一、主题 :
爬取博客园博问上160页每页25条帖子标题,利用jieba分词生成词云进行分析
二、python爬取数据
博问主页:https://q.cnblogs.com/list/unsolved?page=1
第二页:https://q.cnblogs.com/list/unsolved?page=2 以此类推……
可得160页bkyUrl地址
for i in range(1,161): bkyUrl = "https://q.cnblogs.com/list/unsolved?page={}".format(i)
通过浏览器查看博问主页元素:
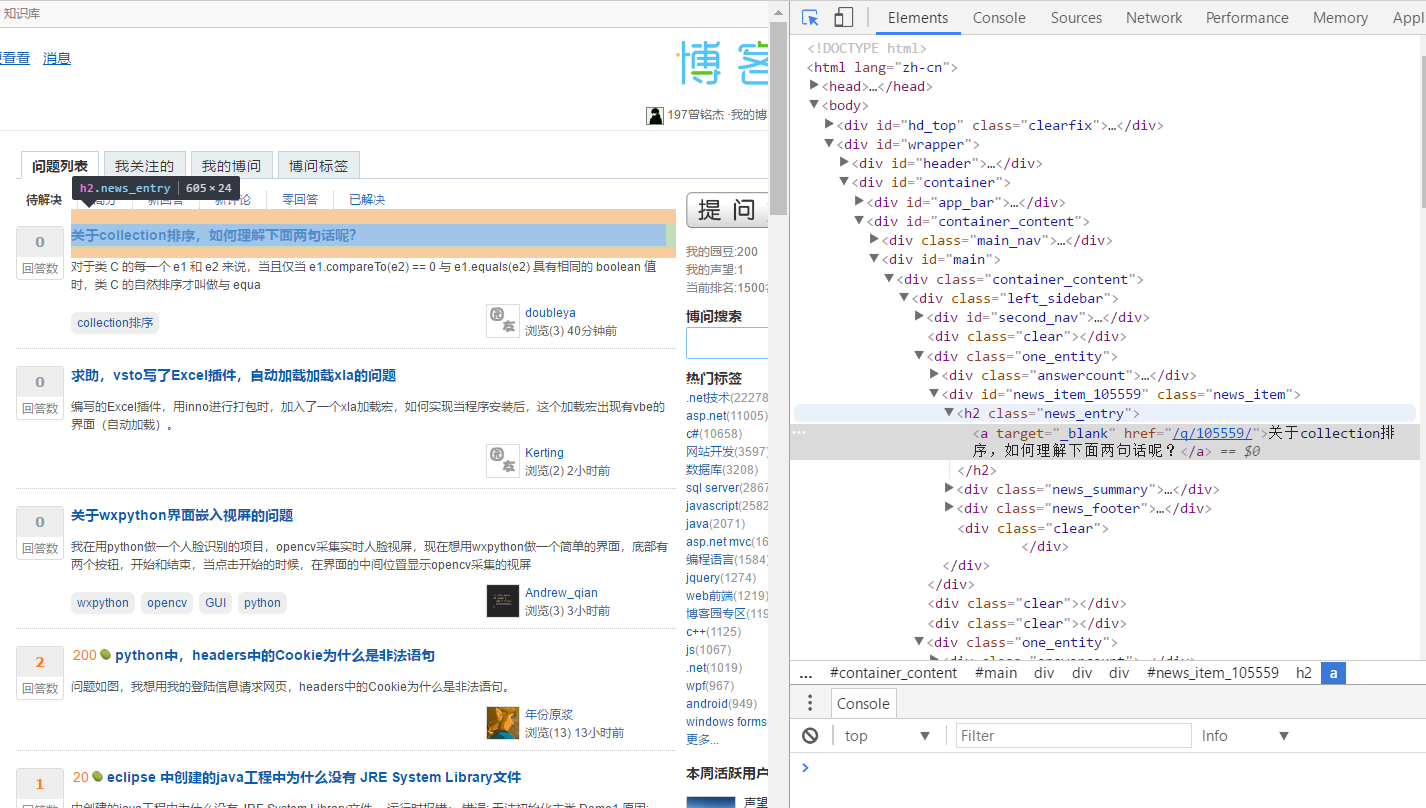
观察可得在主体div类为.left_sidebar标签下有25个标签h2、h2标签内a标签文本即为各博问贴子标题
因此可得getpagetitle函数获取每页25条博问贴子标题:
def getpagetitle(bkyUrl): time.sleep(1) print(bkyUrl) res1 = requests.get(bkyUrl) # 返回response对象 res1.encoding = 'utf-8' soup1 = BeautifulSoup(res1.text, 'html.parser') item_list = soup1.select(".left_sidebar")[0] for i in item_list.select("h2"): title = i.select("a")[0].text
将上述操作整合一起,获取160 * 25 条博问标题
import requests import time from bs4 import BeautifulSoup def addtitle(title): f = open("F:/study/大三/大数据/title.txt","a",encoding='utf-8') f.write(title+" ") f.close() def getpagetitle(bkyUrl): time.sleep(1) print(bkyUrl) res1 = requests.get(bkyUrl) # 返回response对象 res1.encoding = 'utf-8' soup1 = BeautifulSoup(res1.text, 'html.parser') item_list = soup1.select(".left_sidebar")[0] for i in item_list.select("h2"): title = i.select("a")[0].text addtitle(title) for i in range(160,161): bkyUrl = "https://q.cnblogs.com/list/unsolved?page={}".format(i) getpagetitle(bkyUrl)
保存标题title.txt文本:

三、生成词云:
将文本中标题信息以string类型读取出来,利用jieba进行分词,去除一些标点符号和无用词(这里做的不够细致),生成字典countdict:
def gettitle(): f = open("F:/study/大三/大数据/title.txt","r",encoding='utf-8') return f.read() str1 = gettitle() stringList =list(jieba.cut(str1)) delset = {",","。",":","“","”","?"," ",";","!","、"} stringset = set(stringList) - delset countdict = {} for i in stringset: countdict[i] = stringList.count(i) print(countdict)

进行文本分析生词词云:
from PIL import Image,ImageSequence import numpy as np import matplotlib.pyplot as plt from wordcloud import WordCloud,ImageColorGenerator graph = np.array(countdict) font = r'C:WindowsFontssimhei.ttf' backgroud_Image = plt.imread("F:study大三大数据\background.jpg") wc = WordCloud(background_color='White',max_words=500,font_path=font, mask=backgroud_Image) wc.generate_from_frequencies(countdict) plt.imshow(wc) plt.axis("off") plt.show()
这里使用background.jpg作为背景图:

生成词云图如下:

从词云图就能很直观的看出博问上锁提出问题大部分集中在数据库、python、C#和Java.
四、爬取数据过程中遇到的问题:
爬取标题数据信息的过程比较顺利,主要问题出现在wordCloud的安装过程中:
安装worldCloud有两种方式:
一是在pycharm中进入File-setting-proje-Project Interpreter、通过install worldCloud 安装包
二是在
https://www.lfd.uci.edu/~gohlke/pythonlibs/#wordcloud 中下载对应python版本和window 32/64位版本
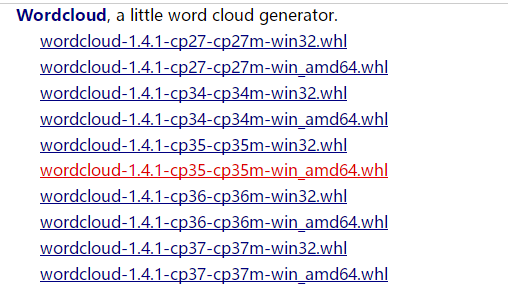
我的python版本是3.6,win10 64位系统,所以下载
这里把下载文件放在F盘
cmd命令行进入对应wordcloud安装路径,我是放在F盘,所以进入F:
输入 pip install wordcloud‑1.4.1‑cp36‑cp36m‑win_amd64.whl 即可成功导入
但是在执行方法一的时候总会出现这个错误提示:

解决办法应该是安装Microsoft Visual C++ 14.0,但是文件比较大,没有进行过尝试,所以使用方法二
执行二方法:
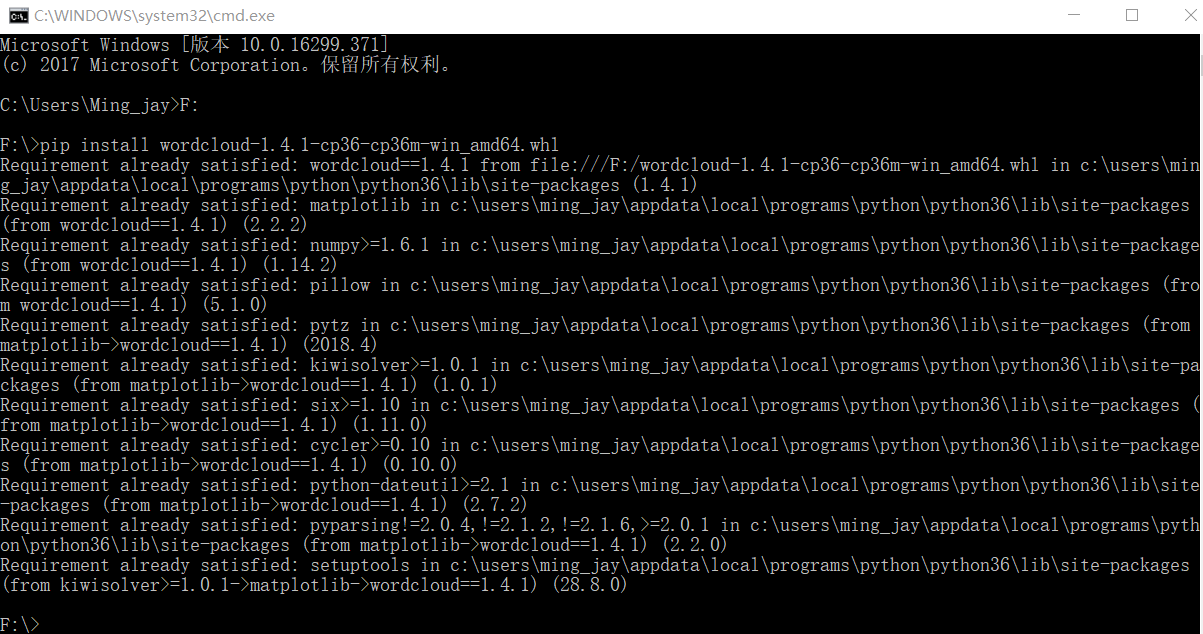
可以看到wordCloud已经安装到

中,如果在这之后没有在pycharm File-setting-proje-Project Interpreter看到wordCloud包,就需要手动在上图路径中找到wordCloud,复制到C:User - PycharmProjects**vervlib 中即可,(**表示自己创建的项目名字)

五、总结
利用python爬取数据生成词云的过程还是很有趣的,本来想通过python爬取博客园各博主圆龄,但必须要登录博客园后才能进入各博主主页,目前所学还没办法做到以用户身份爬取数据,此后会继续学习研究~!!