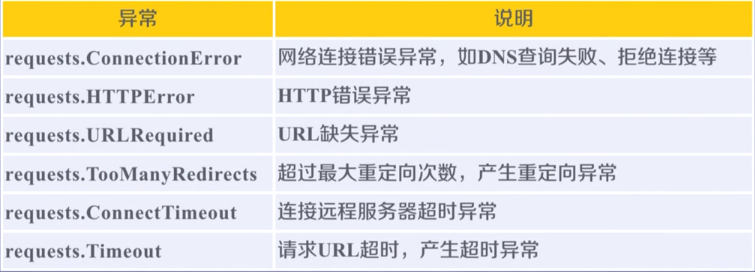
0x00 理解requests库的异常
requests库的异常:

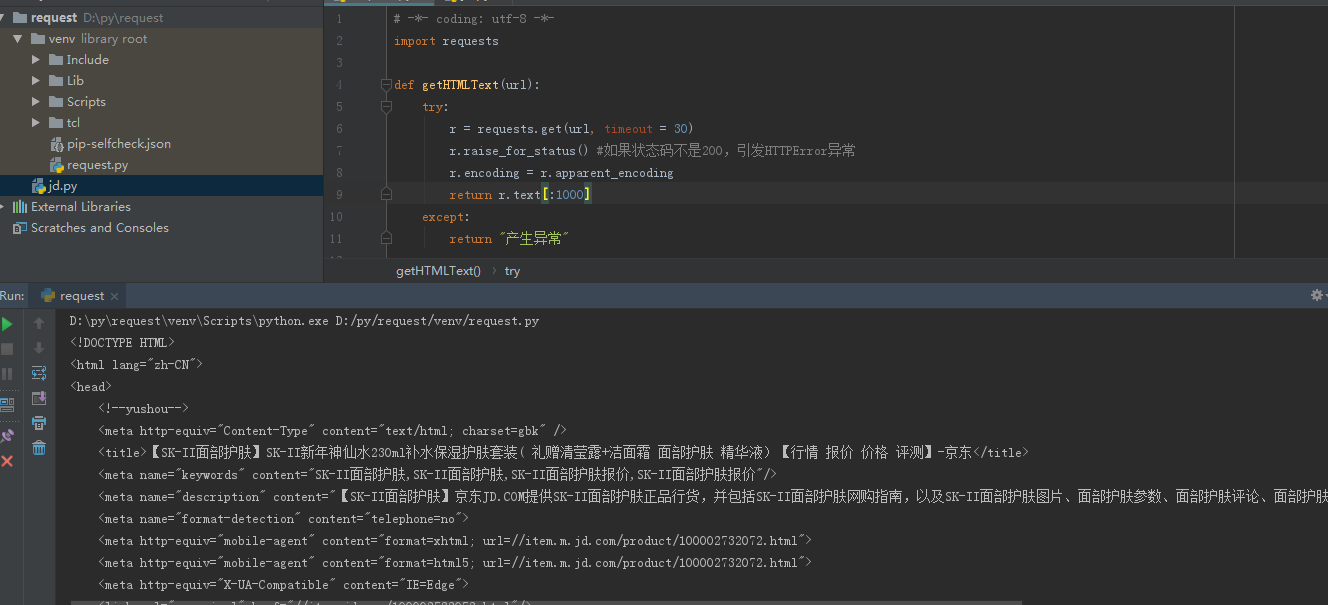
0x01 爬取网页的通用框架
import requests def getHTMLText(url): try: r = requests.get(url, timeout = 30) r.raise_for_status() #如果状态码不是200,引发HTTPError异常 r.encoding = r.apparent_encoding return r.text except: return "产生异常" if __name__ == "__main__": url = "********" print(getHTMLText(url))
实例1:对狗东某网页的简单爬取
首先对网页进行基本的判断,通过status_code、encoding方法查看网页

接着就是按照之前给的框架,将修改url进行爬取
实例2:百度、360参数提交
import requests kv = {'wd':'python'} def getHTMLText(url): try: r = requests.get(url,params=kv, timeout = 30) r.raise_for_status() #如果状态码不是200,引发HTTPError异常 r.encoding = r.apparent_encoding return r.text[:1000] except: return "产生异常" if __name__ == "__main__": url = "http://www.baidu.com/s" print(getHTMLText(url))
实例3:图片爬取
import requests import os url = "https://img2018.cnblogs.com/blog/1342178/201901/1342178-20190105195658548-1827989458.png" root = "D://pics//" path = root + url.split('/')[-1] #截取文件原名 try: if not os.path.exists(root): #判断根目录是否存在,不存在就建立新的根目录 os.mkdir(root) if not os.path.exists(path): #判断文件是否存在,不存在就从网上获取并下载 r = requests.get(url) with open(path, 'wb') as f: f.write(r.content) f.close() print("seccess") else: print("exist") except: print("fail")
实例4:IP地址归属地自动查询
import requests url = "http://www.ip138.com/ips138.asp?ip=" try: r = requests.get(url + "202.204.80.112") r.raise_for_status() r.encoding = r.apparent_encoding print(r.text[:5000]) except: print("fail")