需求
爬取百度搜索某个关键字对应的前一百个网址。
实现方式
VS2017 + Chrome
.NET Framework + C# + Selenium(浏览器自动化测试框架)
环境准备
创建控制台应用程序,通过NuGet添加对Selenium的引用
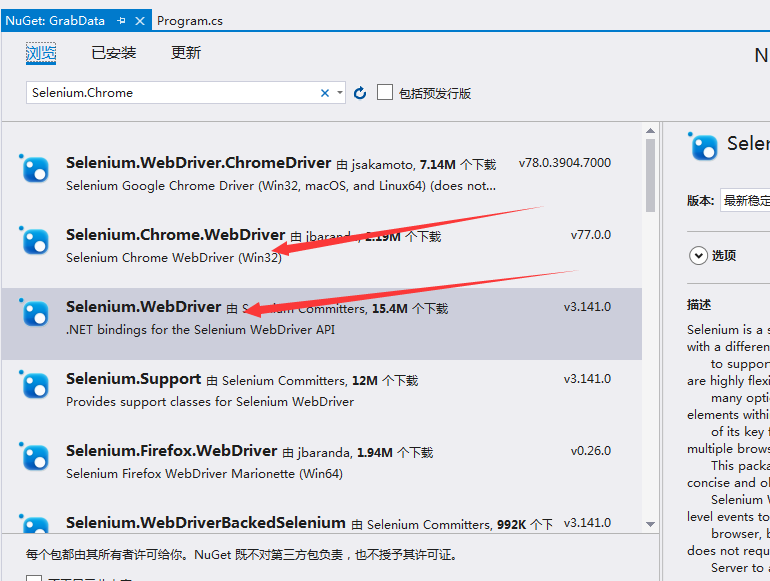
这里因为我用的Google浏览器,所以添加这两个的引用。
代码输出
1 static void GrabUrlByKeyWord(string keyWord) 2 { 3 //创建chrome驱动程序 4 IWebDriver webDriver = new ChromeDriver(); 5 //跳至百度 6 webDriver.Navigate().GoToUrl("https://www.baidu.com"); 7 //找到页面上的搜索框 输入关键字 8 webDriver.FindElement(By.Id("kw")).SendKeys(keyWord); 9 //点击搜索按钮 10 webDriver.FindElement(By.Id("su")).Click(); 11 }
运行看一下效果先
1 static void Main(string[] args) 2 { 3 GrabUrlByKeyWord("香香瓜子"); 4 }
是不是感觉太简单了,这么快就来到目标页面了(这么想就太天真了。。)
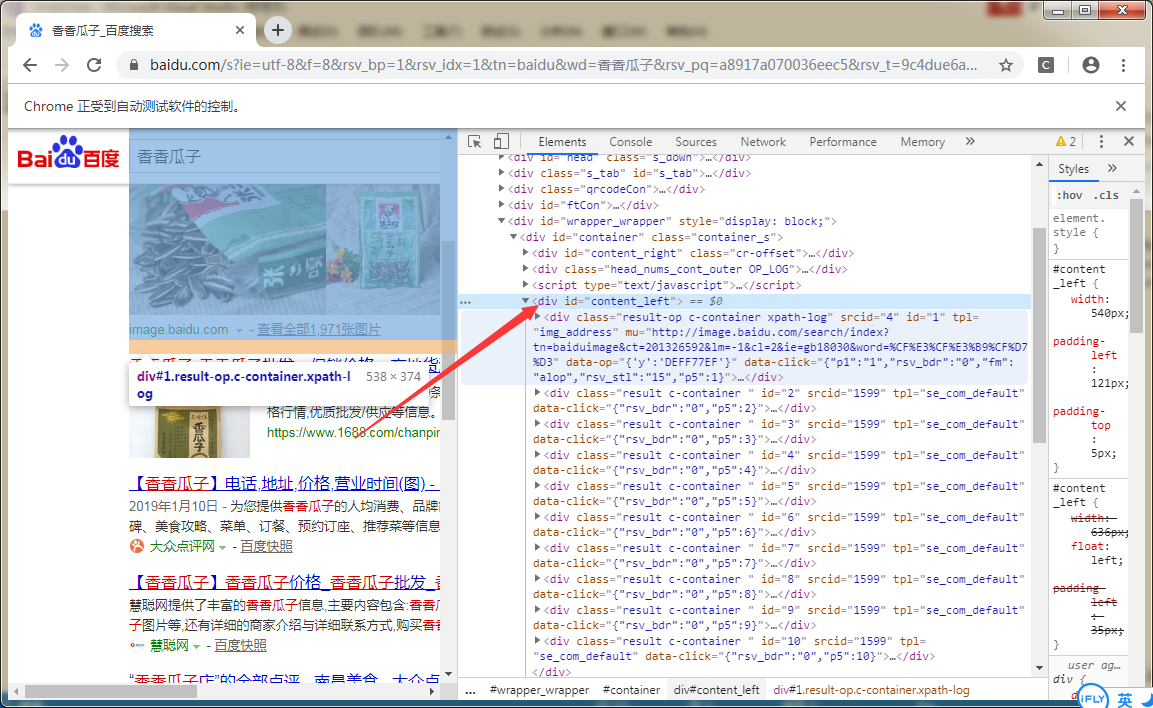
F12,观察发现搜索结果都在一个id为content_left的div中,进一步解刨
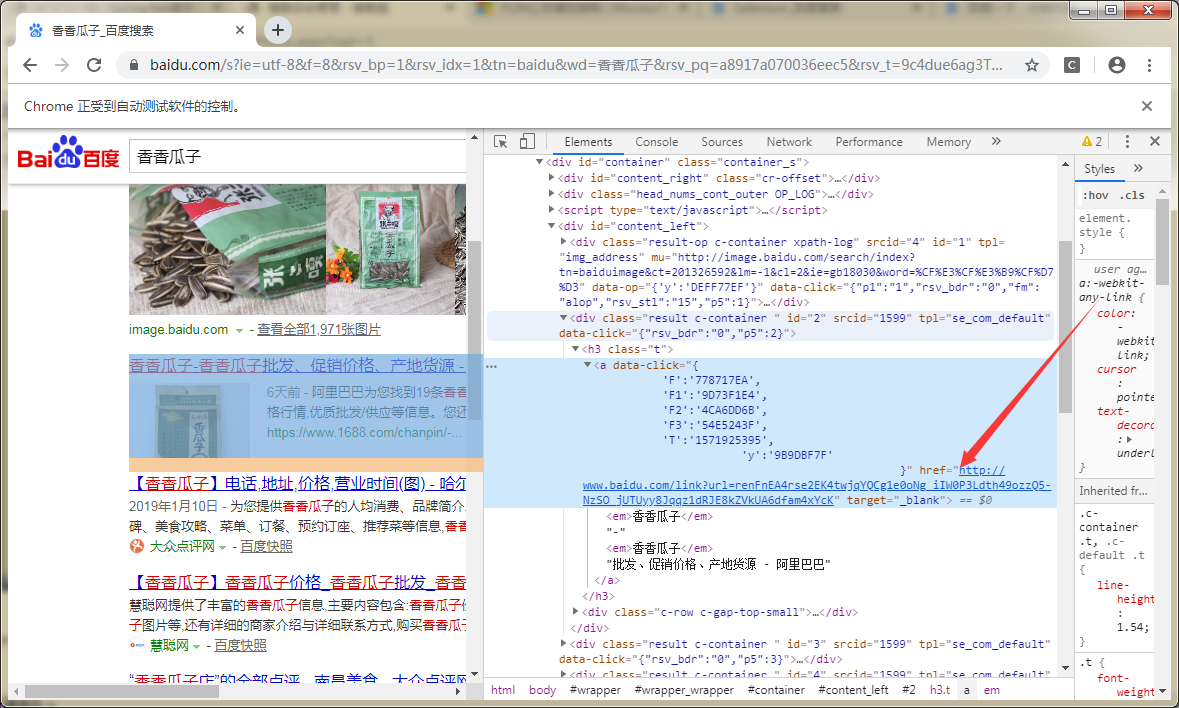
百度对目标做了中转,最关键的是它对目标url做了加密。。。
那么?问题来了,我们怎么获取到目标真实的网址呢?
当然,方法有很多:
①可以通过Selenium模拟真实操作,每个结果都点进去,获取地址栏的网址;(这样效率是不是太低了。。。)
②解密;(目前我还没有找到解密方法。。。)
③后台通过HttpClient发送请求,获取url;
......
......
......
把想说的思想总结一下:
使用HttpClient一个一个去请求的地址来获取真实地址的话,这样效率很低,
使用PLINQ并行查询 或 多线程 的话,效率变高了,但是它的执行顺序是不定的,
我们需要的结果又是排名的顺序,这时候可以把操作对象封装成不依赖顺序的model,
例如给model加一个rank排名属性,后期可以根据该属性进行处理。
贴一段来自Microsoft的文本:
虽然可以指示 PLINQ 暂留任何源序列的顺序,但这会对性能产生不利影响。 最佳做法是,尽量将查询的结构设计为不依赖顺序暂留。