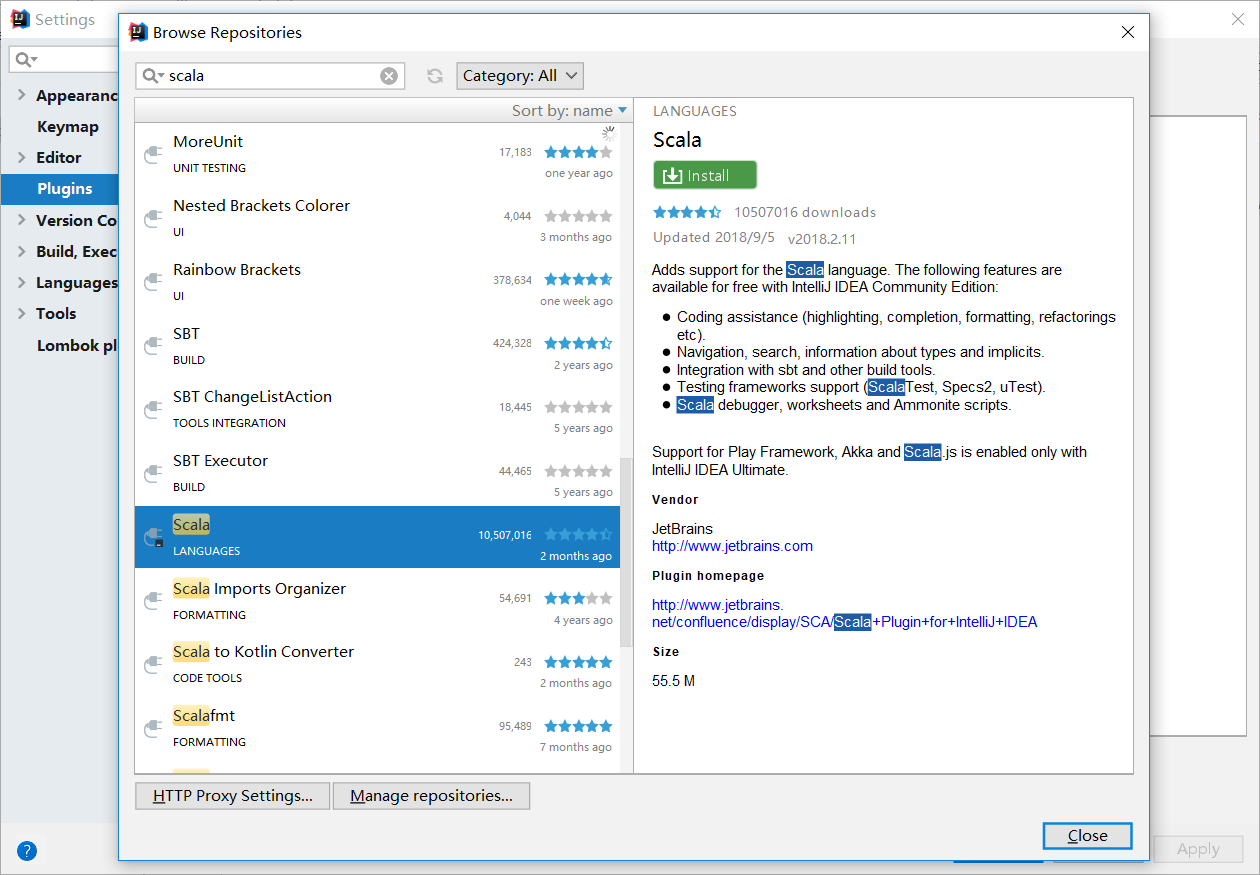
在http://plugins.jetbrains.com/plugin/1347-scala下载scala的插件后,在settings->plugins里点击install plugin from disk 安装插件,下载插件注意先查看自己的idea的版本,要下载与自己idea版本匹配的scala插件;网速好的也可以直接在plugins的仓库里搜索进行安装。
2.新建工程
2.1新建maven工程
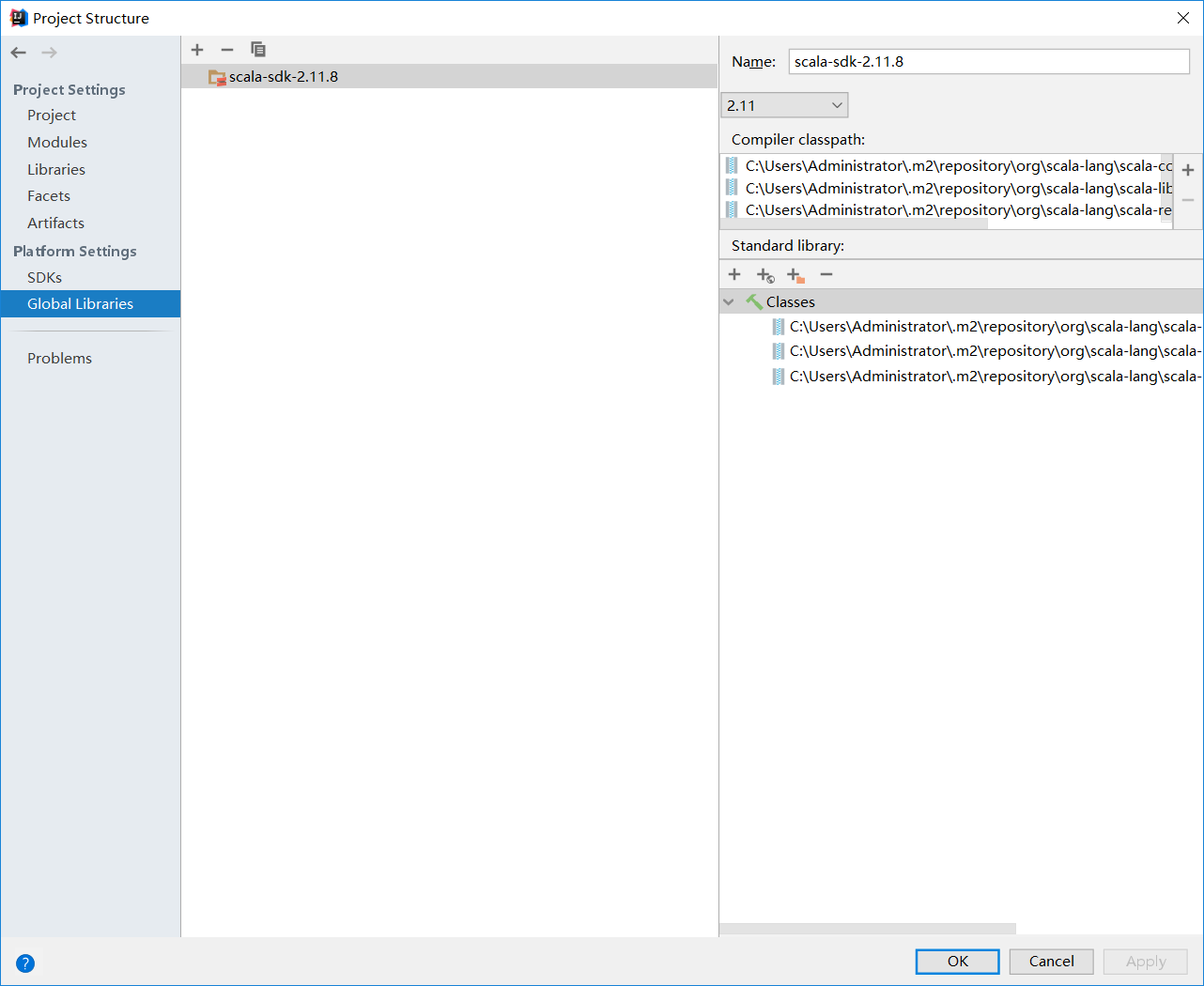
新建完成后,选中项目名称,按F4,在Global Libraries里点击"+"号,添加scala的sdk
2.2新建scala目录
添加完sdk后,在项目src\main目录下新建scala的目录;

然后按f4,打开Project Structure,将Moudles里面,将scala目录设置为source目录

2.3添加maven依赖
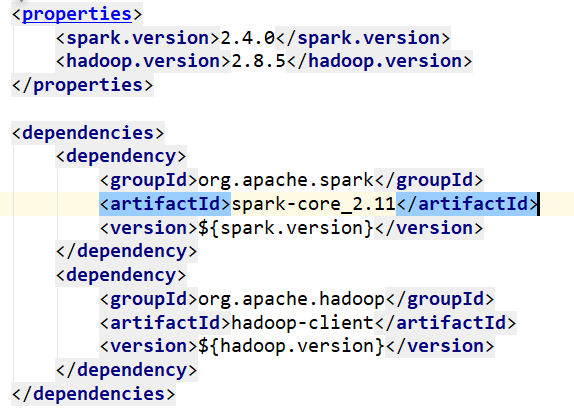
在dependency里加入如下依赖;(spark-core_2.11,这里的2.11指的是spark-core兼容scala的版本为2.11,这里的版本一定要与scala的版本对应,否则编译会报错)
3.开发
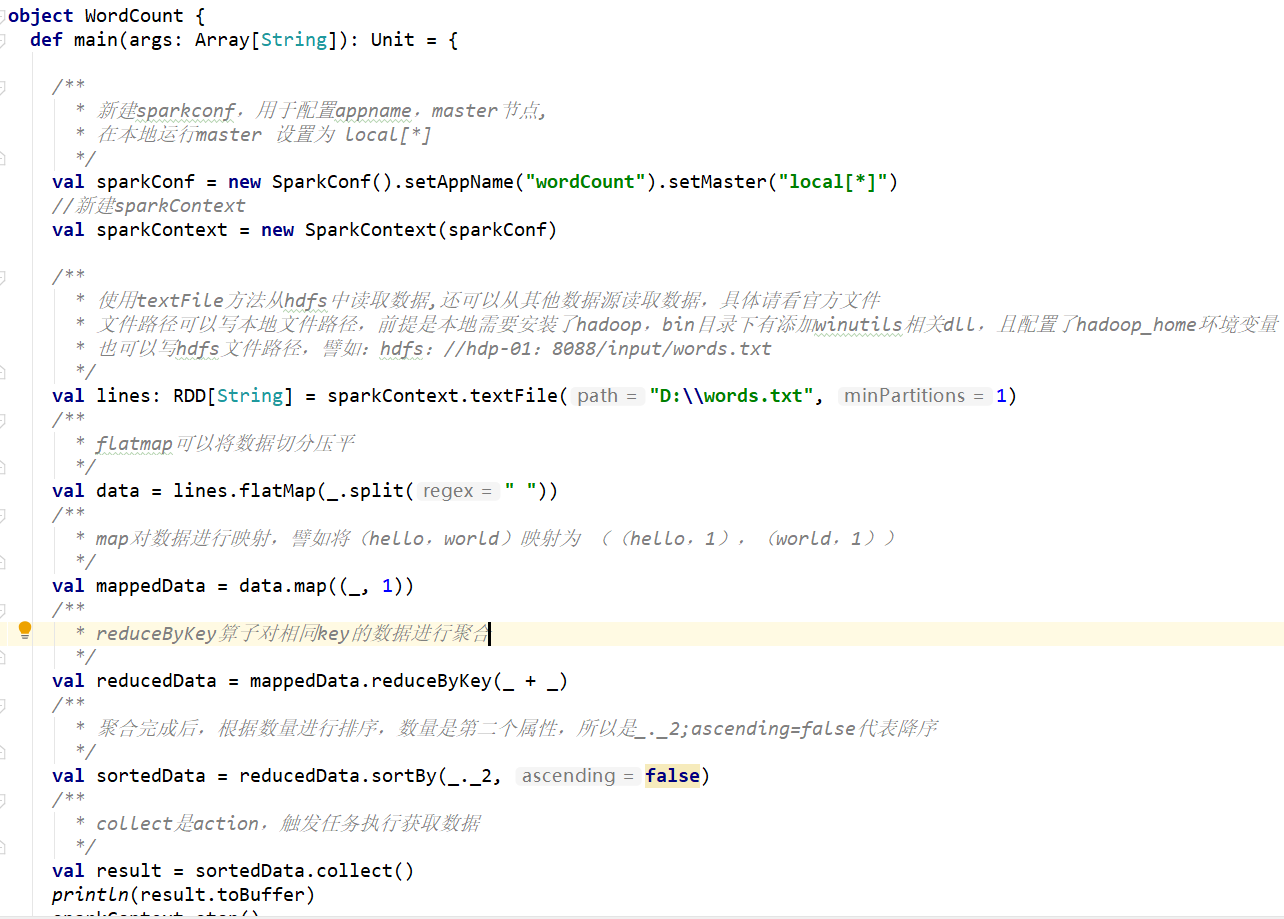
这里写一个简单的wordcount的示例。
3.1准备数据
新建一个txt文本文件,在里面输入若干单词,譬如这样:

3.2编码
新建一个scala object,命名为WordCount;

代码如下:
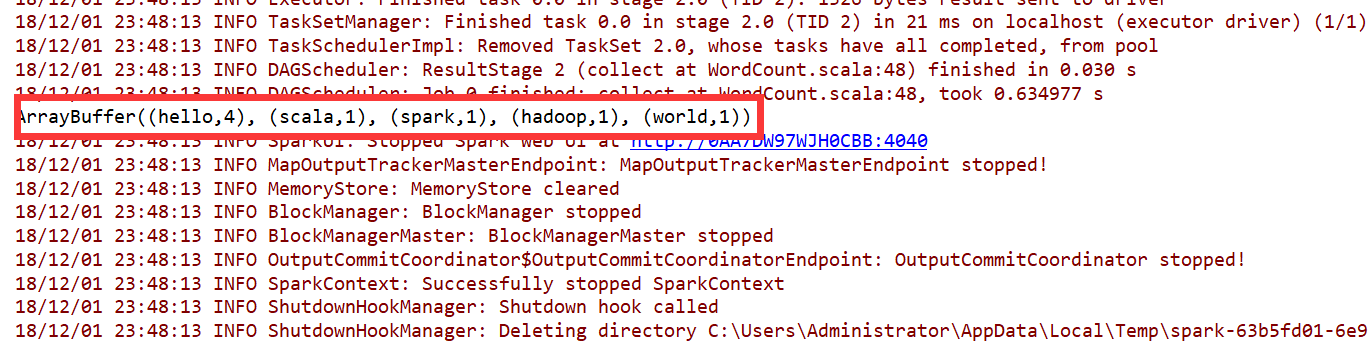
运行之后的结果:
完整代码已上传至GitHub https://github.com/wuyueming985/sparkdemos,里面注释详细,希望能帮助到初学者