在上文中我们已经安装好了web scraper现在我们来进行简单的爬取,就来爬取百度的实时热点吧。
http://top.baidu.com/buzz?b=1&fr=20811
文本太长,大部分是图片,所以上下操作视频吧,视频爬取的是昵称不是百度热点数据
链接:https://pan.baidu.com/s/1W-8kGDznZZjoQIk1e6ikfQ
提取码:3dj7
爬取步骤
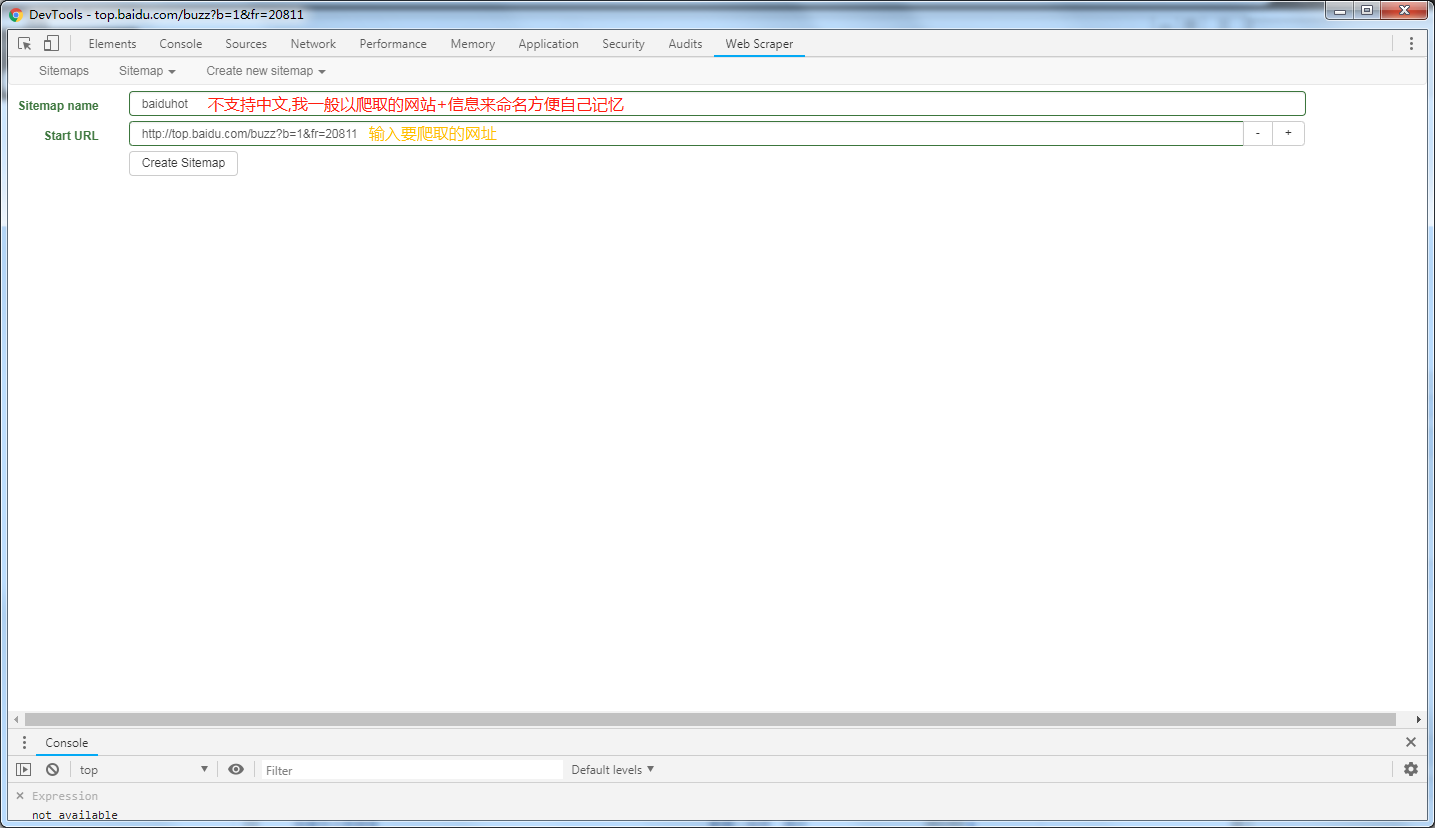
创建站点
打开百度热点,ctrl+shit+i进入检测工具,打开web scraper创建站点
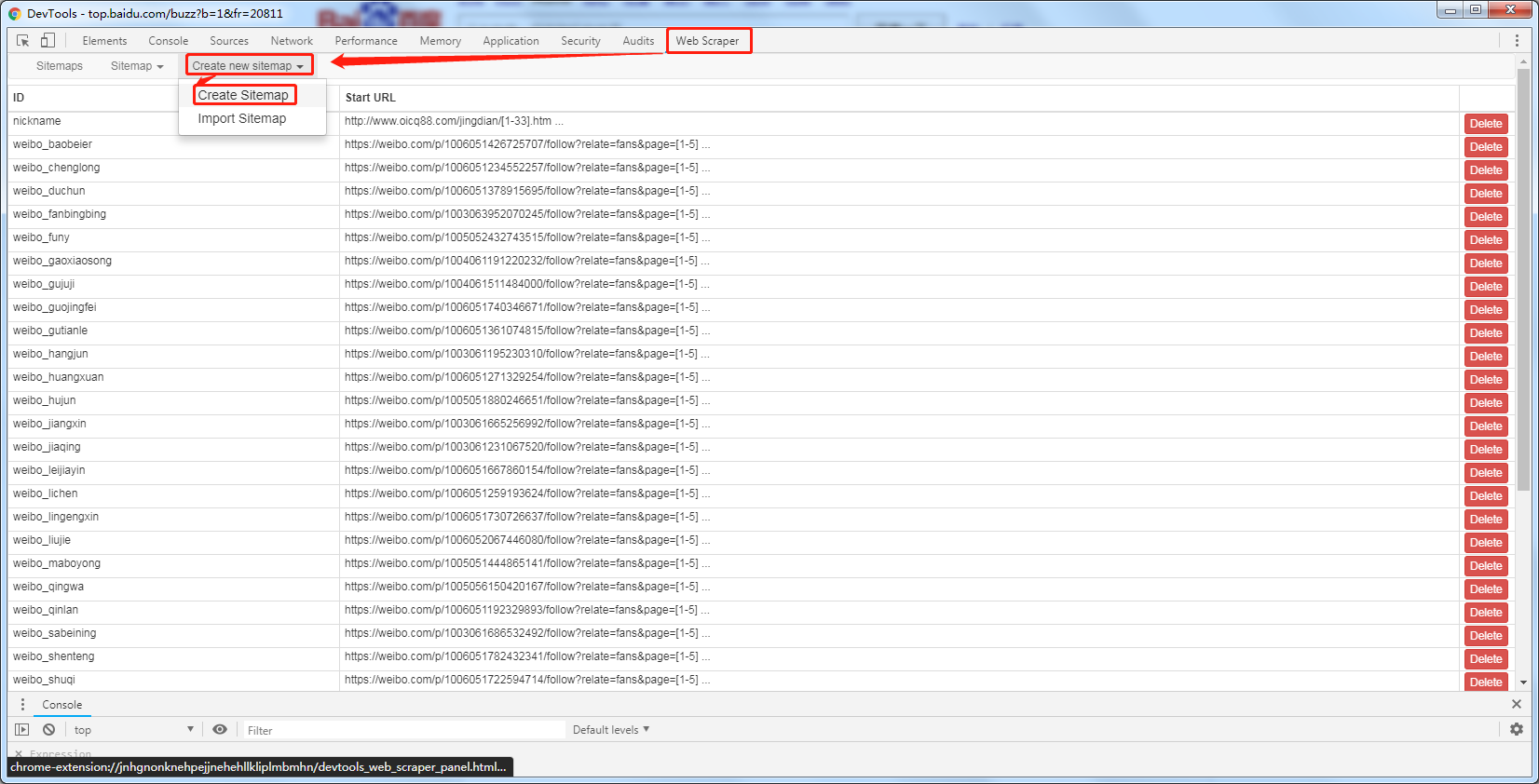
进入 创建站点页面 站点名称和爬取地址点击创建站点即可
如果要爬取分页数据那就将参数写成范围的如:
想要爬取微博某博主关注列表的1-5页的粉丝信息,通过url的跳转发现微博关注列表和<number>数字有关
https://weibo.com/p/1003061752021340/follow?relate=fans&page=<number>
所以只要把<number>写成一个范围的即可
https://weibo.com/p/1006051234552257/follow?relate=fans&page=[1-5]
爬取数据
首先创建一个element的select
创建element信息
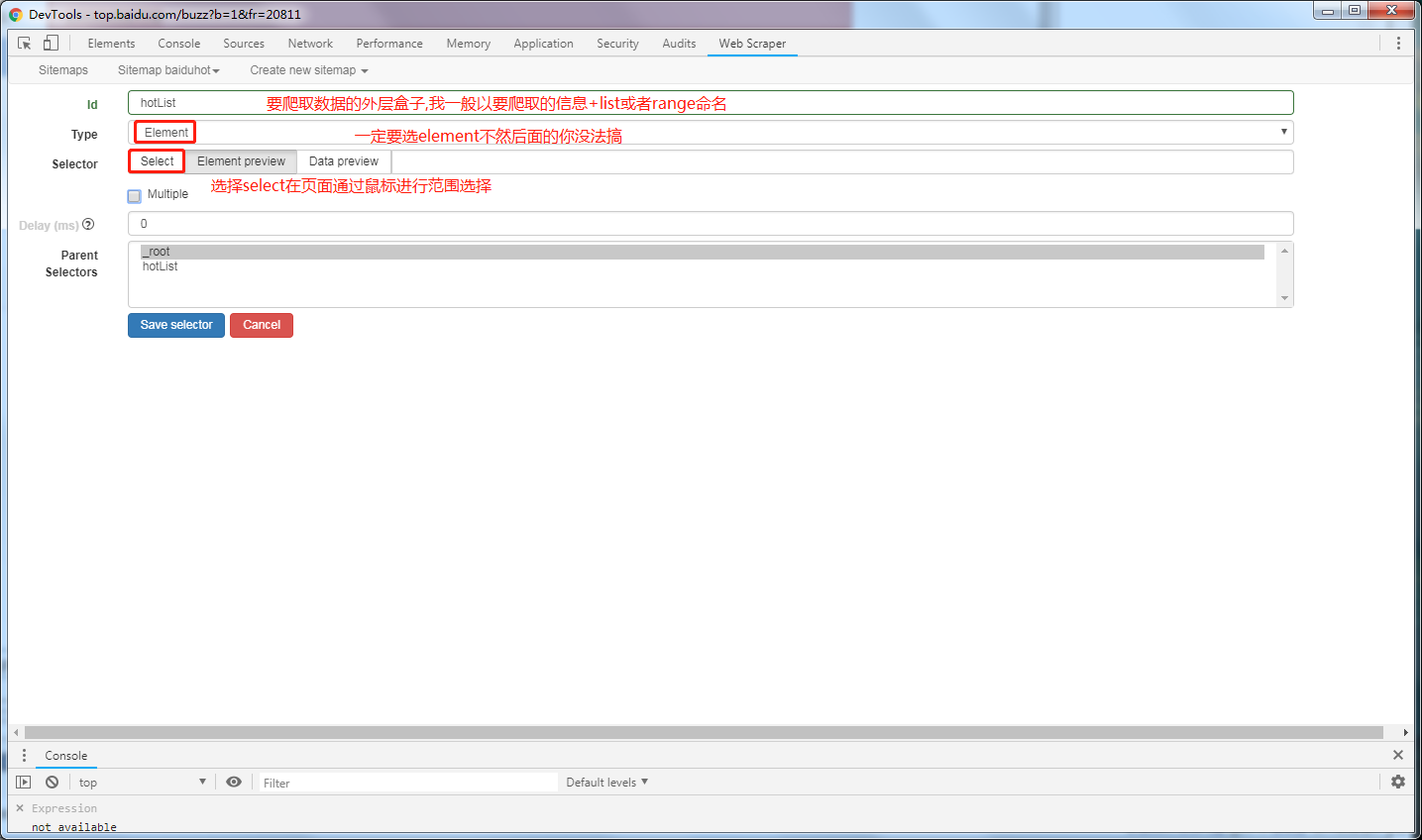
select选择最外层的盒子,确认无误后点击Done selecting!
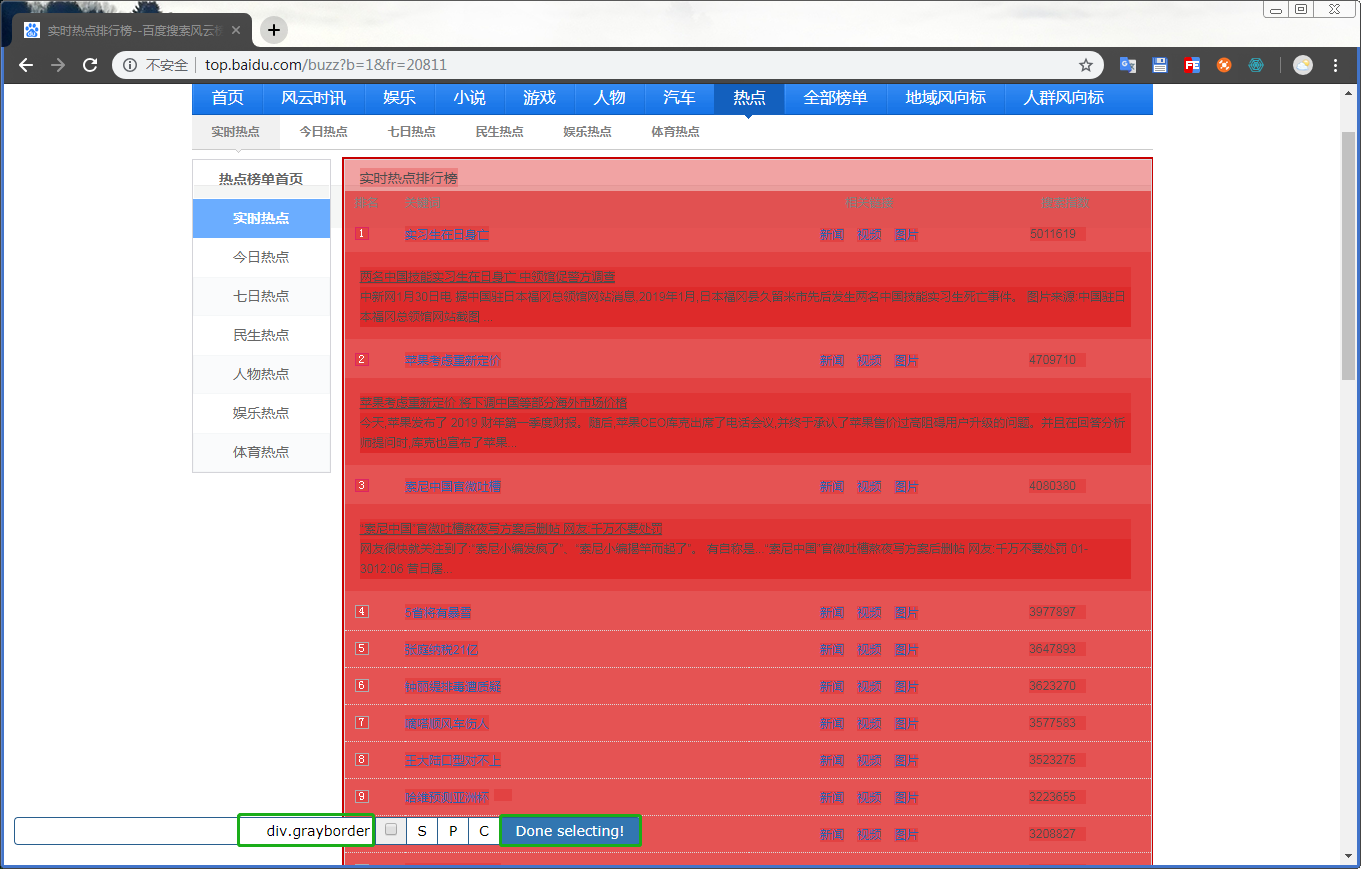
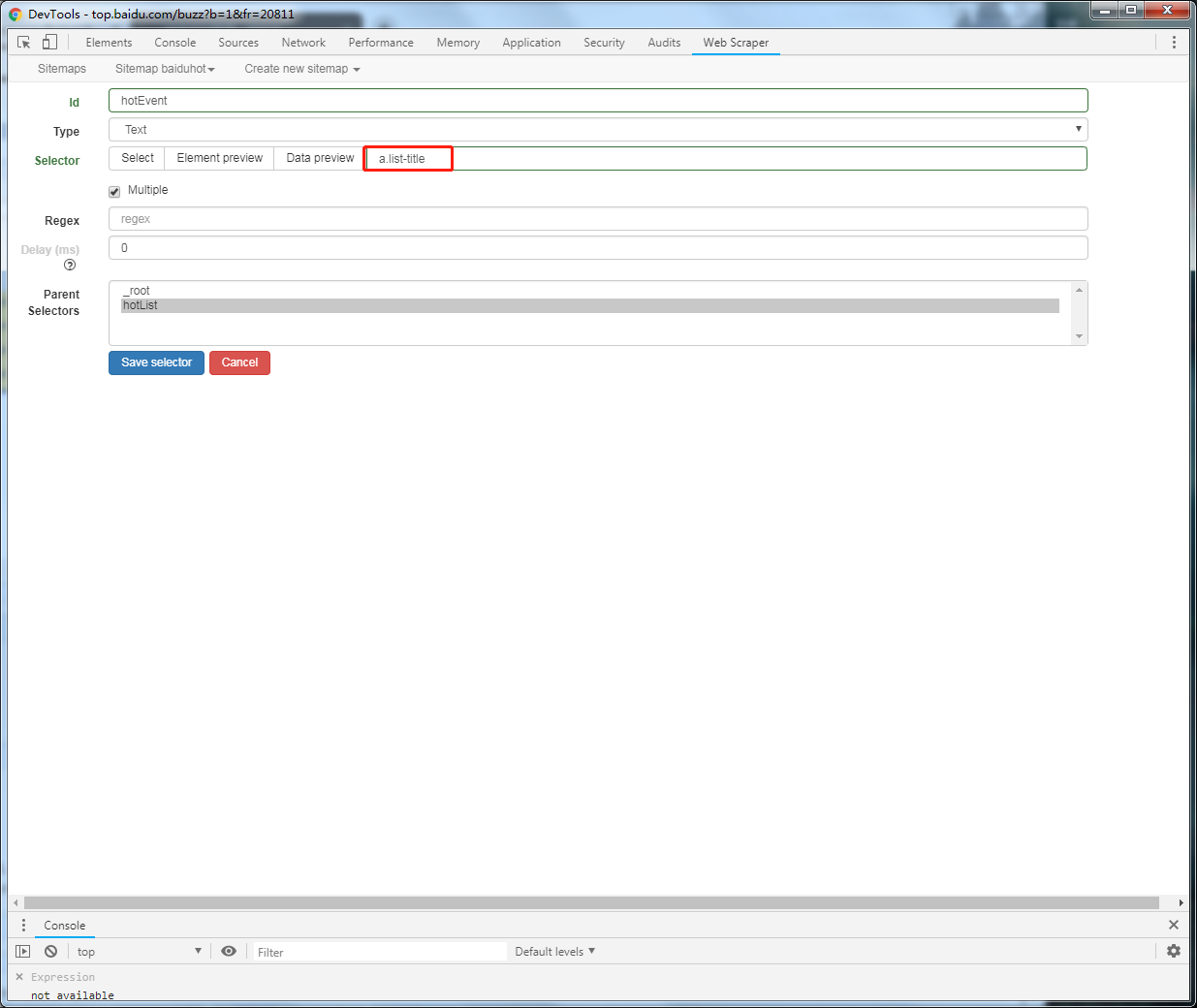
然后回到web scraper控制台,查看信息无误后勾选multiple确认无误后,创建element的select

爬取自己想要的信息,点击进入hotList里面,然后继续创建select选择
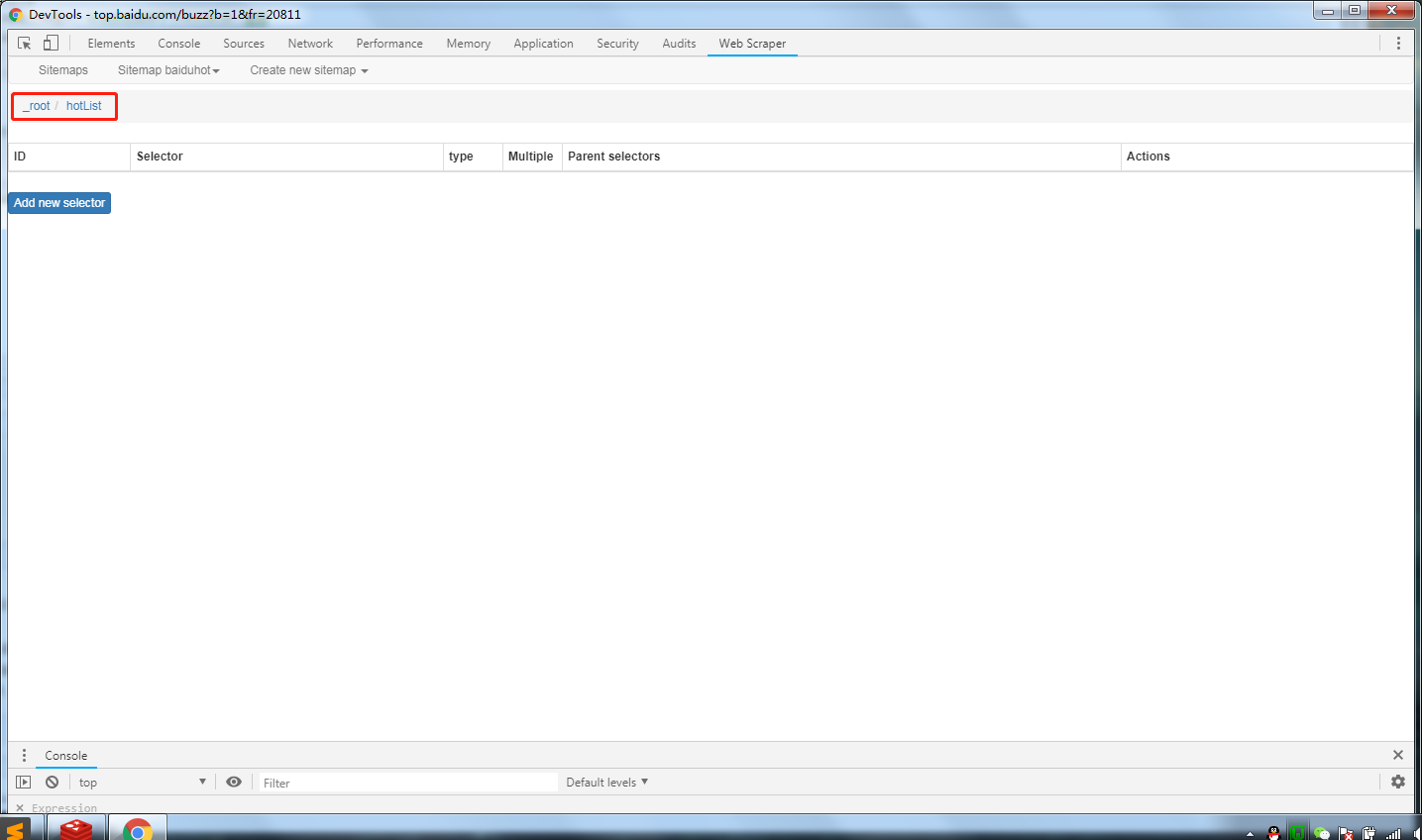
填写具体的select信息,并继续通过select来进行选择需要的数据
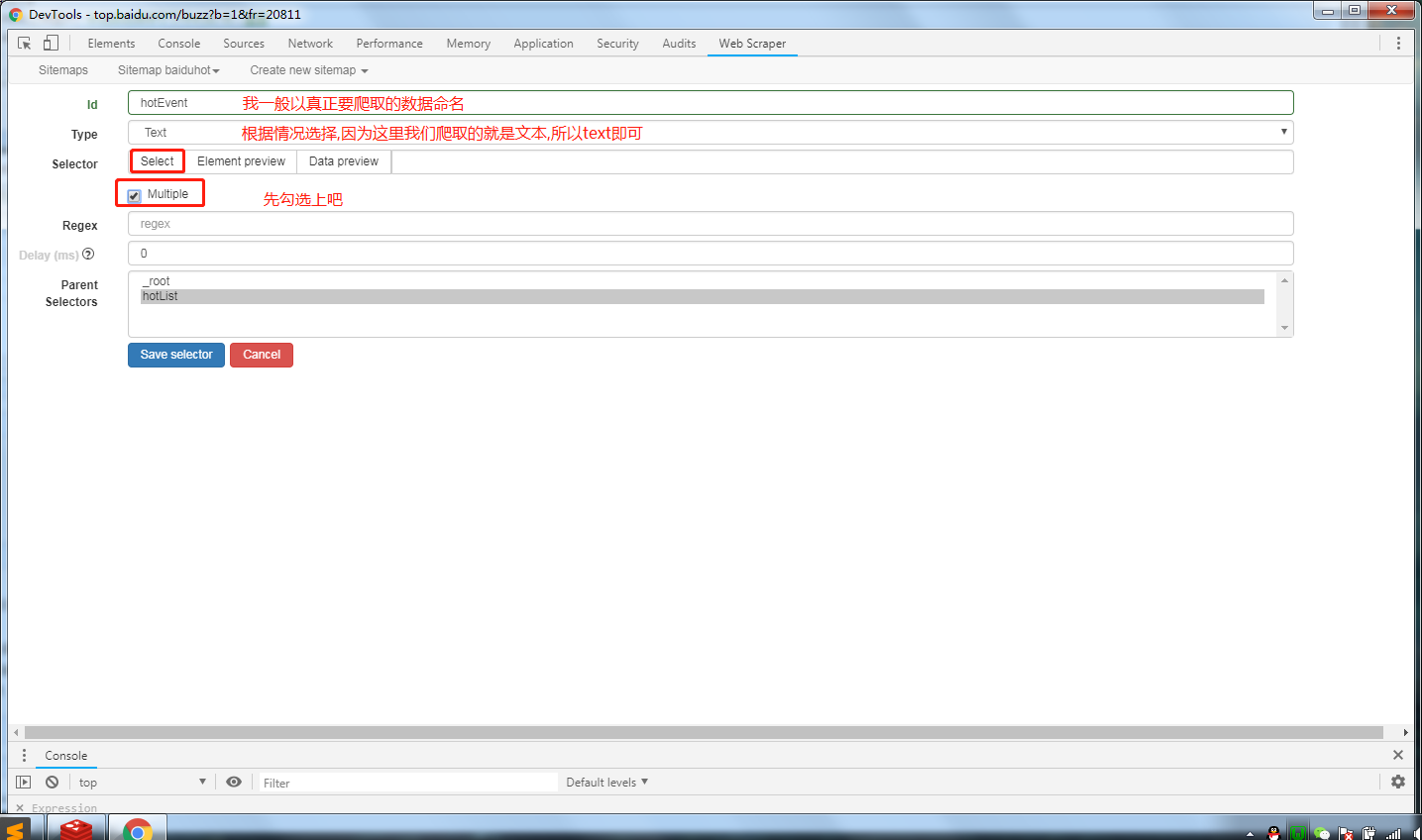
这时候页面的范围会变为黄色,鼠标移动到自己需要的信息处会有绿框将信息圈出来
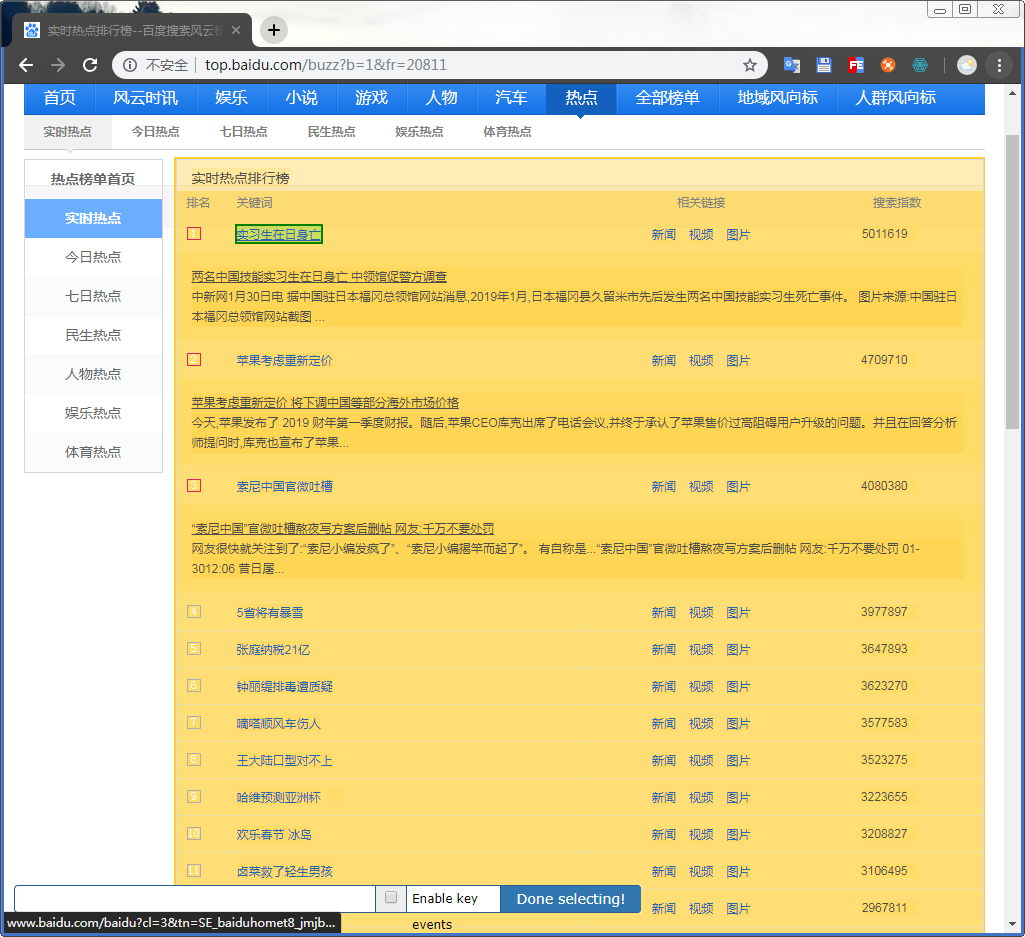
点击确认后会变为红色的,再次选择相同的会自动识别将同样标签下的包围起来,确认是自己需要的信息后直接Done selecting!
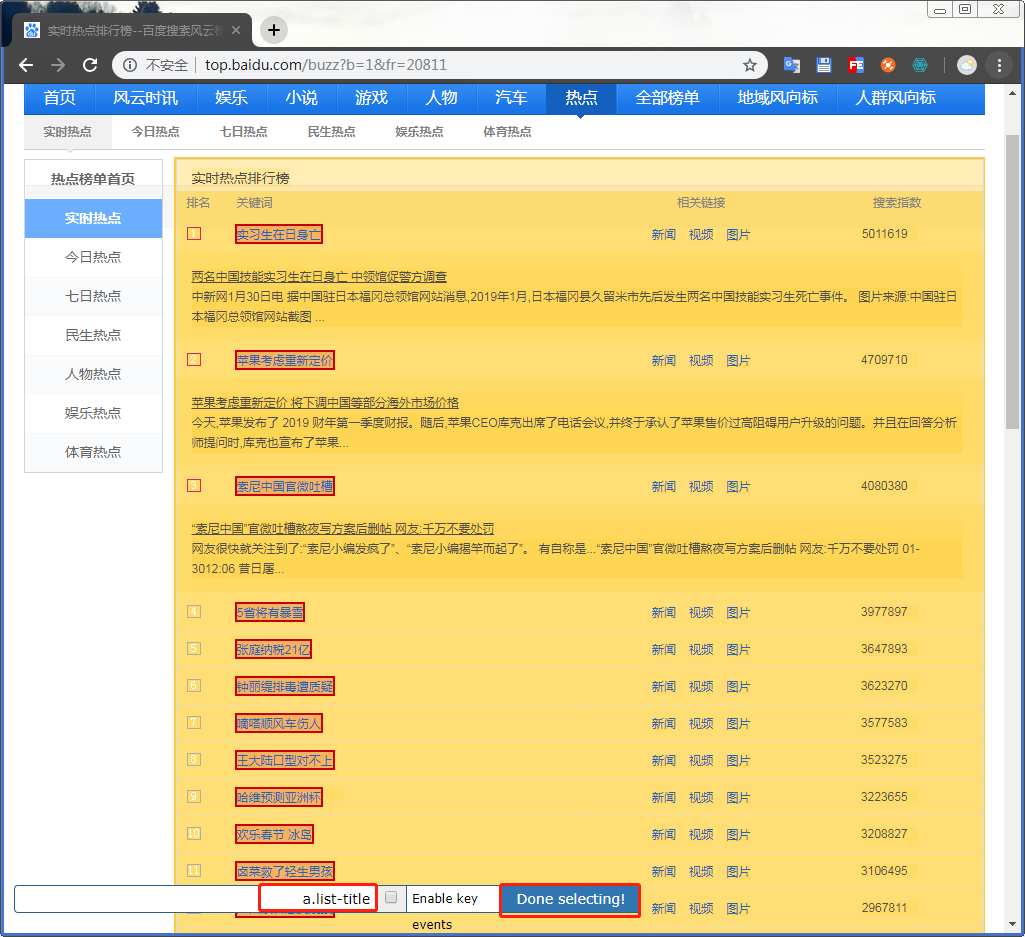
再次转到web scraper的控制台后,确认无误即可保存
运行脚本,进行采集
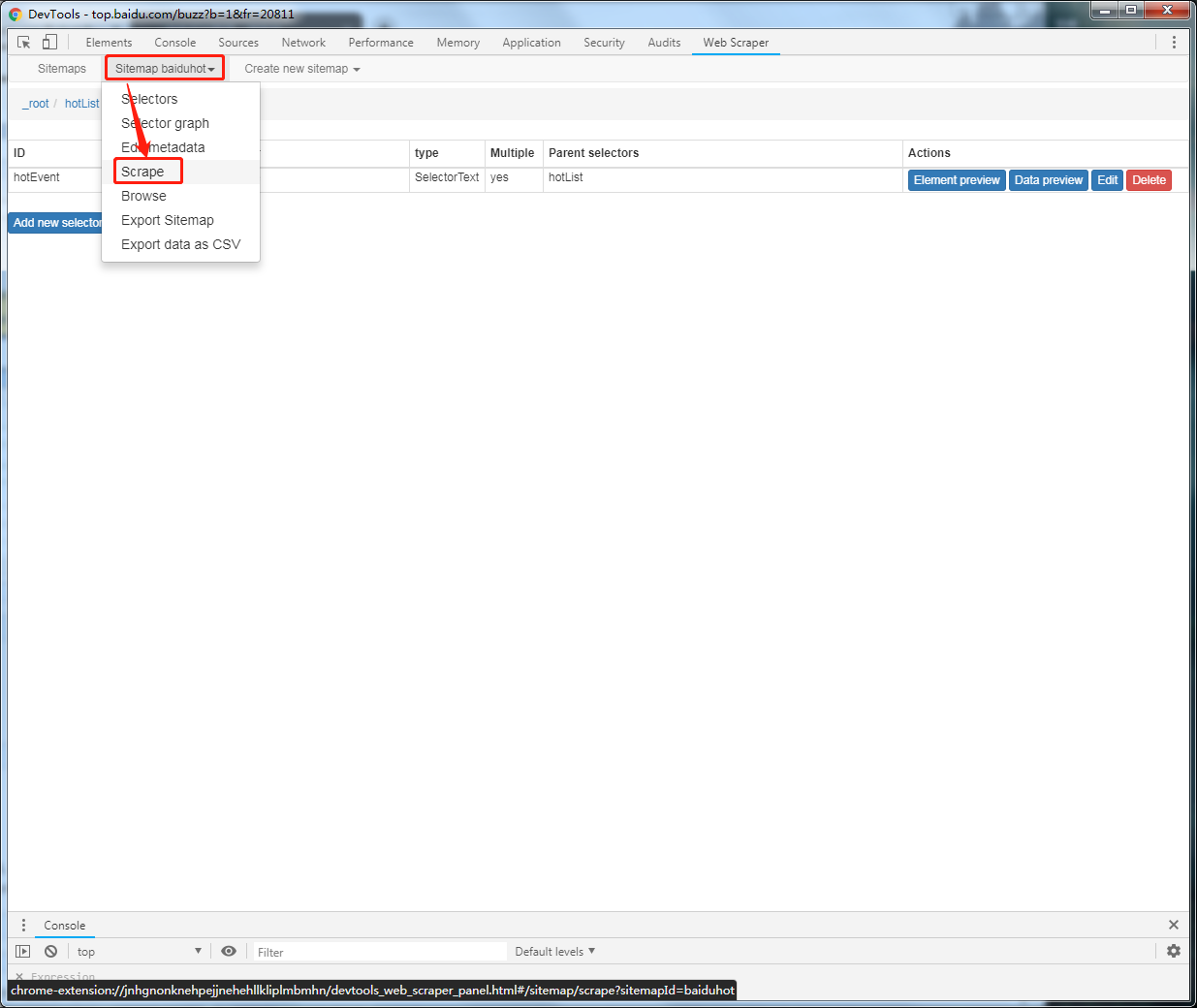
默认配置即可,想修改也可以的,我一般直接默认的

点击开始脚本后,会将采集的页面弹出,采集完成右下角会出现提示,采集过程中点击refresh可以查看采集的数据
采集的数据
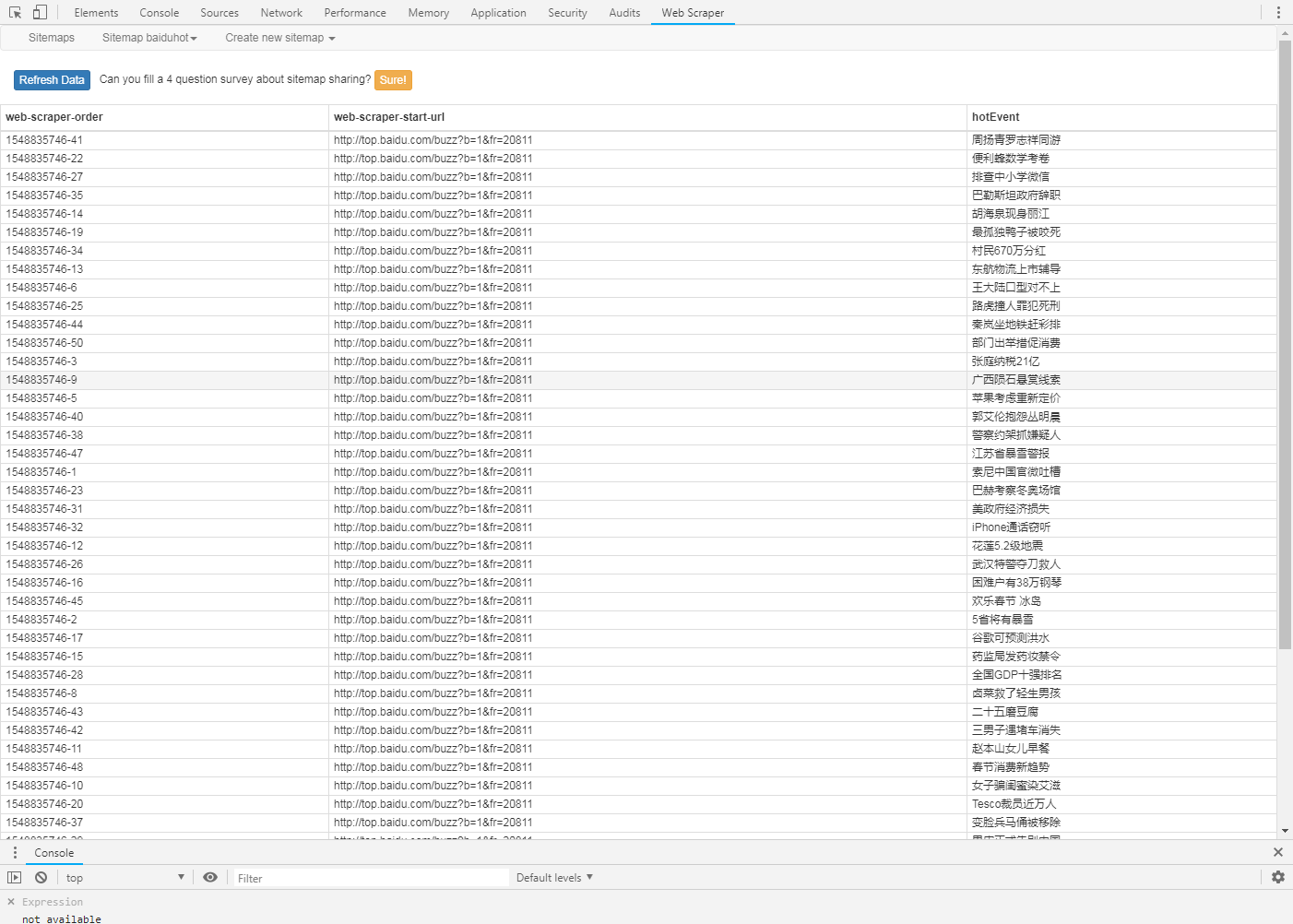
导出数据
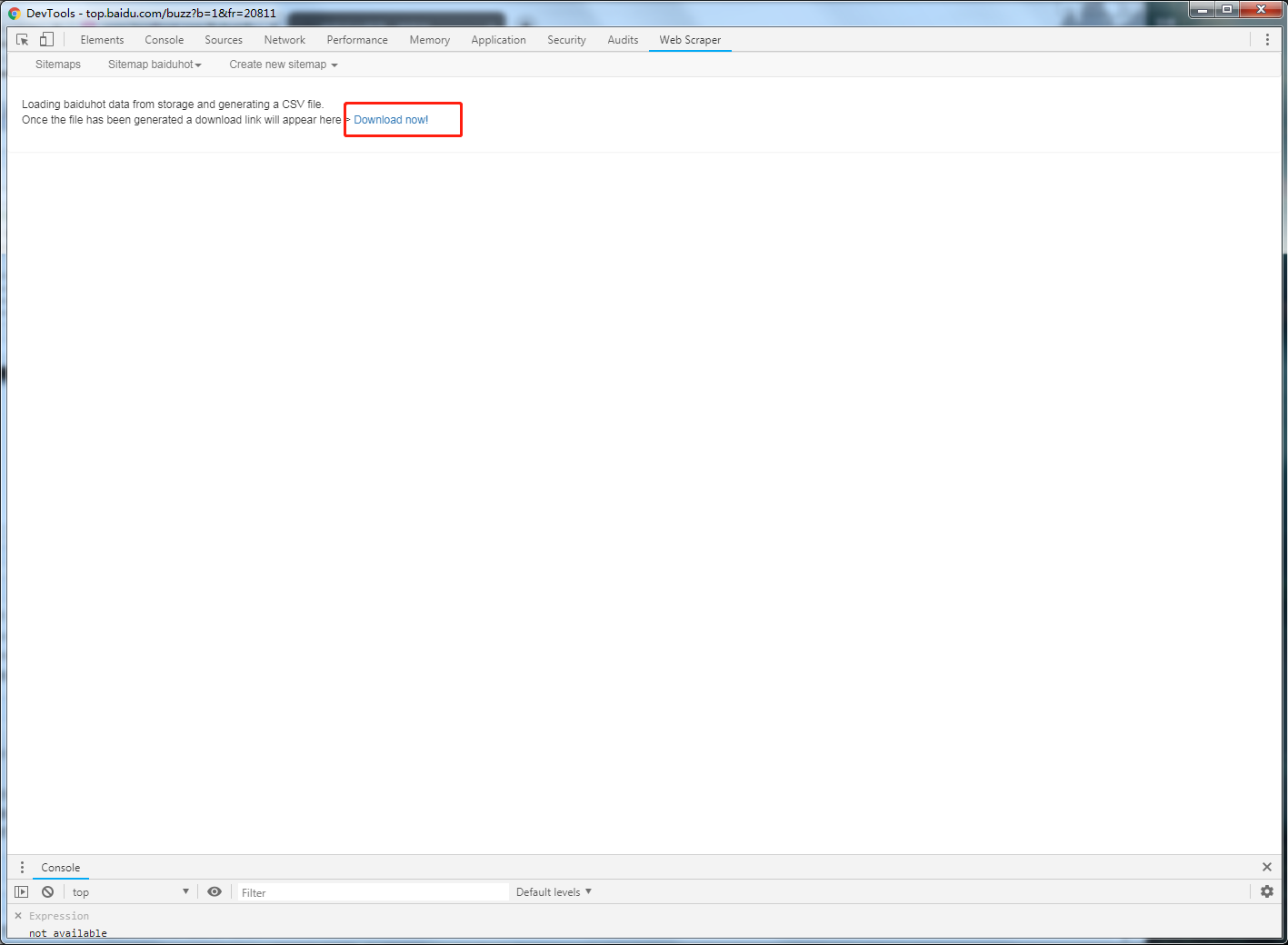
确认数据没有错误,是自己需要的即可,进行下载,以csv格式导出

点击Downolad now!即可下载
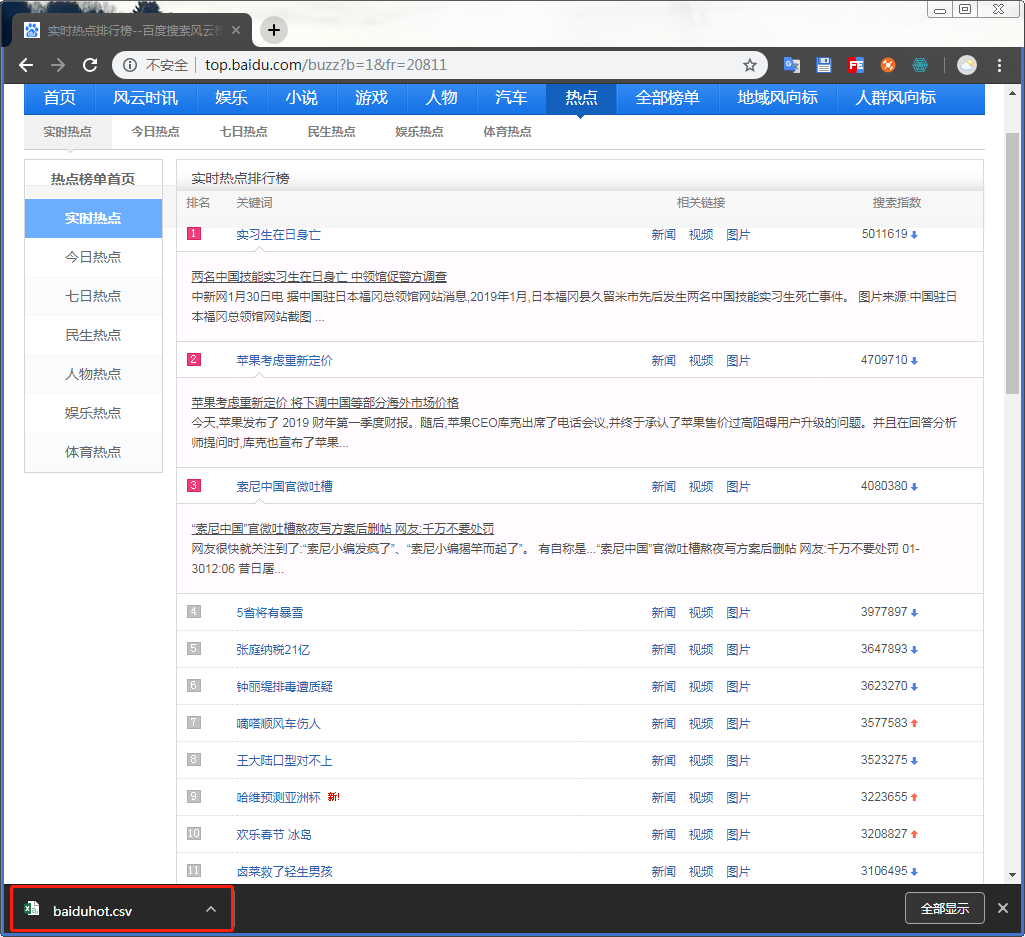
数据内容

到这里使用web scraper进行数据采集就结束了