又双叒叕转发自我的个人博客
第三次作业写的仓促,很多地方写的没太走心,不出所料被hack了。
虽然有点遗憾,但可以说很直观地学到了一点:尼玛Java的assert为什么要手动开-ea啊我不做人了舅舅。
虽然有点遗憾,但可以说很直观地学到了一点:时刻敬畏墨菲定律。
当然这次作业总体而言还是学到了很多东西。趁着这次博客作业简单回顾一下这三周的心路历程吧。
第一次作业写的时候被骗了,所以其实没有太考虑架构,求导和优化耦合在了一起。第二次开始架构就稳定了,宏观上分为读入 - 符号运算 - 优化输出三部分
读入
其实对于前三次作业,读入的基本处理套路都是类似的:
- 读因子,很开心
- 乘号连接的一连串因子就是一项了。显然单独的一个因子也可以作为一项。注意有个特例是对+1/-1的省略
- 加号/减号连接的若干项就是一个合法表达式。显然一个单独的项也可以是一个合法表达式。
我们可以以这种视角看待读入:
- 匹配一个合法的项,就是匹配
*连接的若干尽可能长的合法因子 - 匹配一个合法的表达式,就是匹配
+/-连接的若干尽可能长的合法项
好的,这很爽,因为层次到这里其实已经很清晰了。无论因子、项还是表达式的提取,都是反复迭代一个类似这样的过程:从当前剩余子串的首部,根据若干可选规则,提取尽可能长的子串。提取因子、项和表达式的区别,只在于可选的匹配规则不同。
其中比较特殊的是,在第三次作业中,尝试匹配一个表达式因子或者一个三角函数嵌套因子时需要尝试匹配一个最长表达式,而匹配最长表达式本身需要匹配若干最长项,匹配最长项有需要匹配最长因子,匹配最长因子时又会继续尝试匹配表达式因子和三角函数因子——这就是一个自然的递归过程了。
当然,这个思路过程进一步规范一下就是标准的递归下降了。
符号运算与求导
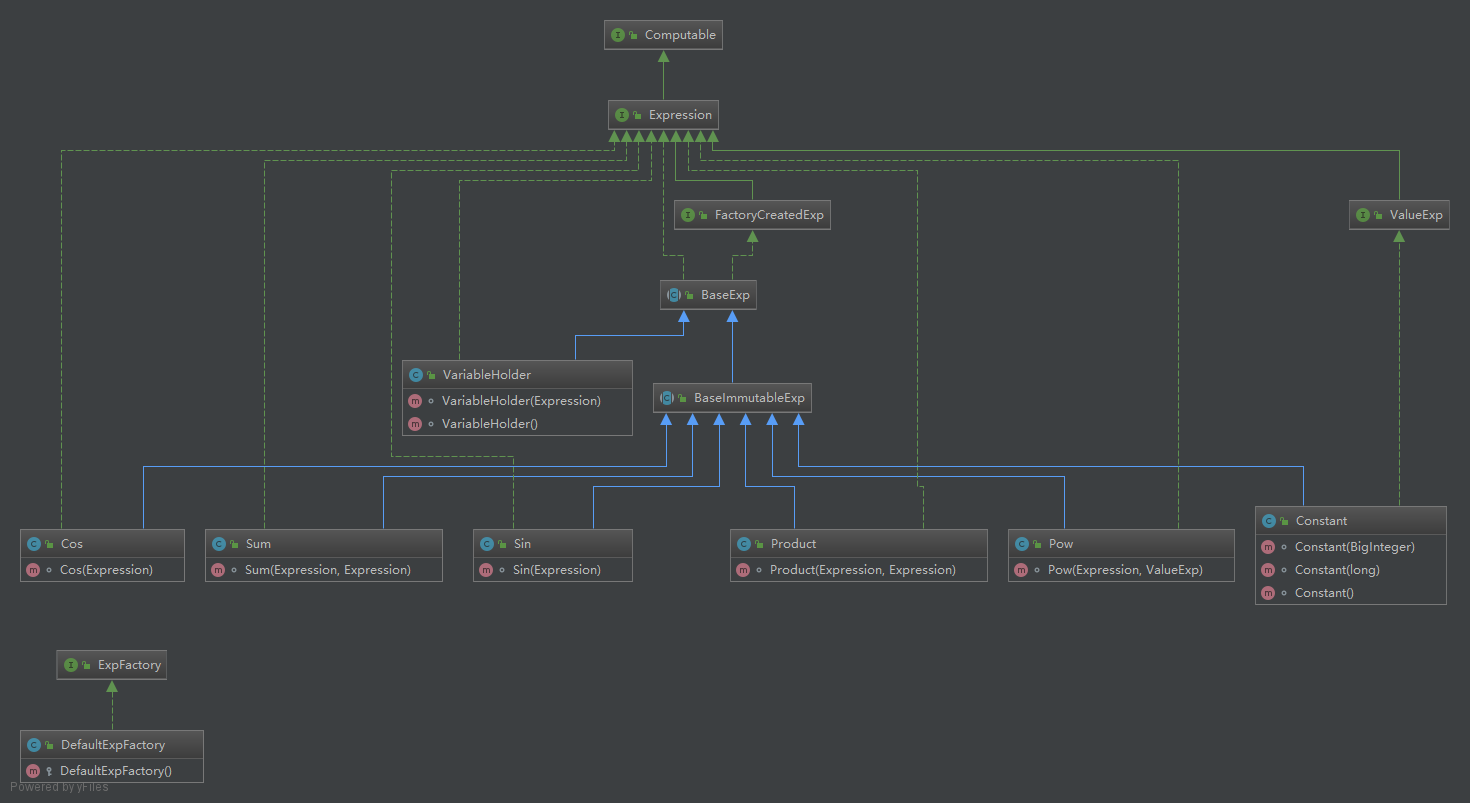
表达式树大家讨论的很广泛了,这里就不再进一步展开了。这里只想介绍一些个人的trick。
为结点类添加isOne和isZero方法
0和1在运算时可以用来完成大量简化工作。
考虑如下运算:
mul(a, b); // a*b
...
Expression mul (Expression a, Expression b){
return new Product(a, b); // Product is-a Expression
}
其中a b和它们的运算结果都是表达式结点。如果我们事先已经得知a是0,那么最理想的情况是,mul运算的结果是一个常数对象0,而不是一个乘积对象。因为无论是求导运算还是化简输出,用一个常数对象替代一个有着固定值的表达式对象永远是有收益的,因为常数的求导运算更简单(直接返回常数0),且常数是叶节点,这样做能降低子树深度(变相剪枝)。
所以我们如果引入isZero接口,为每个结点都定义它“一定为0”的规则,那么我们可以简化很多运算过程。类似的还有isOne。
mul(a, b); // a*b
...
Expression mul (Expression a, Expression b){
if(a.isZero()){
return constant(0);
} else if(b.isZero()){
return constant(0);
} else if(a.isOne()){
return b;
} else if(b.isOne()){
return a;
}
return new Product(a, b); // Product is-a Expression
}
对于一个乘积,它什么时候为0呢?
// Product.java
...
private Expression exp1;
private Expression exp2; // this = exp1 * exp2
...
@Override
public boolean isZero(){
return exp1.isZero() || exp2.isZero();
}
类似这样,如果一个乘积结点的两个乘数中至少一个是0,那么它也一定是0。类似这样我们就可以定义每一种结点的isZero和isOne规则,帮助简化运算。当然像Cos算子这种恒不为0的,我们直接返回false就好。
使用运算工厂解耦
实际上这里的“工厂”也并不是严格意义上的工厂。核心思想就是,将所有具体的运算规则定义用一个类统一管理起来,这样结点类之间就可以解耦。这样就可以很安全地借助isOne和isZero接口将一些运算与优化规则定义好。
举一个具体例子就是,对于上文中提到的mul方法,它可能返回Product或者Constant中的一种,如果我在每个结点中分别定义各自的乘法方法,一方面会导致大量的冗余,另一方面所有类都会耦合Product和Constant。
这样,所有表达式对象实际上都是由一个工厂(通过某种运算)创建的。如果有一天我需要修改运算法则或者扩展运算,我的主要修改工作是继承一个新工厂,而原有结点类可以被高度复用。
当然,实际用起来也没有想象的辣么美好,主要是我非要给每个结点指定一个自己的工厂,来实现自身的各种运算接口,这就反而导致工厂和产品之间有了耦合,在扩展工厂的时候可能需要为老工厂的每个产品重新指定工厂,就很不优雅。
compute接口
纯粹是我为了写优化器开的脑洞。如果我传给一个表达式类一个Computable类的对象,我希望它能够根据这个对象定义的各种运算规则计算出一个新的Computable对象。因此我就可以在得到一个表达式树以后,用它真的“计算”一个什么东西出来。如果这个Computable对象本身就是一种类似“容器”的东西,那它就可以在计算过程中自动帮我统计表达式树的信息,在这个过程中完成合并同类项等工作。显然Expression本身也是Computable,这样就可以用一个表达式树“计算”出一个新的表达式树。
当然实际体验来看,这个写法也不是很优雅,基于这个写法造出来的优化容器一般都会比较令人感到暴躁,而且很难再保证开闭原则。
但是考虑到优化这事儿本来就是面向作业的,我也就姑且接受这个有点坏味道的设计了。
其实也考虑过别的替代方案,比如是不是可以干脆把工厂用上,再拓展一套自带合并同类项的表达式结点类出来,后来由于时间关系没有这样写。
优化与输出
第一次作业无脑合并同类项就好了,其实没啥好说的
第二次作业三角函数合并,我的优化方法可以见我的另一篇博客
第三次作业其实只写了一下合并同类项,因为怕写得多了反而出错,权衡一下收益并没有深入(然后还是出错了QAQ)
其实第三次也是可以划归到合并三角函数的:对于每一个表达式,我们如果可以定义其哈希值,那么sin(x)与sin((x^2+1))便显然可以以x和x^2+1作为两个sin的键,其指数作为值,这样键值关系就出现了,便依然可以做到对于每个三角函数迅速找到与其对应的cos^2 sin^2 与 1。于是就可以用类似第二次的方法进行优化。但是考虑到嵌套因子的存在,这个优化所需的时间开销应当是会比第二次大不少的。
(这里期待一下这次99+大佬们的优化思路)
测试
从主JUnit辅黑箱逐步转变为主黑箱辅JUnit(翻车的导火索)
还是太懒太盲目自信了,驱动测试开发依旧没有做到
希望接下来可以把测试再好好落实一下
关于具体的测试方法,讨论区和研讨课也已经充分讨论了,这里不多展开
一些量化分析
首先是结构复杂性
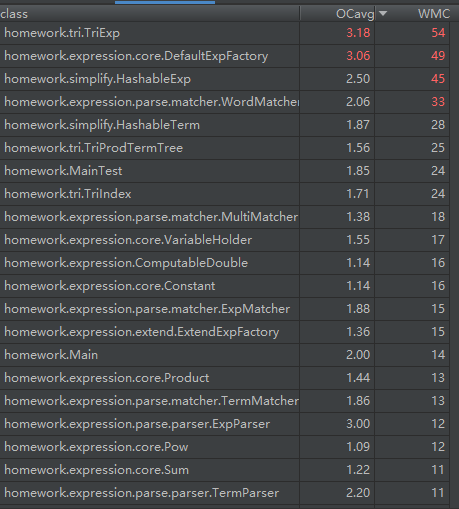
(这里按从高到低的排序,并没有全部截取
可以看到,结构最复杂的代码不出所料地集中在了三个地方:优化、输入词法解析器和工厂。这三个地方的结构复杂原因各不相同。
优化的部分复杂是因为,优化逻辑本身并没有被很好地抽象,这部分写的时候更像是在面向过程。我个人认为这个部分复杂不是什么坏事,因为一开始就考虑优化可能是整个代码中最混沌的部位,因此需要单独把它拎出来点杀,这样所有坏味道代码都被集中起来维护,不影响程序的其他部分。
词法解析这里复杂则完全是设计上的失误了。实际上前两次作业的时候,花了大量精力去维护符号运算的部分,解析器这里写的却比较敷衍,这个类一开始就同时承担了模式匹配和将匹配到的子串转为表达式两个功能,直到第三次作业尝试扩展的时候才发现问题:这个设计并不能很好地拓展匹配带有嵌套的表达式。因此第三次作业在这里打了大量补丁,复杂程度骤增。索性没有导致太严重的问题
工厂这里则是迫不得已写的很复杂,毕竟和优化一样,也是集所有混沌于一身的一个类。除此之外,第三次作业写的有些放飞自我,很多本来应该写到优化器的优化直接写死在了工厂里面(比如连乘时维护常数算子永远是乘式的第一个算子),也进一步加剧了这个类的复杂程度。
依赖分析
插件出了点问题,索性直接用idea自带的依赖矩阵看一下

循环依赖问题不是特别严重,主要是输入解析器间的依赖(因为有递归关系)和表达式结点间轻微的循环依赖,后者是因为提交作业前考虑一些优化时的特殊情况,打了个补丁,导致三角函数表达式结点输出时需要依赖其他结点类判断是否应该套括号——这里显然是不符合开闭原则的,但是考虑到ddl大限将至顾不了这么多了。
总结
自己的Bug
这个单元最后还是有了一个bug,成因还是比较复杂的……
我认为写程序和人体的免疫一样,有三道防线:
- 优秀的架构与细节设计。优秀的含义很广泛,清晰、可读、易维护、易扩展的设计往往是鲁棒的,这样的设计往往很难出现严重的纰漏,因为很多错误已经被规避掉了,即使有错误,发现、纠正的难度也不会太大
- 内陷的异常、错误与断言。这些人为指定的运行行为是最容易帮助我们发现并定位潜在问题的
- 充分的测试,黑箱测、白箱测、压力测、让老妈帮你测,总之测就完事儿了。
出现bug往往是因为这三道防线被全部突破,无险可守了。
这次的bug实际上正是因此造成的:
- 优化部分的设计有潜在问题,一个
Term类既可以是一个乘积项,也可以是一个单独变量,这并不符合单一职责原则,导致输出的时候存在风险(一个乘积项被误认为是一个x,优化掉了括号导致输出格式错误) - 虽然编程的时候预见了这个问题,加了一个
assert断言确保行为正确,但是并没有打开虚拟机的-ea选项导致程序里的断言全部失效……这里其实是对语言的不熟悉,自以为是地用python的写法写java。好在并没有造成太严重的损失。早早踩掉一个危险的大坑其实是好事,总比之后在更复杂的工程中因为这种事情吃瘪要好……这里的处理方式目前按个人理解有两种:- 以后用断言后记得手动打开
-ea,当然我觉得这样就并不优雅了,似乎java的assert定位主要是用于测试 - 以后尽量定制异常/错误类,使用分支+异常来代替
assert,这样的好处是traceback的时候更加清晰,而且不会因为vm选项的问题再吃瘪,坏处是又要增加代码长度了……
- 以后用断言后记得手动打开
- 第三次作业的测试的确不充分,主要是刚好那周各种事情交替在一起……优化输出模块的单元测试几乎没有,测试用例大部分是前两次作业祖传的。测黑箱的时候又没有检查输出格式,直到互测前夕才突然想起来测一下这个东西,然后很快就把这个bug拍出来了,好气哦
一个bug反应了好多问题,这就是活生生的海因里希法则啊,太真实了
别人的Bug
别人的bug里我大概能总结这些:
- 一个长度超过30个字符的正则表达式就已经可以逼疯代码维护人员了,今后我个人会尽量避免写出这样的代码,除非真的万不得已。
- 面向对象不一定比面向过程优越,但是优秀的封装一定比糟糕的封装优越。第一次作业中很多同学的代码,即使以C语言的角度看也是存在很多问题的:冗余、欺骗性变量名、0注释、流程混乱,完全没有封装、模块化设计的意识,所有东西都耦合在一起。这就像在松散的沙地上盖房子,即使上层加工地再精致,思路再清奇,根基不稳,最后大厦还是会一吹就倒。
- 大家的进步速度很迅猛,我也是加把劲骑士
展望
这三周,有自己满意的东西,也有自己不满意的东西,吸取了教训,积累了经验,总的来说还是ok的。
下周进电梯了,正好手头乱七八糟的事情逐渐搞定了,希望接下来能真正全力以赴开心OO啦。