一、简介
Redis是一个开源的 key-value 存储系统,它使用六种底层数据结构构建了包含字符串对象、列表对象、哈希对象、集合对象和有序集合对象的对象系统。今天我们就通过12张图来全面了解一下它的数据结构和对象系统的实现原理。
本文的内容如下:
-
首先介绍六种基础数据结构:动态字符串,链表,字典,跳跃表,整数集合、快速链表和压缩列表(实际上还有前缀压缩树)。
-
其次介绍 Redis 的对象系统中的字符串对象(String)、列表对象(List)、哈希对象(Hash)、集合对象(Set)和有序集合对象(ZSet)(实际上还有流(Stream))。
-
最后介绍 Redis 的键空间和过期键( expire )实现。
二、数据结构
2.1 简单动态字符串(sds)
2.1.1 结构体中的成员
Redis 使用动态字符串 SDS 来表示字符串值。下图展示了一个值为 Redis 的 SDS结构 :
-
len: 表示字符串的真正长度(不包含NULL结束符在内)。
-
alloc: 表示字符串的最大容量(不包含最后多余的那个字节)。
-
flags: 总是占用一个字节。其中的最低3个bit用来表示header的类型。
-
buf: 字符数组。

2.1.2 SDS 的优点
SDS 的结构可以减少修改字符串时带来的内存重分配的次数,这依赖于内存预分配和惰性空间释放两大机制。
2.1.2.1 内存预分配
当 SDS 需要被修改,并且要对 SDS 进行空间扩展时,Redis 不仅会为 SDS 分配修改所必须要的空间,还会为 SDS 分配额外的未使用的空间。
-
如果修改后, SDS 的长度(也就是len属性的值)将小于 1MB ,那么 Redis 预分配和 len 属性相同大小的未使用空间。
-
如果修改后, SDS 的长度将大于 1MB ,那么 Redis 会分配 1MB 的未使用空间。
比如说,进行修改后 SDS 的 len 长度为20字节,小于 1MB,那么 Redis 会预先再分配 20 字节的空间, SDS 的 buf数组的实际长度(除去最后一字节)变为 20 + 20 = 40 字节。当 SDS的 len 长度大于 1MB时,则只会再多分配 1MB的空间。
2.1.2.2 惰性空间释放
类似的,当 SDS 缩短其保存的字符串长度时,并不会立即释放多出来的字节,而是等待之后使用。
2.2 链表
链表在 Redis 中的应用非常广泛,比如列表对象的底层实现之一就是链表。除了链表对象外,发布和订阅、慢查询、监视器等功能也用到了链表。

Redis 的链表是双向链表,示意图如上图所示。链表是最为常见的数据结构,这里就不在细说。
Redis 的链表结构的dup 、 free 和 match 成员属性是用于实现多态链表所需的类型特定函数:
-
dup 函数用于复制链表节点所保存的值,用于深度拷贝。
-
free 函数用于释放链表节点所保存的值。
-
match 函数则用于对比链表节点所保存的值和另一个输入值是否相等。
2.3 字典
2.3.1 字典的结构
字典被广泛用于实现 Redis 的各种功能,包括键空间和哈希对象。其示意图如下所示。
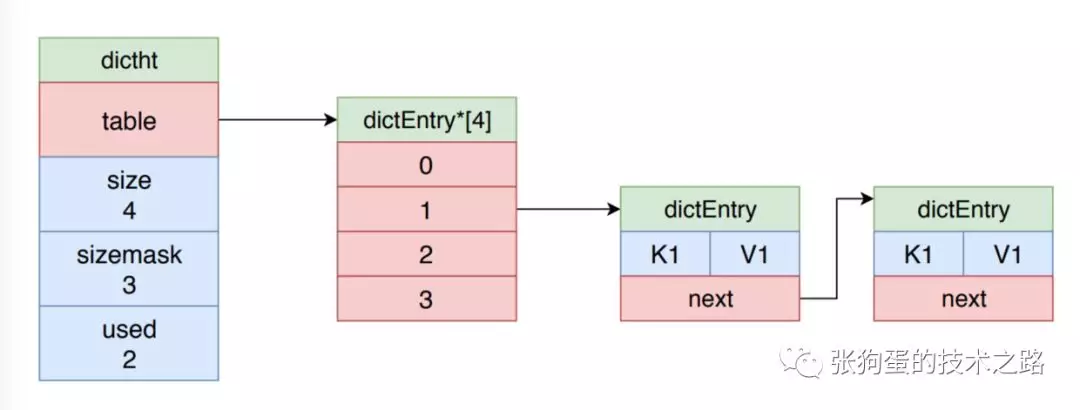
2.3.2 字典的哈希算法
Redis 使用 MurmurHash2 算法来计算键的哈希值,并且使用链地址法来解决键冲突,被分配到同一个索引的多个键值对会连接成一个单向链表。
2.3.3 MurmurHash2 算法
MurmurHash算法由Austin Appleby发明于2008年,是一种非加密hash算法,适用于基于hash查找的场景。murmurhash最新版本是MurMurHash3,支持32位,64位及128位值的产生。
MurmurHash标准使用C++实现,但是也有其他主流语言的支持版本,包括:perl、C#、ruby、python、java等。这种算法即使输入的键是有规律的,算法仍能给出一个很好的随机分布性,计算速度非常快,使用简单。因此在多个开源项目中得到应用,包括libstdc、libmemcached、nginx、hadoop等。
Redis使用的是MurmurHash2。当字典被用作数据库的底层实现,或者哈希键的底层实现时,使用MurmurHash2算法来计算键的哈希值。详细请看https://www.cnblogs.com/MrLiuZF/p/15007223.html。
2.4 跳跃表
2.4.1 跳跃表结构
Redis 使用跳跃表作为有序集合对象的底层实现之一。它以有序的方式在层次化的链表中保存元素, 效率和平衡树媲美 —— 查找、删除、添加等操作都可以在对数期望时间下完成, 并且比起平衡树来说, 跳跃表的实现要简单直观得多。
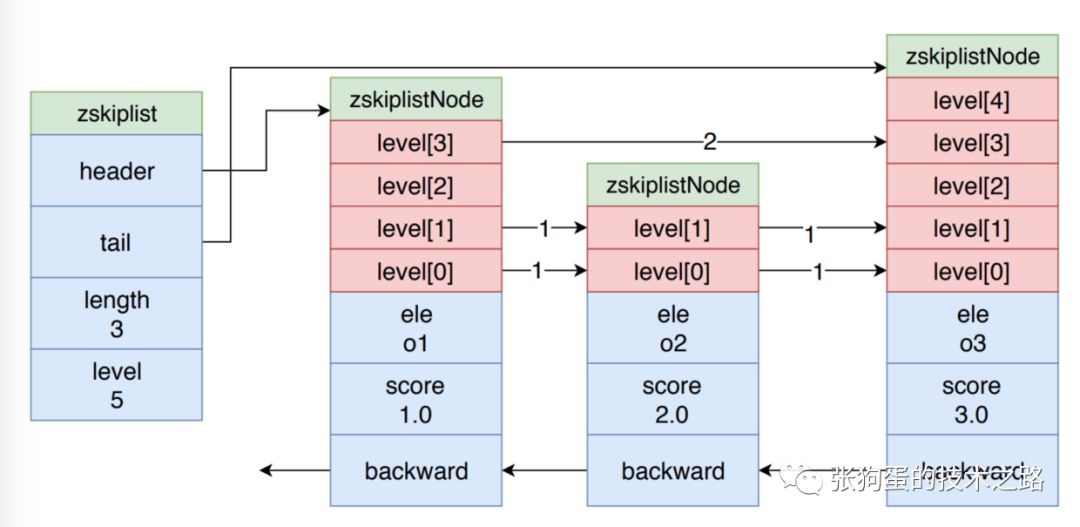
2.4.2 跳跃表实现原理
跳表的示意图如上图所示,这里只简单说一下它的核心思想,并不进行详细的解释。
如示意图所示,zskiplistNode 是跳跃表的节点,其 ele 是保持的元素值,score 是分值,节点按照其 score 值进行有序排列,而 level 数组就是其所谓的层次化链表的体现。
每个 node 的 level 数组大小都不同, level 数组中的值是指向下一个 node 的指针和跨度值 (span),跨度值是两个节点的score的差值。越高层的 level 数组值的跨度值就越大,底层的 level 数组值的跨度值越小。
level 数组就像是不同刻度的尺子。度量长度时,先用大刻度估计范围,再不断地用缩小刻度,进行精确逼近。
2.4.3 跳跃表的查询
当在跳跃表中查询一个元素值时,都先从第一个节点的最顶层的 level 开始。比如说,在上图的跳表中查询 o2 元素时,先从o1 的节点开始,因为 zskiplist 的 header 指针指向它。
先从其 level[3] 开始查询,发现其跨度是 2,o1 节点的 score 是1.0,所以加起来为 3.0,大于 o2 的 score 值2.0。所以,我们可以知道 o2 节点在 o1 和 o3 节点之间。这时,就改用小刻度的尺子了。就用level[1]的指针,顺利找到 o2 节点。
下一层的跨度一定比上一层要小,最后一层包含所有元素。
2.5 整数集合
整数集合 intset 是集合对象的底层实现之一,当一个集合只包含整数值元素,并且这个集合的元素数量不多时, Redis 就会使用整数集合作为集合对象的底层实现。

如上图所示,整数集合的 encoding 表示它的类型,有int16t,int32t 或者int64_t。其每个元素都是 contents 数组的一个数组项,各个项在数组中按值的大小从小到大有序的排列,并且数组中不包含任何重复项。length 属性就是整数集合包含的元素数量。
2.6 压缩列表
压缩列表 ziplist 是列表对象和哈希对象的底层实现之一。当满足一定条件时,列表对象和哈希对象都会以压缩队列为底层实现。

压缩队列是 Redis 为了节约内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型数据结构。它的属性值有:
-
zlbytes : 长度为 4 字节,记录整个压缩数组的内存字节数。
-
zltail : 长度为 4 字节,记录压缩队列表尾节点距离压缩队列的起始地址有多少字节,通过该属性可以直接确定尾节点的地址。
-
zllen : 长度为 2 字节,包含的节点数。当属性值小于 INT16_MAX时,该值就是节点总数,否则需要遍历整个队列才能确定总数。
-
zlend : 长度为 1 字节,特殊值,用于标记压缩队列的末端。
中间每个节点 entry 由三部分组成:
-
previous_entry_length : 压缩列表中前一个节点的长度,和当前的地址进行指针运算,计算出前一个节点的起始地址。
-
encoding: 节点保存数据的类型和长度
-
content :节点值,可以为一个字节数组或者整数。
2.7 快速列表(quicklist)
2.7.1 快速列表结构
quicklist结构是在redis 5.0.2版本中用在列表的底层实现。

2.7.2 快速列表实现原理
quicklist结构在quicklist.c中的解释为A doubly linked list of ziplists意思为一个由ziplist组成的双向链表。quicklist是由ziplist组成的双向链表,链表中的每一个节点都以压缩列表ziplist的结构保存着数据,而ziplist有多个entry节点,保存着数据。相当与一个quicklist节点保存的是一片数据,而不再是一个数据。
2.7.3 快速列表优点
压缩列表的特点:
- 压缩列表ziplist结构本身就是一个连续的内存块,由表头、若干个entry节点和压缩列表尾部标识符zlend组成,通过一系列编码规则,提高内存的利用率,使用于存储整数和短字符串。
- 压缩列表ziplist结构的缺点是:每次插入或删除一个元素时,都需要进行频繁的调用realloc()函数进行内存的扩展或减小,然后进行数据”搬移”,甚至可能引发连锁更新,造成严重效率的损失。
总结出一下quicklist的特点:
- quicklist宏观上是一个双向链表,因此,它具有一个双向链表的有点,进行插入或删除操作时非常方便,虽然复杂度为O(n),但是不需要内存的复制,提高了效率,而且访问两端元素复杂度为O(1)。
- quicklist微观上是一片片entry节点,每一片entry节点内存连续且顺序存储,可以通过二分查找以 log2(n)的复杂度进行定位。
三、Redis 对象系统
3.1 介绍
redis中基于双端链表、简单动态字符串(sds)、字典、跳跃表、整数集合、压缩列表、快速列表等等数据结构实现了一个对象系统,并且实现了5种不同的对象,每种对象都使用了至少一种前面的数据结构,优化对象在不同场合下的使用效率。
3.2 对象的系统的实现
上面介绍了7种底层数据结构,Redis 并没有直接使用这些数据结构来实现键值数据库,而是基于这些数据结构创建了一个对象系统,这个系统包含字符串对象、列表对象、哈希对象、集合对象、有序集合以及流Stream这六种类型的对象,每个对象都使用到了至少一种前边讲的底层数据结构。
Redis 根据不同的使用场景和内容大小来判断对象使用哪种数据结构,从而优化对象在不同场景下的使用效率和内存占用。
3.2.1 对象的结构
3.2.1.1 对象结构robj的功能
- 为6种不同的对象类型提供同一的表示形式。
- 为不同的对象针对不同的场景提供合适底层数据结构,也就是支持同一种对象类型采用多种的数据结构方式。
- 支持引用计数,实现对象共享机制(整数)。
- 记录对象的访问时间,便于删除对象。
3.2.1.2 对象结构robj的定义
对象结构定义在redis 5.0.2版本的server.h,大小是4bit+4bit+24bit+4Byte+8Byte=16Byte。
1 /**
2 * Objects encoding. Some kind of objects like Strings and Hashes can be
3 * internally represented in multiple ways. The 'encoding' field of the object
4 * is set to one of this fields for this object.
5 * encoding 的11种类型
6 */
7 //原始表示方式,字符串对象是简单动态字符串
8 #define OBJ_ENCODING_RAW 0 /* Raw representation */
9 //long类型的整数
10 #define OBJ_ENCODING_INT 1 /* Encoded as integer */
11 //字典
12 #define OBJ_ENCODING_HT 2 /* Encoded as hash table */
13 //不在使用
14 #define OBJ_ENCODING_ZIPMAP 3 /* Encoded as zipmap */
15 //双端链表,不在使用
16 #define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. */
17 //压缩列表
18 #define OBJ_ENCODING_ZIPLIST 5 /* Encoded as ziplist */
19 //整数集合
20 #define OBJ_ENCODING_INTSET 6 /* Encoded as intset */
21 //跳跃表和字典
22 #define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
23 //embstr编码的简单动态字符串
24 #define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
25 //由使用压缩算法的压缩列表或未使用压缩算法的压缩列表组成的双向列表-->快速列表
26 #define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of ziplists */
27 //Stream(流对象)的底层存储结构为前缀压缩树
28 #define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks */
29
30 #define LRU_BITS 24
31 #define LRU_CLOCK_MAX ((1<<LRU_BITS)-1) /* Max value of obj->lru */
32 #define LRU_CLOCK_RESOLUTION 1000 /* LRU clock resolution in ms */
33
34 #define OBJ_SHARED_REFCOUNT INT_MAX
35 /**
36 * https://blog.csdn.net/qq_35433716/article/details/82179168
37 * type:存储对象的类型,Redis中有5中数据类型:String,List,Hash,Set,Zset,
38 * 可以通过 type {key}命令查看对象的类型,返回的是值对象类型,所有的key对象都是String类型
39 * encoding:数据存储的Redis中后采用的是那种内部编码格式,这个后边会细讲一下
40 * lru:记录的是对象被最后一次访问的时间,当配置了maxmemory之后,配合LRU算法对相关的key值进行删除,
41 * 可以通过object idletime {key}查看key最近一次被访问的时间。
42 * 也可以通过scan + object idletime命令批量查询那些键长时间没有被使用,从而可以删除长时间没有被使用的键值,
43 * 减少内存的占用。
44 * refcount:记录当前对象被引用的次数。根据当前字段来判断该对象时候可回收,当refcount为0时,
45 * 可安全进行对象的回收,可以使用object refcount {key}查看当前对象引用。
46 * ptr:与对象的数据内容有关。如果是整数,则直接存储数据(这个地方可以了解下共享对象池,
47 * 当对象为整数且范围在【0-9999】,会直接存储到共享对象池中),其他类型的数据次字段则代表的是指针。
48 * redisObject的结构与对象类型、编码、内存回收、共享对象都有关系;一个redisObject对象的大小为16字节:
49 * 4bit+4bit+24bit+4Byte+8Byte=16Byte。
50 */
51 typedef struct redisObject {
52 unsigned type:4;
53 unsigned encoding:4;
54 unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
55 * LFU data (least significant 8 bits frequency
56 * and most significant 16 bits access time). */
57 int refcount;
58 void *ptr;
59 } robj;
3.2.1.3 对象结构robj的类型
其中 type 是对象类型,如下
1 /* The actual Redis Object 7中对象类型*/
2 #define OBJ_STRING 0 /* String object. 字符串*/
3 #define OBJ_LIST 1 /* List object. 链表*/
4 #define OBJ_SET 2 /* Set object. 集合*/
5 #define OBJ_ZSET 3 /* Sorted set object. 有序集合*/
6 #define OBJ_HASH 4 /* Hash object. 哈希表*/
7
8 /* The "module" object type is a special one that signals that the object
9 * is one directly managed by a Redis module. In this case the value points
10 * to a moduleValue struct, which contains the object value (which is only
11 * handled by the module itself) and the RedisModuleType struct which lists
12 * function pointers in order to serialize, deserialize, AOF-rewrite and
13 * free the object.
14 *
15 * Inside the RDB file, module types are encoded as OBJ_MODULE followed
16 * by a 64 bit module type ID, which has a 54 bits module-specific signature
17 * in order to dispatch the loading to the right module, plus a 10 bits
18 * encoding version. */
19 #define OBJ_MODULE 5 /* Module object. */
20 #define OBJ_STREAM 6 /* Stream object. 流对象*/
3.3 字符串对象
3.3.1 字符串对象的底层实现
大小是4byte,定义如下:
1 struct __attribute__ ((__packed__)) sdshdr8 {
2 uint8_t len; /* used len表示的是sds字符串的当前长度*/
3 uint8_t alloc; /* excluding the header and null terminator 表示的是buf的总长度。*/
4 unsigned char flags; /* 3 lsb of type, 5 unused bits 前3位代表类型,后5位未使用*/
5 char buf[];
6 };
我们首先来看字符串对象的实现,如下图所示。
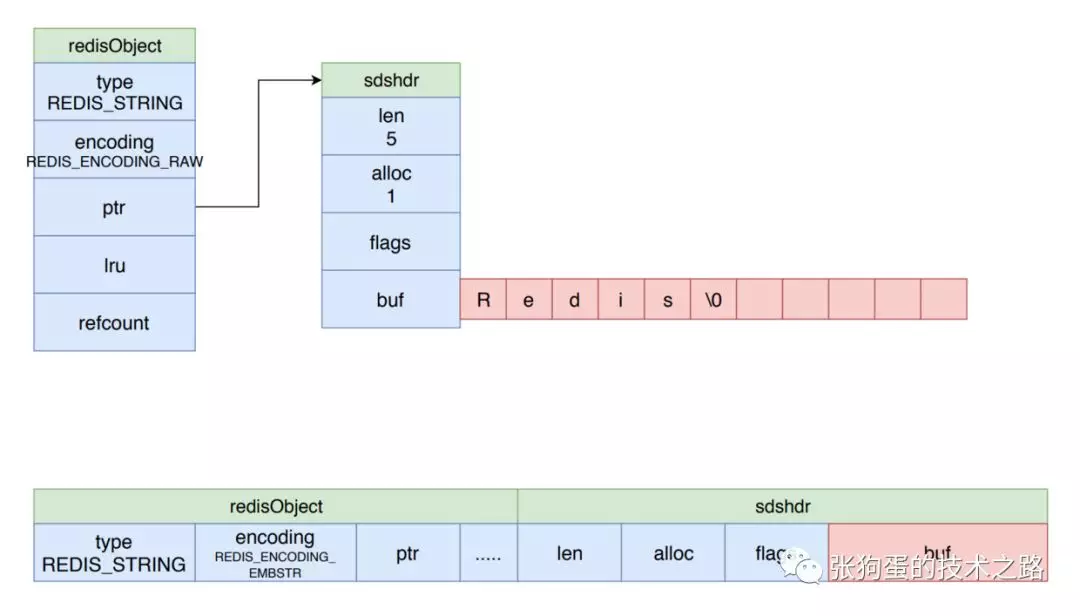
3.3.2 字符串对象的编码类型
如果一个字符串对象保存的是一个字符串值,并且长度大于44字节,那么该字符串对象将使用 SDS 进行保存,并将对象的编码设置为 raw,如图的上半部分所示。如果字符串的长度小于32字节,那么字符串对象将使用embstr 编码方式来保存。
embstr 编码是专门用于保存短字符串的一种优化编码方式,这个编码的组成和 raw 编码一致,都使用 redisObject 结构和 sdshdr 结构来保存字符串,如上图的下半部所示。
但是 raw 编码会调用两次内存分配来分别创建上述两个结构,而 embstr 则通过一次内存分配来分配一块连续的空间,空间中一次包含两个结构。
embstr 只需一次内存分配,而且在同一块连续的内存中,更好的利用缓存带来的优势,但是 embstr 是只读的,不能进行修改,当一个 embstr 编码的字符串对象进行 append 操作时, redis 会现将其转变为 raw 编码再进行操作。
| 编码—encoding | 对象—ptr |
|---|---|
| OBJ_ENCODING_RAW | 简单动态字符串实现的字符串对象 |
| OBJ_ENCODING_INT | 整数值实现的字符串对象 |
| OBJ_ENCODING_EMBSTR | embstr编码的简单动态字符串实现的字符串对象 |
3.4 列表对象
3.4.1 列表对象的底层实现类型
列表对象的编码可以是 ziplist 或 linkedlist。其示意图如下所示。
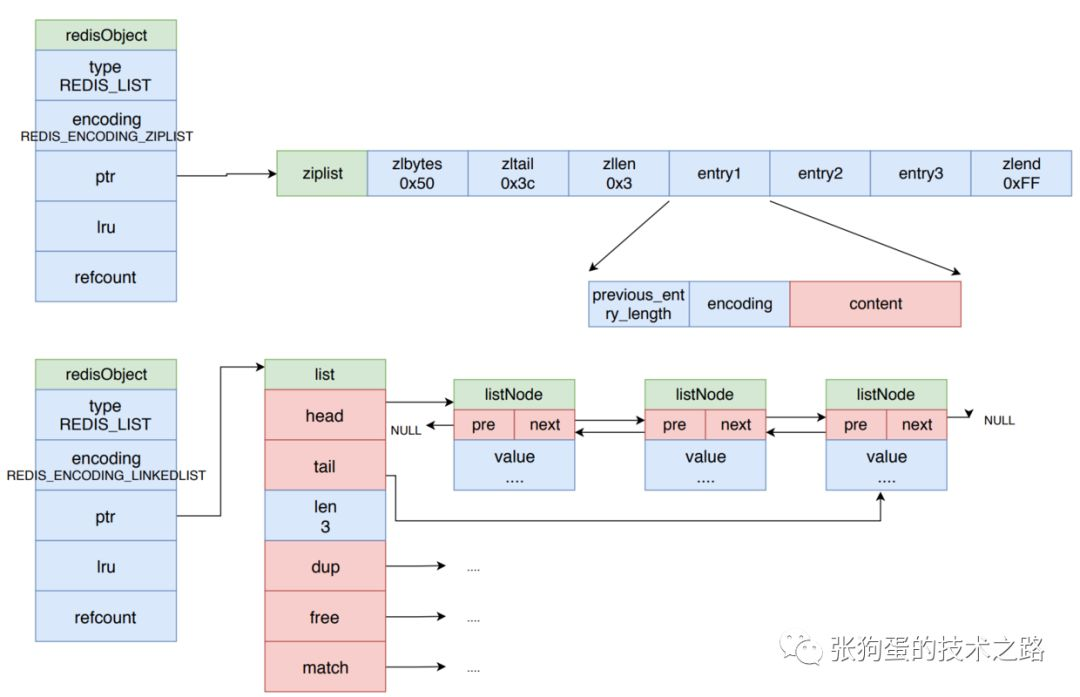
3.4.2 列表对象的编码
3.4.2.1 ziplist 编码
当列表对象可以同时满足以下两个条件时,列表对象使用 ziplist 编码:
-
列表对象保存的所有字符串元素的长度都小于 64 字节。
-
列表对象保存的元素数量数量小于 512 个。
3.4.2.2 quicklist 编码
不能满足这两个条件的列表对象需要使用 linkedlist 编码或者转换为 linkedlist 编码。
| 编码—encoding | 对象—ptr |
|---|---|
| OBJ_ENCODING_QUICKLIST | 快速列表实现的列表对象 |
| OBJ_ENCODING_ZIPLIST | 压缩列表实现的列表对象 |
3.5 集合对象
3.5.1 集合对象的底层实现类型
集合对象的编码可以使用 intset 或者 dict。
intset 编码的集合对象使用整数集合最为底层实现,所有元素都被保存在整数集合里边。
而使用 dict 进行编码时,字典的每一个键都是一个字符串对象,每个字符串对象就是一个集合元素,而字典的值全部都被设置为NULL。如下图所示。
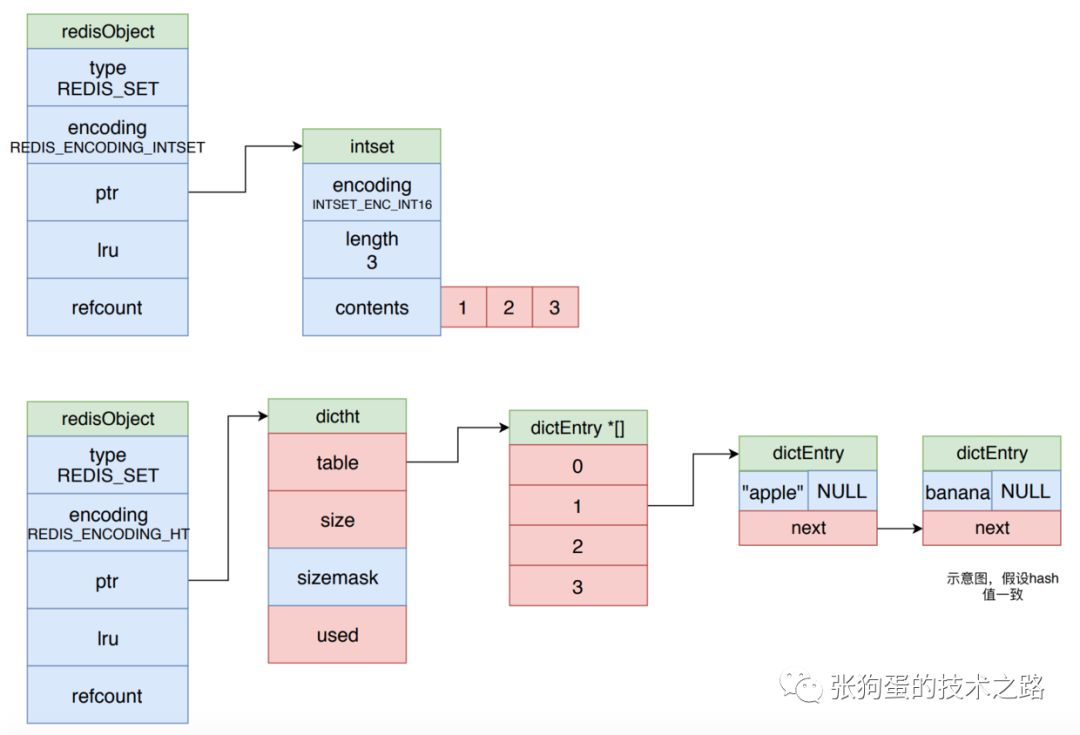
3.5.2 集合对象的编码
3.5.2.1 intset 编码
当集合对象可以同时满足以下两个条件时,对象使用 intset 编码:
-
集合对象保存的所有元素都是整数值。
-
集合对象保存的元素数量不超过512个。
3.5.2.2 dict 编码
否则使用 dict 进行编码。
| 编码—encoding | 对象—ptr |
|---|---|
| OBJ_ENCODING_HT | 字典实现的集合对象 |
| OBJ_ENCODING_INTSET | 整数集合实现的集合对象 |
3.6 哈希对象的底层实现类型
3.6.1 哈希对象的底层实现类型
哈希对象的编码可以使用 ziplist 或 dict。其示意图如下所示。
当哈希对象使用压缩队列作为底层实现时,程序将键值对紧挨着插入到压缩队列中,保存键的节点在前,保存值的节点在后。如下图的上半部分所示,该哈希有两个键值对,分别是 name:Tom 和 age:25。
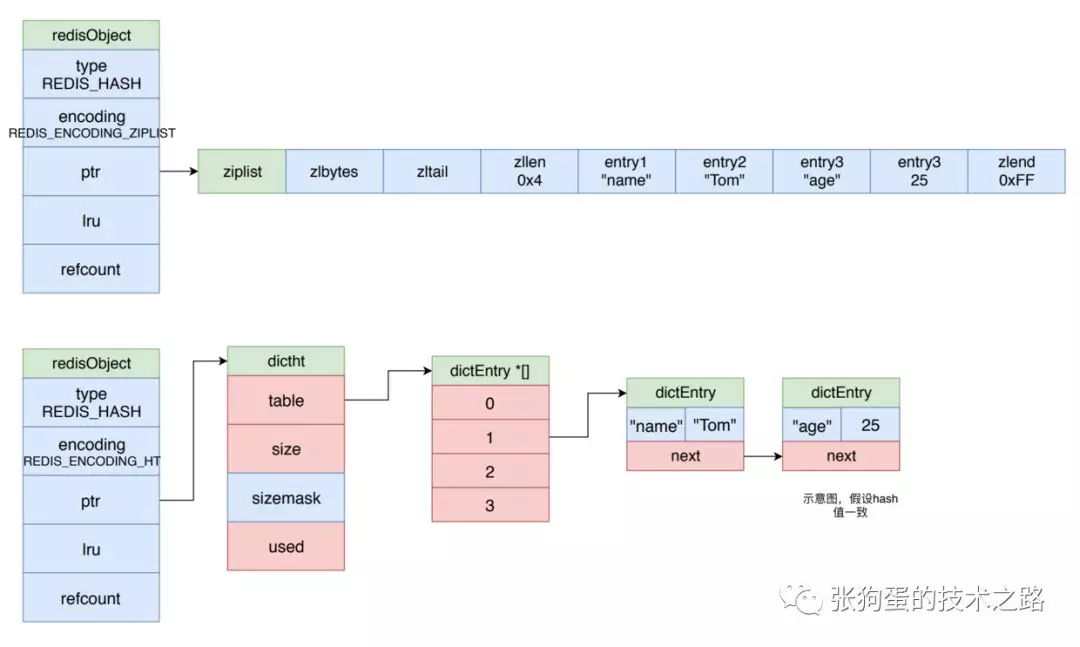
3.6.2 哈希对象的编码
3.6.2.1 ziplist 编码
当哈希对象可以同时满足以下两个条件时,哈希对象使用 ziplist 编码:
-
哈希对象保存的所有键值对的键和值的字符串长度都小于64字节。
-
哈希对象保存的键值对数量小于512个。
3.6.2.2 dict 编码
不能满足这两个条件的哈希对象需要使用 dict 编码或者转换为 dict 编码。
| 编码—encoding | 对象—ptr |
|---|---|
| OBJ_ENCODING_ZIPLIST | 压缩列表实现的哈希对象 |
| OBJ_ENCODING_HT | 字典实现的哈希对象 |
3.7 有序集合对象(ZSET)
3.7.1 有序集合对象的底层实现类型
有序集合的编码可以为 ziplist 或者 skiplist。
有序集合使用 ziplist 编码时,每个集合元素使用两个紧挨在一起的压缩列表节点表示,前一个节点是元素的值,第二个节点是元素的分值,也就是排序比较的数值。
压缩列表内的集合元素按照分值从小到大进行排序,如下图上半部分所示。
有序集合使用 skiplist 编码作为底层实现时,一个 zet 结构同时包含一个字典和一个跳跃表。
其中,跳跃表按照分值从小到大保存所有元素,每个跳跃表节点保存一个元素,其score值是元素的分值。而字典则创建一个一个从成员到分值的映射,字典的键是集合成员的值,字典的值是集合成员的分值。通过字典可以在O(1)复杂度查找给定成员的分值。如下图所示。
跳跃表和字典中的集合元素值对象都是共享的,所以不会额外消耗内存。
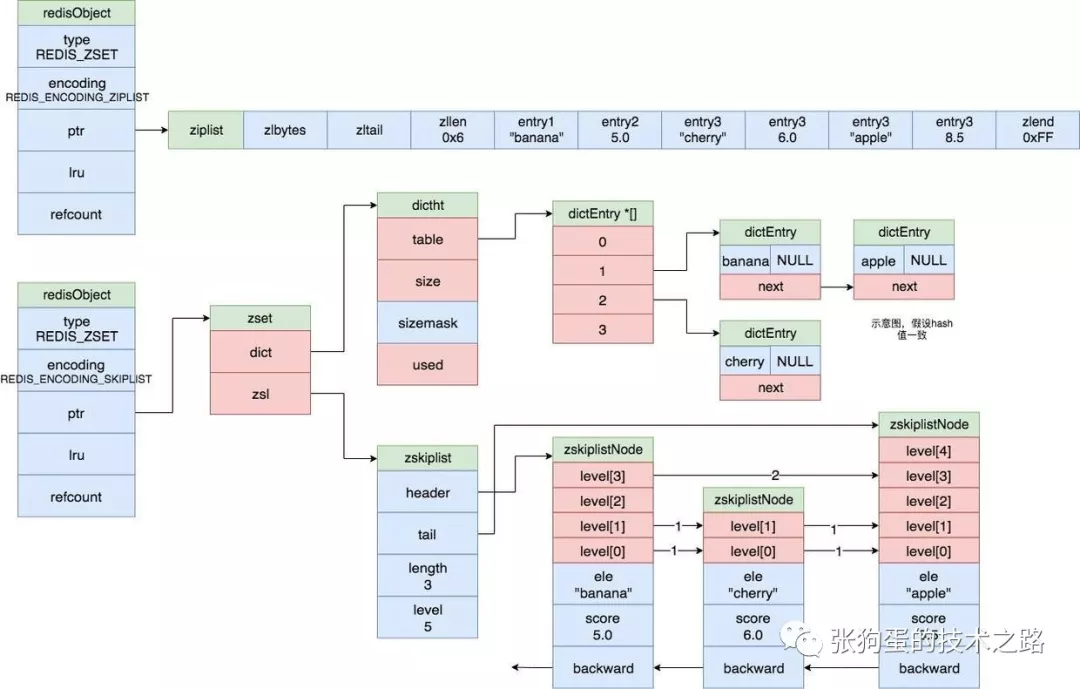
3.7.2 有序集合对象的底层实现类型
3.7.2.1 ziplist 编码
当有序集合对象可以同时满足以下两个条件时,对象使用 ziplist 编码:
-
有序集合保存的元素数量少于128个;
-
有序集合保存的所有元素的长度都小于64字节。
3.7.2.2 ziplist 编码
否则使用 skiplist 编码。
3.8 流对象的底层实现类型
https://blog.csdn.net/alpha_love/article/details/116568776?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_title-1&spm=1001.2101.3001.4242(后续需要详细分析)
OBJ_ENCODING_STREAM 流对象是 5.0 版本引入的新的数据对象,与列表对象 List 极为相似,但是功能更为强大,带有订阅发布的能力。其采用的存储结构 OBJ_ENCODING_STREAM 与其他的存储结构截然不同,OBJ_ENCODING_STREAM 底层采用压缩前缀树(radix tree) 来存储,其每个节点 raxNode 用于存储键值对相关数据,不同键相同的前缀字符将被压缩到同一个节点中,并使用 iskey 属性来标识从根节点到当前节点保存的字符是否是完整的键。
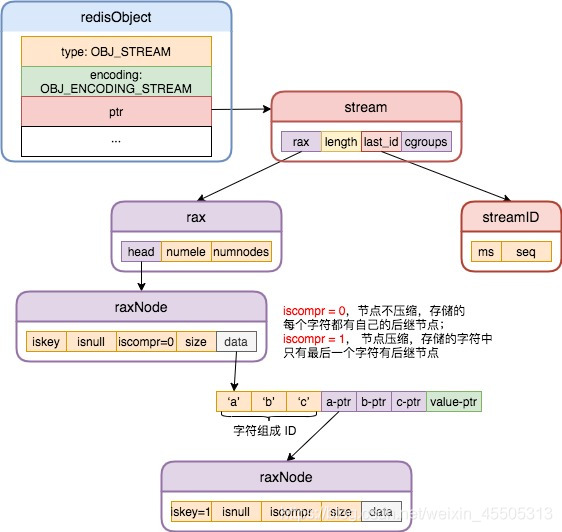
四、数据库键空间
4.1 键空间结构
Redis 服务器都有多个 Redis 数据库,每个Redis 数据都有自己独立的键值空间。每个 Redis 数据库使用 dict 保存数据库中所有的键值对。
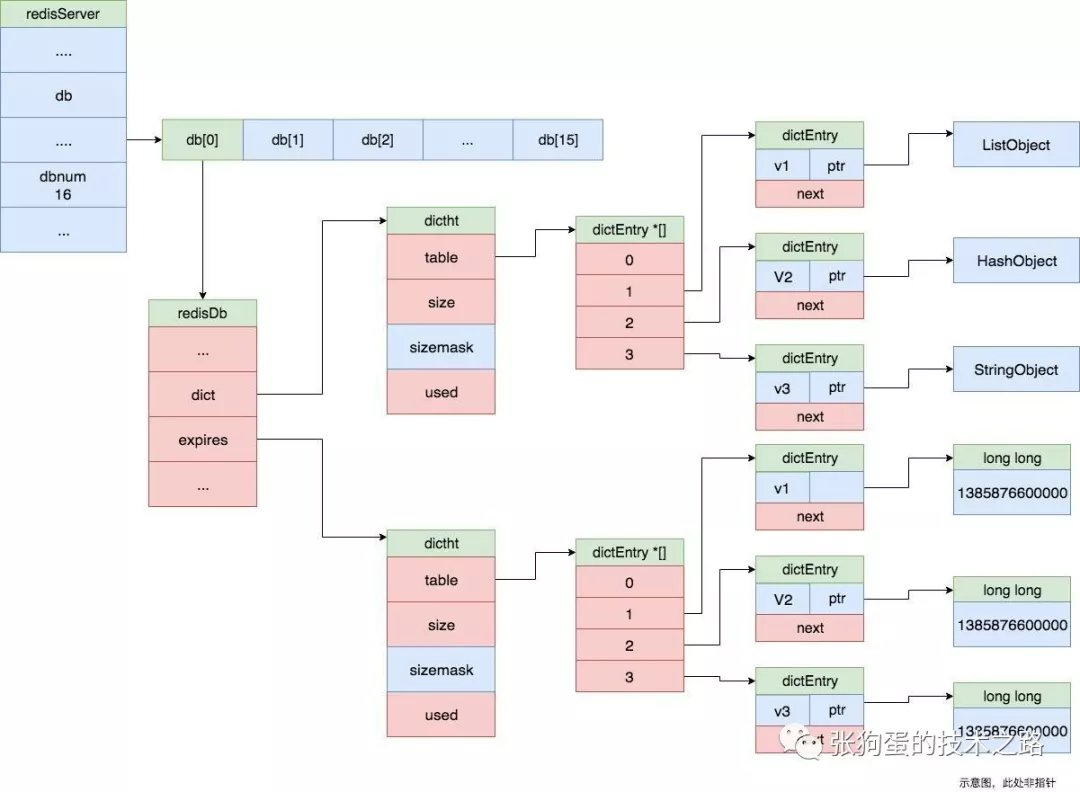
4.2 dict的应用
- 哈希对象
- 键空间的键也就是数据库的键,每个键都是一个字符串对象,而值对象可能为字符串对象、列表对象、哈希表对象、集合对象和有序集合对象中的一种对象。这张表称为键值表。
-
除了键空间,Redis 也使用 dict 结构来保存键的过期时间,其键是键空间中的键值,而值是过期时间,如上图所示。通过过期字典(过期表),Redis 可以直接判断一个键是否过期,首先查看该键是否存在于过期字典,如果存在,则比较该键的过期时间和当前服务器时间戳,如果大于,则该键过期,否则未过期。
五、对象系统的重要操作
5.1 创建一个字符串对象
5.1.1 OBJ_ENCODING_RAW编码
编码为OBJ_ENCODING_RAW
1 robj *createObject(int type, void *ptr) { //创建一个对象
2 robj *o = zmalloc(sizeof(*o)); //分配空间
3 o->type = type; //设置对象类型
4 o->encoding = OBJ_ENCODING_RAW; //设置编码方式为OBJ_ENCODING_RAW
5 o->ptr = ptr; //设置
6 o->refcount = 1; //引用计数为1
7
8 /* Set the LRU to the current lruclock (minutes resolution). */
9 o->lru = LRU_CLOCK(); //计算设置当前LRU时间
10 return o;
11 }
12
13 /* Create a string object with encoding OBJ_ENCODING_RAW, that is a plain
14 * string object where o->ptr points to a proper sds string. */
15 robj *createRawStringObject(const char *ptr, size_t len) {
16 return createObject(OBJ_STRING, sdsnewlen(ptr,len));
17 }
5.1.2 OBJ_ENCODING_EMBSTR编码
编码为OBJ_ENCODING_EMBSTR
1 /* Create a string object with encoding OBJ_ENCODING_EMBSTR, that is
2 * an object where the sds string is actually an unmodifiable string
3 * allocated in the same chunk as the object itself. */
4 //创建一个embstr编码的字符串对象
5 robj *createEmbeddedStringObject(const char *ptr, size_t len) {
6 robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr8)+len+1); //分配空间
7 struct sdshdr8 *sh = (void*)(o+1); //o+1刚好就是struct sdshdr8的地址
8
9 o->type = OBJ_STRING; //类型为字符串对象
10 o->encoding = OBJ_ENCODING_EMBSTR; //设置编码类型OBJ_ENCODING_EMBSTR
11 o->ptr = sh+1; //指向分配的sds对象,分配的len+1的空间首地址
12 o->refcount = 1; //设置引用计数
13 o->lru = LRU_CLOCK(); //计算设置当前LRU时间
14
15 sh->len = len; //设置字符串长度
16 sh->alloc = len; //设置最大容量
17 sh->flags = SDS_TYPE_8; //设置sds的类型
18 if (ptr) { //如果传了字符串参数
19 memcpy(sh->buf,ptr,len); //将传进来的ptr保存到对象中
20 sh->buf[len] = '�'; //结束符标志
21 } else {
22 memset(sh->buf,0,len+1); //否则将对象的空间初始化为0
23 }
24 return o;
25 }
5.1.3 两种编码方式的区别
两种字符串对象编码方式的区别:
sdshdr8的大小为3个字节,加上1个结束符共4个字节;redisObject的大小为16个字节;redis使用jemalloc内存分配器,且jemalloc会分配8,16,32,64等字节的内存;一个embstr固定的大小为16+3+1 = 20个字节,因此一个最大的embstr字符串为64-20 = 44字节;如果初始长度为0的情况下,并且类型为SDS_TYPE_5,则会被强制转为SDS_TYPE_8。
1 /* Create a string object with EMBSTR encoding if it is smaller than
2 * REIDS_ENCODING_EMBSTR_SIZE_LIMIT, otherwise the RAW encoding is
3 * used.
4 *
5 * The current limit of 39 is chosen so that the biggest string object
6 * we allocate as EMBSTR will still fit into the 64 byte arena of jemalloc. */
7
8 //sdshdr8的大小为3个字节,加上1个结束符共4个字节
9 //redisObject的大小为16个字节
10 //redis使用jemalloc内存分配器,且jemalloc会分配8,16,32,64等字节的内存
11 //一个embstr固定的大小为16+3+1 = 20个字节,因此一个最大的embstr字符串为64-20 = 44字节
12 #define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44
13
14 // 创建字符串对象,根据长度使用不同的编码类型
15 // createRawStringObject和createEmbeddedStringObject的区别是:
16 // createRawStringObject是当字符串长度大于44字节时,robj结构和sdshdr结构在内存上是分开的
17 // createEmbeddedStringObject是当字符串长度小于等于44字节时,robj结构和sdshdr结构在内存上是连续的
18 robj *createStringObject(const char *ptr, size_t len) {
19 if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT)
20 return createEmbeddedStringObject(ptr,len);
21 else
22 return createRawStringObject(ptr,len);
23 }
5.2 字符串对象编码的优化
编码选择规则
1、是整数类型,且在0和OBJ_SHARED_INTEGERS(10000)之间,使用整数对象池进行编码
2、是整数类型,且在LONG_MIN和LONG_MAX之间,使用OBJ_ENCONDING_INT(整数)进行编码
3、其它的所有情况都以字符串进行编码,但是如果编码后的长度小于等于44字节,就使用OBJ_ENCONDING_EMBSTR。否则就使用OBJ_ENCONDING_RAW进行编码。
1 /* Try to encode a string object in order to save space */
2 //尝试优化字符串对象的编码方式以节约空间
3 robj *tryObjectEncoding(robj *o) {
4 long value;
5 sds s = o->ptr;
6 size_t len;
7
8 /* Make sure this is a string object, the only type we encode
9 * in this function. Other types use encoded memory efficient
10 * representations but are handled by the commands implementing
11 * the type. */
12 serverAssertWithInfo(NULL,o,o->type == OBJ_STRING);
13
14 /* We try some specialized encoding only for objects that are
15 * RAW or EMBSTR encoded, in other words objects that are still
16 * in represented by an actually array of chars. */
17 //如果字符串对象的编码类型为RAW或EMBSTR时,才对其重新编码
18 if (!sdsEncodedObject(o)) return o;
19
20 /* It's not safe to encode shared objects: shared objects can be shared
21 * everywhere in the "object space" of Redis and may end in places where
22 * they are not handled. We handle them only as values in the keyspace. */
23 //如果refcount大于1,则说明对象的ptr指向的值是共享的,不对共享对象进行编码
24 if (o->refcount > 1) return o;
25
26 /* Check if we can represent this string as a long integer.
27 * Note that we are sure that a string larger than 20 chars is not
28 * representable as a 32 nor 64 bit integer. */
29 len = sdslen(s); //获得字符串s的长度
30
31 //如果len小于等于20,表示符合long long可以表示的范围,且可以转换为long类型的字符串进行编码
32 if (len <= 20 && string2l(s,len,&value)) {
33 /* This object is encodable as a long. Try to use a shared object.
34 * Note that we avoid using shared integers when maxmemory is used
35 * because every object needs to have a private LRU field for the LRU
36 * algorithm to work well. */
37 if ((server.maxmemory == 0 ||
38 (server.maxmemory_policy != MAXMEMORY_VOLATILE_LRU &&
39 server.maxmemory_policy != MAXMEMORY_ALLKEYS_LRU)) &&
40 value >= 0 &&
41 value < OBJ_SHARED_INTEGERS) //如果value处于共享整数的范围内
42 {
43 decrRefCount(o); //原对象的引用计数减1,释放对象
44 incrRefCount(shared.integers[value]); //增加共享对象的引用计数
45 return shared.integers[value]; //返回一个编码为整数的字符串对象
46 } else { //如果不处于共享整数的范围
47 if (o->encoding == OBJ_ENCODING_RAW) sdsfree(o->ptr); //释放编码为OBJ_ENCODING_RAW的对象
48 o->encoding = OBJ_ENCODING_INT; //转换为OBJ_ENCODING_INT编码
49 o->ptr = (void*) value; //指针ptr指向value对象
50 return o;
51 }
52 }
53
54 /* If the string is small and is still RAW encoded,
55 * try the EMBSTR encoding which is more efficient.
56 * In this representation the object and the SDS string are allocated
57 * in the same chunk of memory to save space and cache misses. */
58 //如果len小于44,44是最大的编码为EMBSTR类型的字符串对象长度
59 if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT) {
60 robj *emb;
61
62 if (o->encoding == OBJ_ENCODING_EMBSTR) return o; //将RAW对象转换为OBJ_ENCODING_EMBSTR编码类型
63 emb = createEmbeddedStringObject(s,sdslen(s)); //创建一个编码类型为OBJ_ENCODING_EMBSTR的字符串对象
64 decrRefCount(o); //释放之前的对象
65 return emb;
66 }
67
68 /* We can't encode the object...
69 *
70 * Do the last try, and at least optimize the SDS string inside
71 * the string object to require little space, in case there
72 * is more than 10% of free space at the end of the SDS string.
73 *
74 * We do that only for relatively large strings as this branch
75 * is only entered if the length of the string is greater than
76 * OBJ_ENCODING_EMBSTR_SIZE_LIMIT. */
77 //无法进行编码,但是如果s的未使用的空间大于使用空间的10分之1
78 if (o->encoding == OBJ_ENCODING_RAW &&
79 sdsavail(s) > len/10)
80 {
81 o->ptr = sdsRemoveFreeSpace(o->ptr); //释放所有的未使用空间
82 }
83
84 /* Return the original object. */
85 return o;
86 }
5.3 共享对象和引用计数管理对象
5.3.1 共享对象
一些对象在Redis中非常常见,如命令返回值:OK ERROR WRONGTYPE等字符,以及一些小范围的整数(0-10000)。对于这些常见对象,Redis在内部使用了Flyweight模式: 预分配一些常见值的对象,程序避免重复分配麻烦,也节约了一些CPU时间。
Redis预分配的值对象有
-
- 各种命令的返回值:OK ERROR WRONGTYPE 等。
- 包括0在内的,小于redis.h/REDIS_SHARED_INTEGERS(10000)的所有整数值。
因为命令的反回值都是直接返回给客户端,其值不需要共享; 而对于较小的整数值,如果某命令的输入值是一个小于REDIS_SHARED_INTEGERS的整数对象,那么当这个对象被保存进数据库时,Redis就会释放原来的值,并将值的指针指向共享对象。
需要注意的是:共享对象只能被带指针的数据结构使用。 如字典,双端链表都带有指针,而像整数集合和压缩列表这些只能保存字符串、整数等字面值的内存数据结构就不能使用共享对象。
5.3.2 为什么只有整数对象池?
因为整数比较算法时间复杂度为O(1),保留一万个整数为了防止对象池浪费。字符串判断相等的时间复杂度为O(n)。hash、list等数据结构,判断相等性时间复杂度为O(n^2)。所以Redis只有整数对象池。
5.3.3 引用计数管理
当将redisObject用作数据库的键或值而不是作为存储参数时,其生命周期是非常长的,而C语言本身没有释放内存的机制,如果只依靠程序员的记忆来对对象进行追踪和销毁基本是不可能的。 另外,对于共享对象,可能被多次引用,因此关于被引用了多少次也是需要考虑的问题。
Redis对象系统使用了引用计数来负责维持和销毁对象:每个对象结构都有一个ref引用计数,当计数递减为0时,这个redisObject结构以及它所引用的底层数据结构的内存都会被释放,如果底层使用的是整数对象池,则只是将redisObject结构的内存释放,并将所指向的对象的引用计数减1,即使引用计数为0,也不会释放整数对象池中的任何共享对象。
1 //引用计数加1
2 void incrRefCount(robj *o) {
3 if (o->refcount != OBJ_SHARED_REFCOUNT) o->refcount++;
4 }
5
6 //引用计数减1
7 void decrRefCount(robj *o) {
8 //当引用对象等于1时,在操作引用计数减1,直接释放对象的ptr和对象空间
9 if (o->refcount == 1) {
10 switch(o->type) {
11 case OBJ_STRING: freeStringObject(o); break;
12 case OBJ_LIST: freeListObject(o); break;
13 case OBJ_SET: freeSetObject(o); break;
14 case OBJ_ZSET: freeZsetObject(o); break;
15 case OBJ_HASH: freeHashObject(o); break;
16 case OBJ_MODULE: freeModuleObject(o); break;
17 case OBJ_STREAM: freeStreamObject(o); break;
18 default: serverPanic("Unknown object type"); break;
19 }
20 zfree(o);
21 } else {
22 if (o->refcount <= 0) serverPanic("decrRefCount against refcount <= 0");
23 if (o->refcount != OBJ_SHARED_REFCOUNT) o->refcount--;//否则减1
24 }
25 }
5.4 对象的复制
如果对象是共享的则只是将共享对的引用计数增加1,然后将新元素的指针指向共享对象,如果是非共享对象,则需要进行深拷贝。
1 /**
2 * Duplicate a string object, with the guarantee that the returned object
3 * has the same encoding as the original one.
4 *
5 * This function also guarantees that duplicating a small integer object
6 * (or a string object that contains a representation of a small integer)
7 * will always result in a fresh object that is unshared (refcount == 1).
8 *
9 * The resulting object always has refcount set to 1.
10 * 返回 复制的o对象的副本的地址,且创建的对象非共享
11 */
12 robj *dupStringObject(const robj *o) {
13 robj *d;
14
15 //一定是OBJ_STRING类型
16 serverAssert(o->type == OBJ_STRING);
17
18 switch(o->encoding) {//根据不同的编码类型
19 case OBJ_ENCODING_RAW:
20 return createRawStringObject(o->ptr,sdslen(o->ptr));//创建的对象非共享
21 case OBJ_ENCODING_EMBSTR:
22 return createEmbeddedStringObject(o->ptr,sdslen(o->ptr));//创建的对象非共享
23 case OBJ_ENCODING_INT://整数编码类型
24 d = createObject(OBJ_STRING, NULL);//即使是共享整数范围内的整数,创建的对象也是非共享的
25 d->encoding = OBJ_ENCODING_INT;
26 d->ptr = o->ptr;
27 return d;
28 default:
29 serverPanic("Wrong encoding.");
30 break;
31 }
32 }
5.5 对象的解码操作
如果是OBJ_ENCONDING_EMBSTR或者OBJ_ENCONDING_RAW,直接返回一个共享对象,如果是对象本身类型是OBJ_STRINT并且其编码类型是OBJ_ENCONDING_INT类型,也就是整数对象,得到结果后,需要先将整数转化为字符串对象,然后将字符串对象返回。
1 /**
2 * Get a decoded version of an encoded object (returned as a new object).
3 * If the object is already raw-encoded just increment the ref count.
4 * 将对象是整型的解码为字符串并返回,如果是字符串编码则直接返回输入对象,只需增加引用计数
5 */
6 robj *getDecodedObject(robj *o) {
7 robj *dec;
8
9 //如果是OBJ_ENCODING_RAW或OBJ_ENCODING_EMBSTR类型的对象
10 if (sdsEncodedObject(o)) {
11 //增加引用计数,返回一个共享的对象
12 incrRefCount(o);
13 return o;
14 }
15 //如果是整数对象
16 if (o->type == OBJ_STRING && o->encoding == OBJ_ENCODING_INT) {
17 char buf[32];
18
19 //将整数转换为字符串
20 ll2string(buf,32,(long)o->ptr);
21 //创建一个字符串对象
22 dec = createStringObject(buf,strlen(buf));
23 return dec;
24 } else {
25 serverPanic("Unknown encoding type");
26 }
27 }
六、参考文章
https://blog.csdn.net/men_wen/article/details/70257207
https://mp.weixin.qq.com/s/gQnuynv6XPD_aeIBQBeI2Q
https://blog.csdn.net/alpha_love/article/details/116568776?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_title-1&spm=1001.2101.3001.4242
https://blog.csdn.net/yuyixinye/article/details/40341003