我们使用Xpath来专门做一个scrapter
我们专门弄个文件夹 里面全部是 各个新闻源(CNN BBC等)的scraper来抓取网站的text内容


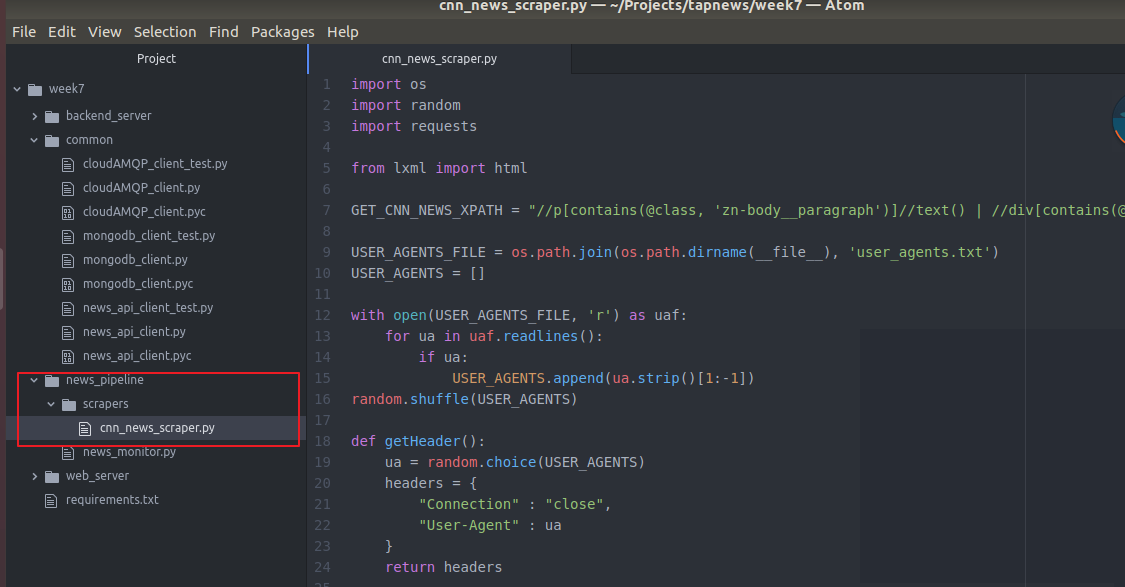
主要函数(就是传入text内容的那个url)然后进行抓取内容 返回 news 一会写具体内容

这个函数主要做3件事
首先 download 这个url 获取html
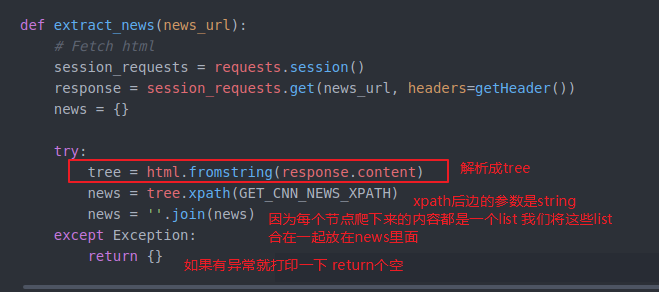
然后 parse html 成 tree
组合 extract information(提取信息 用Xpath或者后边自动爬内容的 第三方库 newspaper) 这里我们现用Xpath 后边再优化

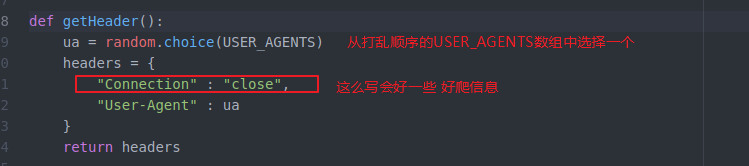
进行2次伪装

下一步就是伪装header

这里需要一个 我们自己准备一个useragent的list表 每次随机从里面选一个 作为我们的useragend header
有了表 我们就要用这个表



最后再用random重新洗牌

然后 通过上面伪装的2个 去请求目标url 返回目标url的内容text 用response接收

网站获得我们的请求 查看我们的session和header就会
认为我们是正常的用户 不是机器人就会返回我们要的text 我们 就可以一直爬信息 不然就会被认为是机器人 而被拒绝或者封ip
我们获得了目标url的html
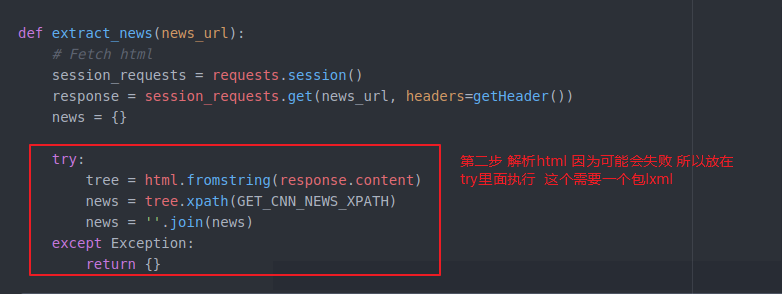
就开始做第二步了 解析这个html
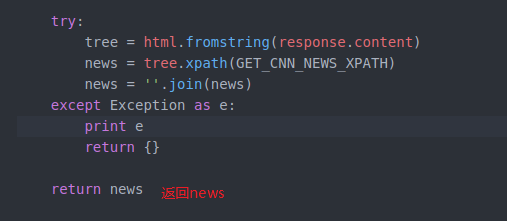
我们把他放在try里面 即使失误了 也可以跳过执行后边的程序 不至于导致不work

这个包安装一下


写入文件
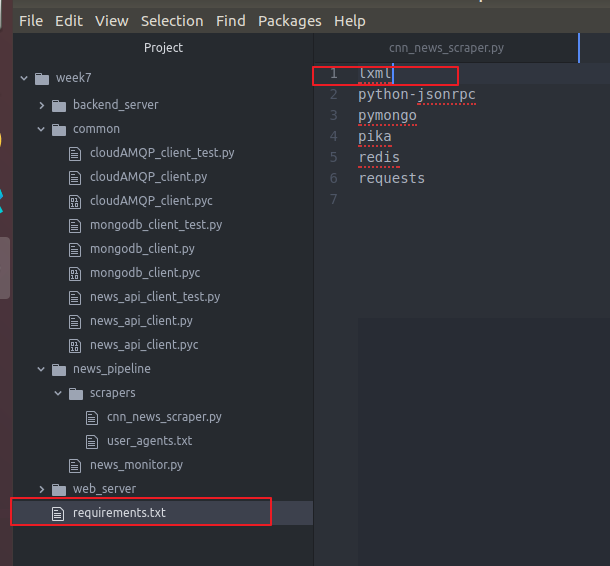


GET_CNN_NEWS_XPATH = "//p[contains(@class, 'zn-body__paragraph')]//text() | //div[contains(@class, 'zn-body__paragraph')]//text()"
里面//就是不管结构 就是对所有的节点都有效 p就是p标签 contains就是包含 (cnn网站的内容) // text()获得text | 组合(加上)后边根据条件获得div快内的text()内容拼接
这个string内容(绿色)是咋来的呢?其实是我们自己弄来的 根据cnn这个具体新闻页面(找到我们要的text内容的部分,不过几千行不好找),我们从第一个Q里面获得我们news monotor抓的新闻摘要,从里面找到我们将来要爬的url

http://us.cnn.com/2018/09/06/politics/the-25th-amendment-requires-political-apocalypse/index.html
打开看看
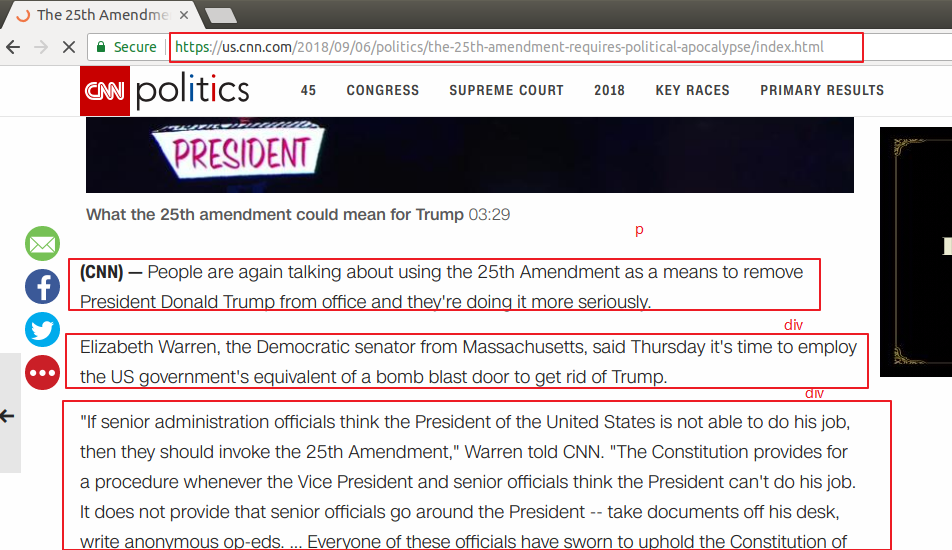
虽然这样也可以找到但是总归是要自己进去一层层找还是比较麻烦的
所以我们用解析工具(获取绿字内容)他的用法也很简单

安装这个插件

使用方法
https://chrome.google.com/webstore/detail/xpath-helper/hgimnogjllphhhkhlmebbmlgjoejdpjl
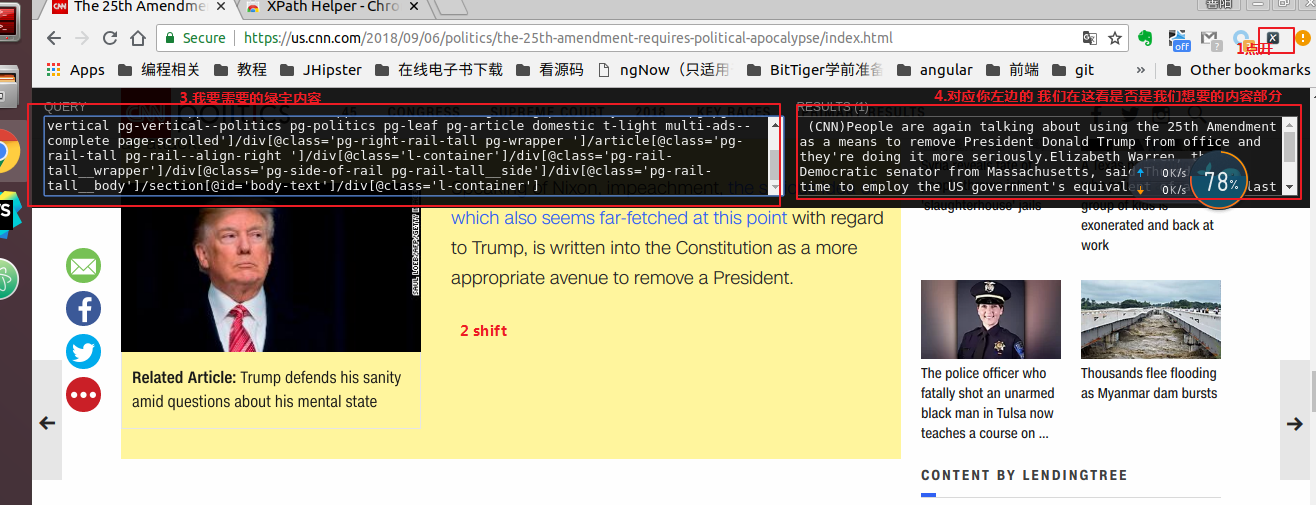
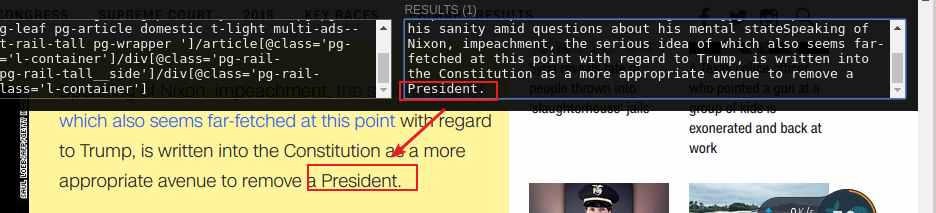
还是很方便的
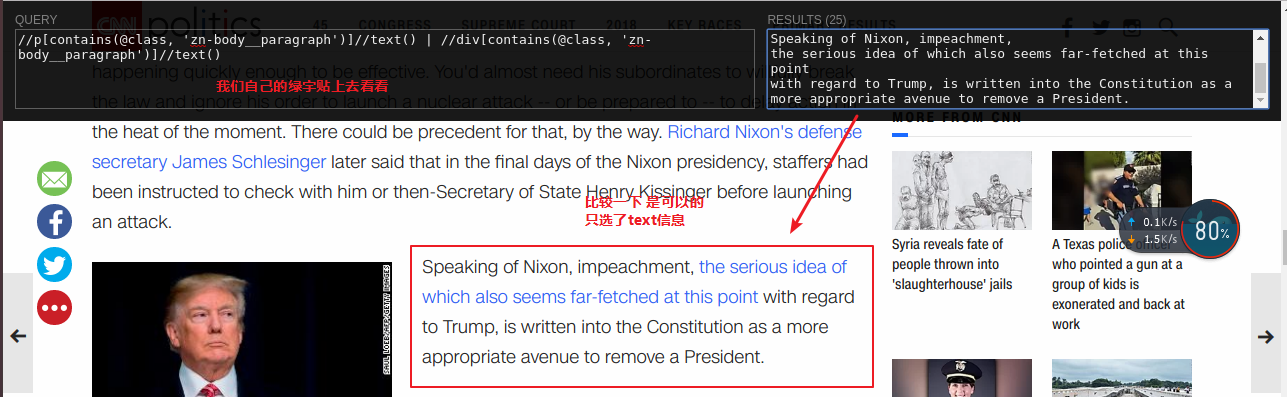
我们就是通过这样获取的XPATH
下面我们还是测试一下我的news scraper

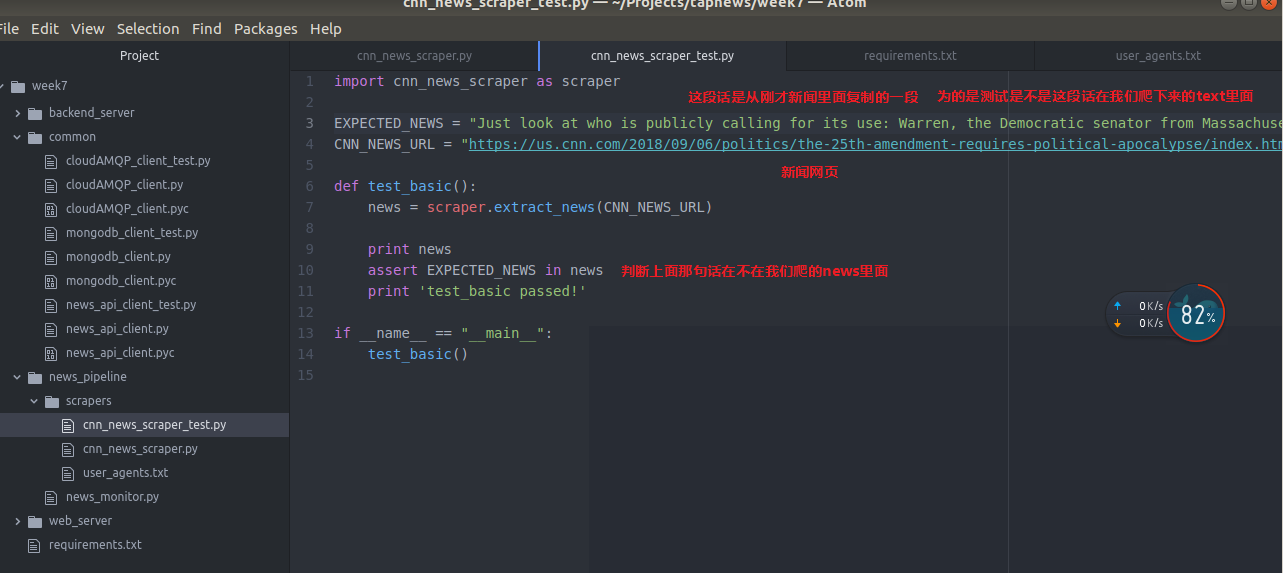
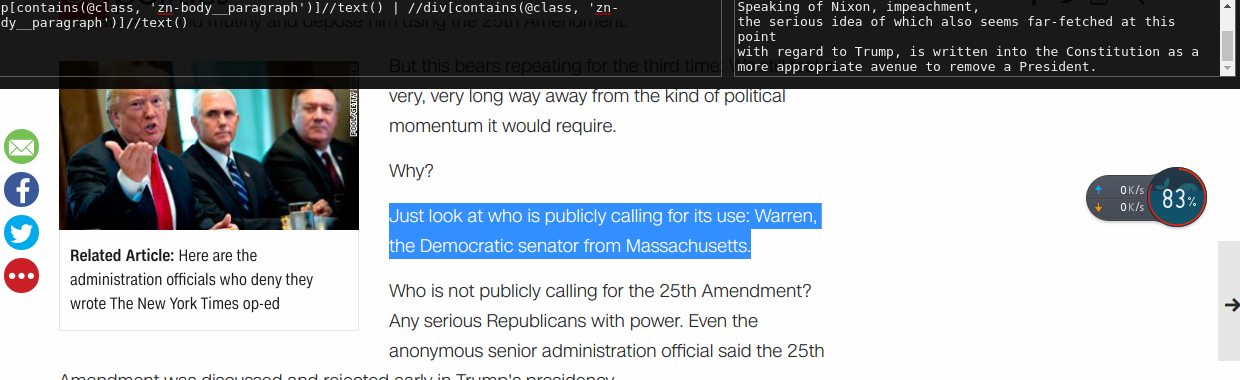
下面跑一跑
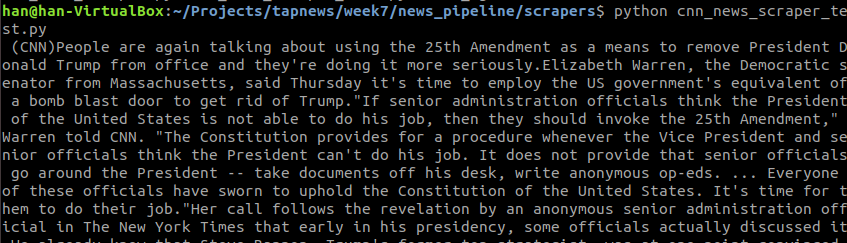

我们发现 过程很复杂 而且每个网站都不一样
你要每一个source都要写一个对应的scraper
因为结构不同嘛
XPATH不同 当然
你也可以写一个scraper 运行不同XPATH
上面我们只是抓取到了新闻text
和Q相关的操作我们还没做
下面是 news fetcher 其实和news monitor 差不多
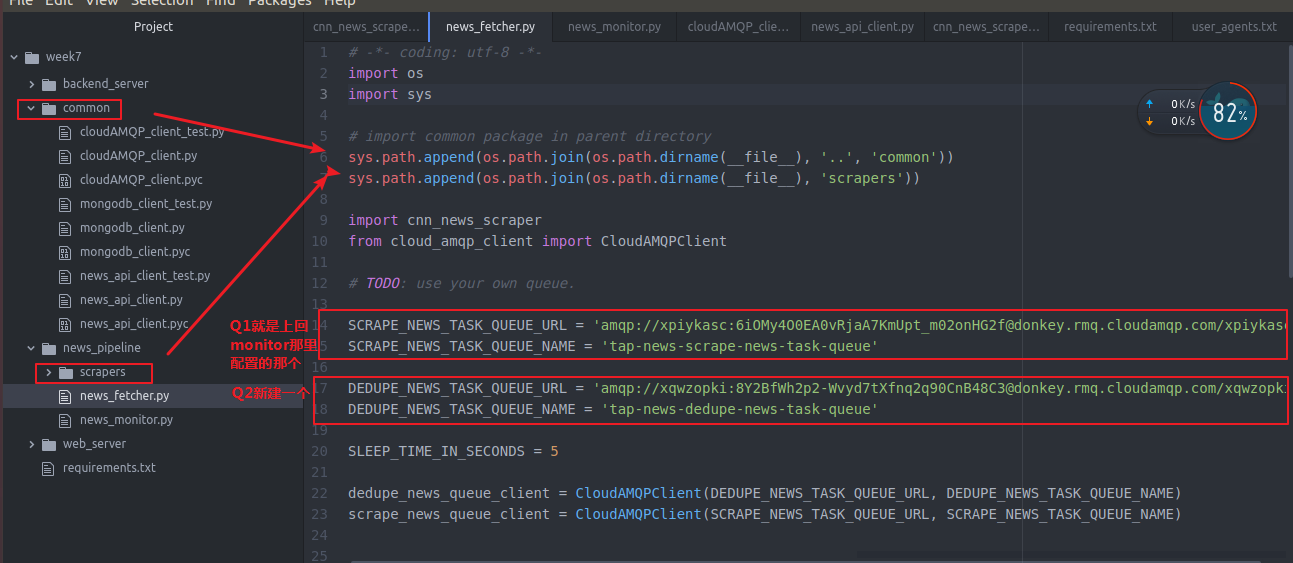

新建一个新的Q2和上次创建q一模一样
week7_demo_second_queue
干脆名字对应吧




我们去看看

所以 我们判断一下源是 cnn我们在进行下面操作


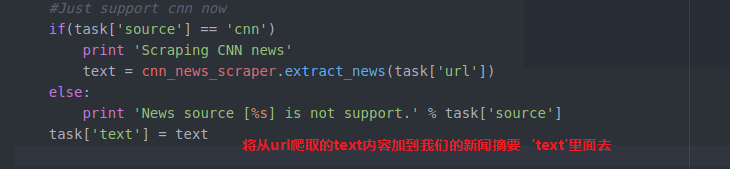

我们来试试

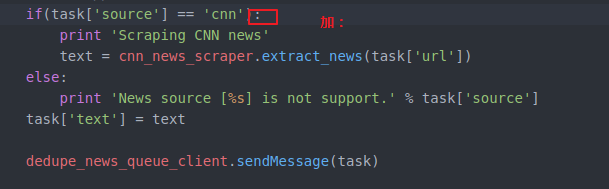

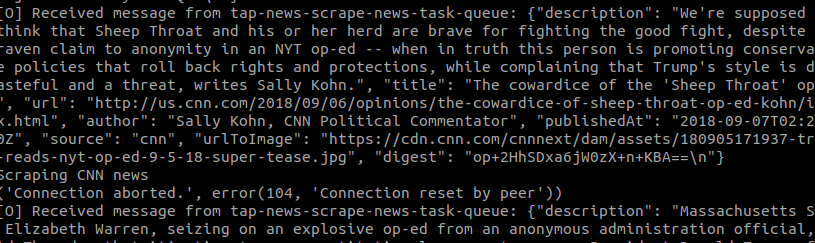
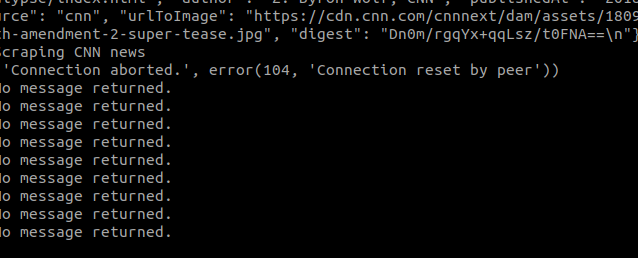
OK