聚合
使用 functions 函数进行聚合
import org.apache.spark.sql.functions._
val groupedDF: RelationalGroupedDataset = pmDF.groupBy('year)
groupedDF.agg(avg('pm) as "pm_avg")
.orderBy('pm_avg)
.show()
使用 RelationalGroupedDataset 的 API 进行聚合
groupedDF.avg("pm")
.orderBy('pm_avg)
.show()
groupedDF.max("pm")
.orderBy('pm_avg)
.show()
多维聚合
rollup(A,B)
rollup 就相当于先按照 A, B 进行聚合, 后按照 A进行聚合, 最后对整个数据集进行聚合, 在按照 A 聚合时, B 列值为 null, 聚合整个数据集的时候, 除了聚合列, 其它列值都为 null。结果集中有三种数据形式: A B C, A null C, null null C
cube(A,B)
结果集中有四种数据形式: A B C, A null C, null null C, null B C
连接
| 连接类型 | 类型字段 | 解释 |
|---|
|
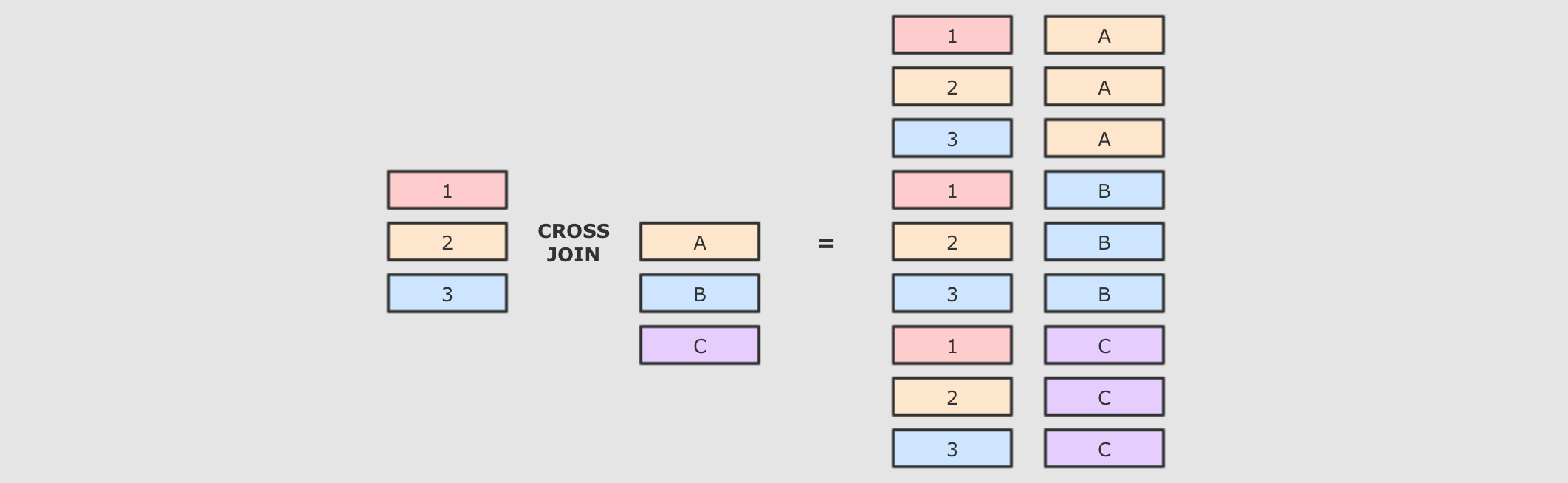
交叉连接
|
cross
|
- 解释
-
交叉连接就是笛卡尔积, 就是两个表中所有的数据两两结对
交叉连接是一个非常重的操作, 在生产中, 尽量不要将两个大数据集交叉连接, 如果一定要交叉连接, 也需要在交叉连接后进行过滤, 优化器会进行优化
SQL 语句-
select * from person cross join cities
Dataset 操作-
person.crossJoin(cities)
.where(person.col("cityId") === cities.col("id"))
.show()
|
|---|
|
内连接
|
inner
|
- 解释
-
内连接就是按照条件找到两个数据集关联的数据, 并且在生成的结果集中只存在能关联到的数据
SQL 语句-
select * from person inner join cities on person.cityId = cities.id
Dataset 操作-
person.join(right = cities,
joinExprs = person("cityId") === cities("id"),
joinType = "inner")
.show()
|
|---|
|
全外连接
|
outer, full, fullouter
|
- 解释
-
内连接和外连接的最大区别, 就是内连接的结果集中只有可以连接上的数据, 而外连接可以包含没有连接上的数据, 根据情况的不同, 外连接又可以分为很多种, 比如所有的没连接上的数据都放入结果集, 就叫做全外连接
SQL 语句-
select * from person full outer join cities on person.cityId = cities.id
Dataset 操作-
person.join(right = cities,
joinExprs = person("cityId") === cities("id"),
joinType = "full") // "outer", "full", "full_outer"
.show()
|
|---|
|
左外连接
|
leftouter, left
|
- 解释
-
左外连接是全外连接的一个子集, 全外连接中包含左右两边数据集没有连接上的数据, 而左外连接只包含左边数据集中没有连接上的数据
SQL 语句-
select * from person left join cities on person.cityId = cities.id
Dataset 操作-
person.join(right = cities,
joinExprs = person("cityId") === cities("id"),
joinType = "left") // leftouter, left
.show()
|
|---|
|
LeftAnti
|
leftanti
|
- 解释
-
LeftAnti 是一种特殊的连接形式, 和左外连接类似, 但是其结果集中没有右侧的数据, 只包含左边集合中没连接上的数据
SQL 语句-
select * from person left anti join cities on person.cityId = cities.id
Dataset 操作-
person.join(right = cities,
joinExprs = person("cityId") === cities("id"),
joinType = "left_anti")
.show()
|
|---|
|
LeftSemi
|
leftsemi
|
- 解释
-
和 LeftAnti 恰好相反, LeftSemi 的结果集也没有右侧集合的数据, 但是只包含左侧集合中连接上的数据
SQL 语句-
select * from person left semi join cities on person.cityId = cities.id
Dataset 操作-
person.join(right = cities,
joinExprs = person("cityId") === cities("id"),
joinType = "left_semi")
.show()
|
|---|
|
右外连接
|
rightouter, right
|
- 解释
-
右外连接和左外连接刚好相反, 左外是包含左侧未连接的数据, 和两个数据集中连接上的数据, 而右外是包含右侧未连接的数据, 和两个数据集中连接上的数据
SQL 语句-
select * from person right join cities on person.cityId = cities.id
Dataset 操作-
person.join(right = cities,
joinExprs = person("cityId") === cities("id"),
joinType = "right") // rightouter, right
.show()
|
|---|