一、知识点归纳以及自己最有收获的内容
1、知识点归纳
总结一下一门程序设计语言有哪些必备的要素和技能?这些要素和技能在shell脚本中是如果呈现出来的?
程序设计语言有3个方面的因素,即语法、语义和语用。语法表示程序的结构或形式,亦即表示构成语言的各个记号之间的组合规律,但不涉及这些记号的特定含义,也不涉及使用者;语义表示程序的含义,亦即表示按照各种方法所表示的各个记号的特定含义,但不涉及使用者。语言基本成分不外4种。数据成分——用以描述程序中所涉及的数据;运算成分——用以描述程序中所包含的运算;控制成分——用以表达程序中的控制构造、传输成分。这些要素具体体现在sh编程中的各类命令当中。
第10章 sh编程
1、sh 脚本是一个包含sh 语句的文本文件,命令解释程序sh要执行该语句。sh是一个解释程序,逐行读取sh脚本文件并执行。
2、命令行参数
在sh脚本中,可以通过位置参数$0、$1、$2等访问命令行参数。其中特殊字符$表示替换,如果需要使用$字符,需加上单引号或者反引号\。
(1)位置参数
$n(if n > 9, add {})
$0是程序名本身,其余是程序的参数。
(2)内置变量
$*=所有命令行参数,包括$0
$S=执行sh的进程PID
$?=最后一个命令执行的退出状态(成功为0,否则为非0)
3、特殊符号
~:家目录
!:执行历史命令
$:变量中取内容符
&:后台执行
;:一行执行多个命令,以此为间隔
|:管道符``:反引号,命令中执行命令
4、sh命令
(1)内置命令
.file:读取并执行文件。
break [n]:从最近的第n个嵌套循环中退出。
cd [dirname]: 更换目录。
continue[n]:重启最近的第n个嵌套循环。
eval [arg...]:计算一次参数并让sh执行生成的命令。
exec [arg...]:通过这个sh执行命令,sh将会退出。
exit [n]:使sh退出,退出状态为n。
export [var…]:将变量导出到随后执行的命令.
read [var...]:从stdin 中读取一行并为变量赋值。
set [arg...]:在执行环境中设置变量。
shift:将位置参数$2 $3...重命名为 $1 $2...。
trap [arg] [n]:接收到信号n后执行参数。
umask [ddd]:将掩码设置为八进制数 ddd 的。
wait pid]: 等待进程 pid,如果没有给出pid,则等待所有活动子进程。
(2)Linux命令
echo命令:将参数字符串作为行回显到stdout。expr命令:间接更改sh变量的值。
管道命令:作为过滤器。
实用命令:
axk:数据处理程序。
cmp:比较两个文件。comm:选择两个排序文件共有的行。
grep:匹配一系列文件的模式。
diff:找出两个文件的差异。join:通过使用相同的键来连接记录以比较两个文件。
sed:流或行编辑命令。sort:排序或合并文件。tail:打印某个文件的最后口行。tr:一对一宇符翻译。uniq:从文件中删除连续重复行。
5、sh控制语句
sh支持多种控制语句,可类比C语言的语句。
(1)if-else-if语句
if condition1
then
command1
elif condition2
then
command2
else
commandN
fi
(2)for语句
for var in item1 item2 ... itemN
do
command1
command2
...
commandN
done
命令行格式:
for var in item1 item2 ... itemN; do command1; command2… done;
(3)while语句
while condition
do
command
Done
(4)untill-do语句
until 循环执行一系列命令直至条件为 true 时停止。
until condition
do
command
done
(5)case语句
case 值 in
模式1)
command1
command2
...
commandN
;;
模式2)
command1
command2
...
commandN
;;
esac
(6)continue和break语句
- break命令允许跳出所有循环(终止执行后面的所有循环)。
- continue命令不会跳出所有循环,仅仅跳出当前循环。
6、运算
eq:等于(equal)
gt:大于(greater)
lt:小于(less)
ge:大于或等于(greater or equal)
le:小于或等于(less or equal)
ne:不等于(not equal)
文件运算
d:检查文件是否存在且为目录
e:检查文件是否存在
f:检查文件是否存在且为文件
r:文件是否可读
s:不为空
w:是否可写
x:可执行
O:是否被当前用户拥有
G:默认用户组为当前用户组
字符串比较运算
==:等于
!=:不等于
-n:字符串长度是否大于0
z:字符串长度是否为0
逻辑运算
&&
||
!
赋值运算
=
7、I/O重定向
>file:stdout转向文件,如果文件不存在,将会创建文件。
>>file:stdout追加到文件。
<file:将文件用作stdin;文件必须存在并具有r权限。
<<word:从“here”文件中获取输入,直到只包含“word”的行。
8、sh函数
(1)sh函数的定义
func()
{
# function code
}
(2)通配符
- 星号(*)通配符:可扩展到当前目录中的所有文件。
- ?通配符:查询某文件名中的字符。
- []通配符:查询文件名中一对[]中的字符。
(3)调试脚本
sh脚本由带有-x选项的子sh运行以进行调试。
子sh将在执行命令之前显示要执行的每个sh命令,包括变量和命令替换。它允许用户跟踪命令执行。如果出现错误,sh将在错误行上停止并显示错误消息。
自己最有收获的内容
通过sh编程语言的学习,加上与之前学习的python、C语言、JAVA进行比较,我进一步掌握了语言间的通性,比如输入输出方面或许不同的语言有不同的语句,sh有read与echo,C语言有scanf与printf等,但它们一定会有输入与输出。这些共性的地方才是我们掌握一门语言最好入手的地方。
二、问题与解决思路
(1)在预习时对管道这一概念比较模糊,不知道在sh中起什么作用。
解决方法:
网上查询了相关资料:管道的作用是提供一个通道,将上一个程序的标准输出重定向到下一个程序作为下一个程序的标准输入。
通常使用管道的好处是一方面形式上简单,另一方面其执行效率要远高于使用临时文件。
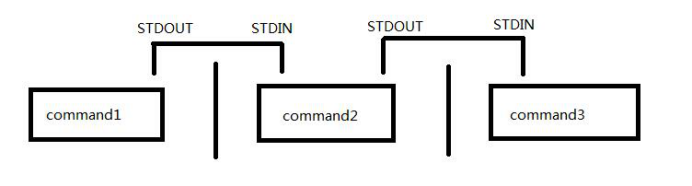
一些命令对管道的应用
1.选取命令:cut,grep
- cut 选取命令,以行为单位处理信息。
1.#cut [-bn] [file] 或 cut [-c] [file] 或 cut [-df] [file]
2.
3.#参数
4.-b 以字节为单位进行分割。这些字节忽略多字节字符边界,除非指定-n参数
5.-c 以字符为单位进行分割
6.-d 自定义分隔符,默认为制表符
7.-f 依据-d参数的分割字符将一段信息分割为数段,用-f取出第几段的意思
8.-n 取消分割多字节字符,仅和-b标志一起使用。如果字符的最后一个字节落在由-b标志的List参数指示的</br>范围之内,该字符将被写出,否则该字符被排除
- grep 前面的cut是取出一行中的某些字符,而grep是来筛选某一行存在你需要的信息,则把该行拿出来
2.排序命令:sort, wc,uniq
- Sort进行排序,根据不同的关键词。因为可能是字符排序,所以这里需要确定你的系统的编码,最好是LANG=C
# sort [-fbMnrtuk] [file or stdin]
参数:
-f 忽略大小写
-b 忽略最前面的空格符部分
-M 以月份名字进行排序(默认是以文本类型进行排序)
-n 使用纯数字进行排序
-r 反向排序
-u 就是uniq,相同的数据只出现一行
-t 分隔符,默认以 [tab] 键为分割
-k 以那个区间来进行排序的意思
- uniq 相当于sort的 -u 选项 取出一些重复的数据。
# uniq [-ic]
-i 忽略大小写
-c 对重复信息计数
- wc 计数工具
wc [-lwm]
参数:
-l 仅列出多少行
-w 仅列出多少字(英文单词)
-m 多少字符
三、实践内容与截图
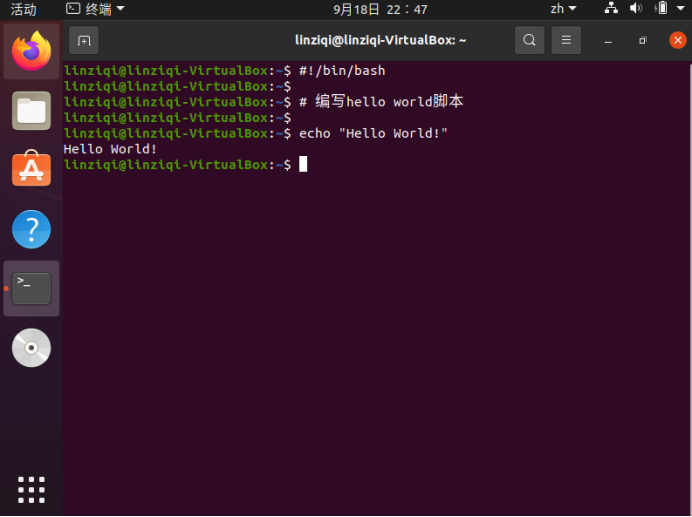
- 实践1:hello world
代码:
#!/bin/bash
# 编写hello world脚本
echo "Hello World!"
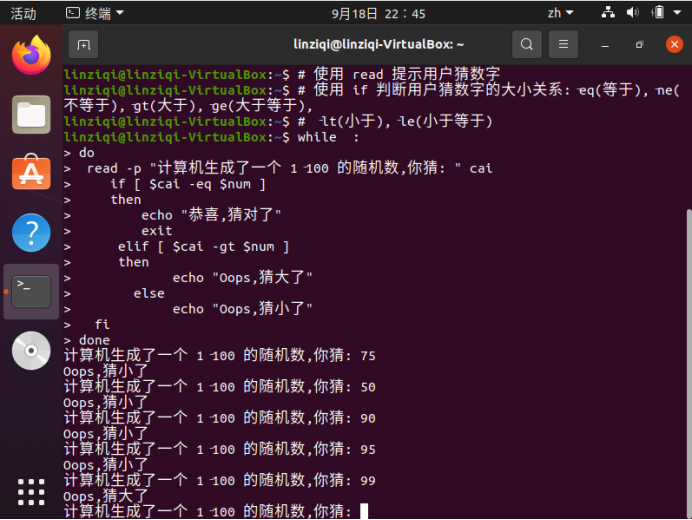
- 实践2:猜数字
#!/bin/bash
# 脚本生成一个 100 以内的随机数,提示用户猜数字,根据用户的输入,提示用户猜对了,
# 猜小了或猜大了,直至用户猜对脚本结束。
# RANDOM 为系统自带的系统变量,值为 0‐32767的随机数
# 使用取余算法将随机数变为 1‐100 的随机数
num=$[RANDOM%100+1]
echo "$num"
# 使用 read 提示用户猜数字
# 使用 if 判断用户猜数字的大小关系:‐eq(等于),‐ne(不等于),‐gt(大于),‐ge(大于等于),
# ‐lt(小于),‐le(小于等于)
while :
do
read -p "计算机生成了一个 1‐100 的随机数,你猜: " cai
if [ $cai -eq $num ]
then
echo "恭喜,猜对了"
exit
elif [ $cai -gt $num ]
then
echo "Oops,猜大了"
else
echo "Oops,猜小了"
fi
done