第1章 Atlas入门
1.1 Atlas概述
Apache Atlas为组织提供开放式元数据管理和治理功能,用以构建其数据资产目录,对这些资产进行分类和管理,并为数据分析师和数据治理团队,提供围绕这些数据资产的协作功能
1)表与表之间的血缘依赖
2)字段与字段之间的血缘依赖
1.2 Atlas架构原理
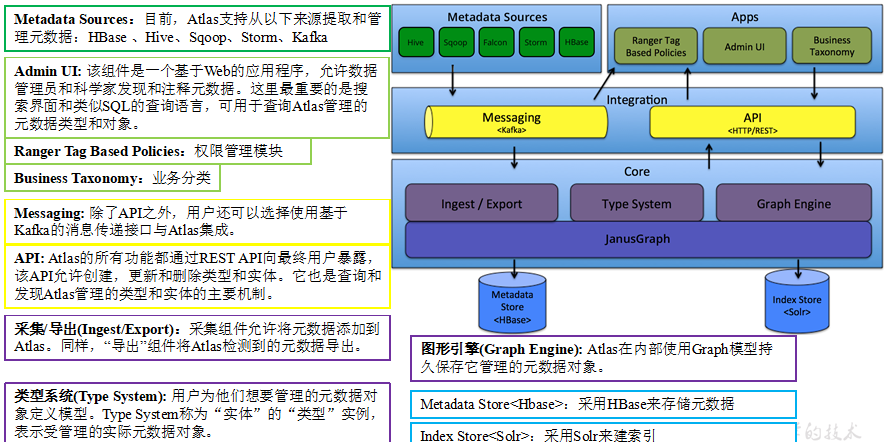
1.3 Atlas2.0特性
(1)更新了组件可以使用Hadoop3.1,Hive3.1,Hive3.0,Hbase2.0,Solr7.5和Kafka2.0
(2)将JanusGraph版本跟新为0.3.1
(3)更新了身份验证支持可信代理
(4)更新了指标模块收集通知
(5)支持Atlas增量导出元数据
第2章 Atlas安装
1)Atlas官网地址:https://atlas.apache.org/
2)文档查看地址:https://atlas.apache.org/2.1.0/index.html
3)下载地址:https://www.apache.org/dyn/closer.cgi/atlas/2.1.0/apache-atlas-2.1.0-sources.tar.gz
2.1 安装环境准备
Atlas安装分为:集成自带的HBase + Solr;集成外部的HBase + Solr。通常企业开发中选择集成外部的HBase + Solr,方便项目整体进行集成操作。
以下是Atlas所以依赖的环境及集群规划,本文只包含Solr和Atlas的安装指南
|
服务名称 |
子服务 |
服务器 hadoop102 |
服务器 hadoop103 |
服务器 hadoop104 |
|
JDK |
√ |
√ |
√ |
|
|
Zookeeper |
QuorumPeerMain |
√ |
√ |
√ |
|
Kafka |
Kafka |
√ |
√ |
√ |
|
HBase |
HMaster |
√ |
||
|
HRegionServer |
√ |
√ |
√ |
|
|
Solr |
Jar |
√ |
√ |
√ |
|
Hive |
Hive |
√ |
||
|
Atlas |
atlas |
√ |
||
|
服务数总计 |
8 |
5 |
5 |
2.1.1 安装Solr-7.7.3
1)上传 solr-7.7.3.tgz 至 /opt/software
2)解压solr-7.7.3.tgz到/opt/module目录,并改名为solr
tar -zxvf /opt/software/solr-7.7.3.tgz -C /opt/module/
mv /opt/module/solr-7.7.3/ /opt/module/solr
3)修改solr配置文件
vim /opt/module/solr/bin/solr.in.sh
#修改如下内容,配置Zookeeper集群
ZK_HOST="hadoop102:2181,hadoop103:2181,hadoop104:2181"
4)分发 solr
xsync /opt/module/solr
5)启动solr集群
(1)启动Zookeeper集群
#这是一个Zookeeper集群的启动脚本
zookeeper.sh start
(2)启动solr集群(使用xcall.sh脚本启动,这样就不用一台机器一台机器起了)
xcall.sh /opt/module/solr/bin/solr start
出现 Happy Searching! 字样表明启动成功

警告原因:solr推荐系统允许的最大进程数和最大打开文件数分别为65000和65000,而系统默认值低于推荐值。
如需修改可参考以下步骤,修改完需要重启方可生效,此处可暂不修改
(a)修改打开文件数限制:
sudo vim /etc/security/limits.conf
#增加以下内容:修改打开文件数限制
* soft nofile 65000
* hard nofile 65000
(b)修改进程数限制
sudo vim /etc/security/limits.d/20-nproc.conf
#修改如下内容
* soft nproc 65000
(c)分发后,重启服务器
sudo /home/atguigu/bin/xsync /etc/security/limits.conf /etc/security/limits.d/20-nproc.conf
6)访问web页面,默认端口为8983,可指定三台节点中的任意一台IP,http://hadoop102:8983
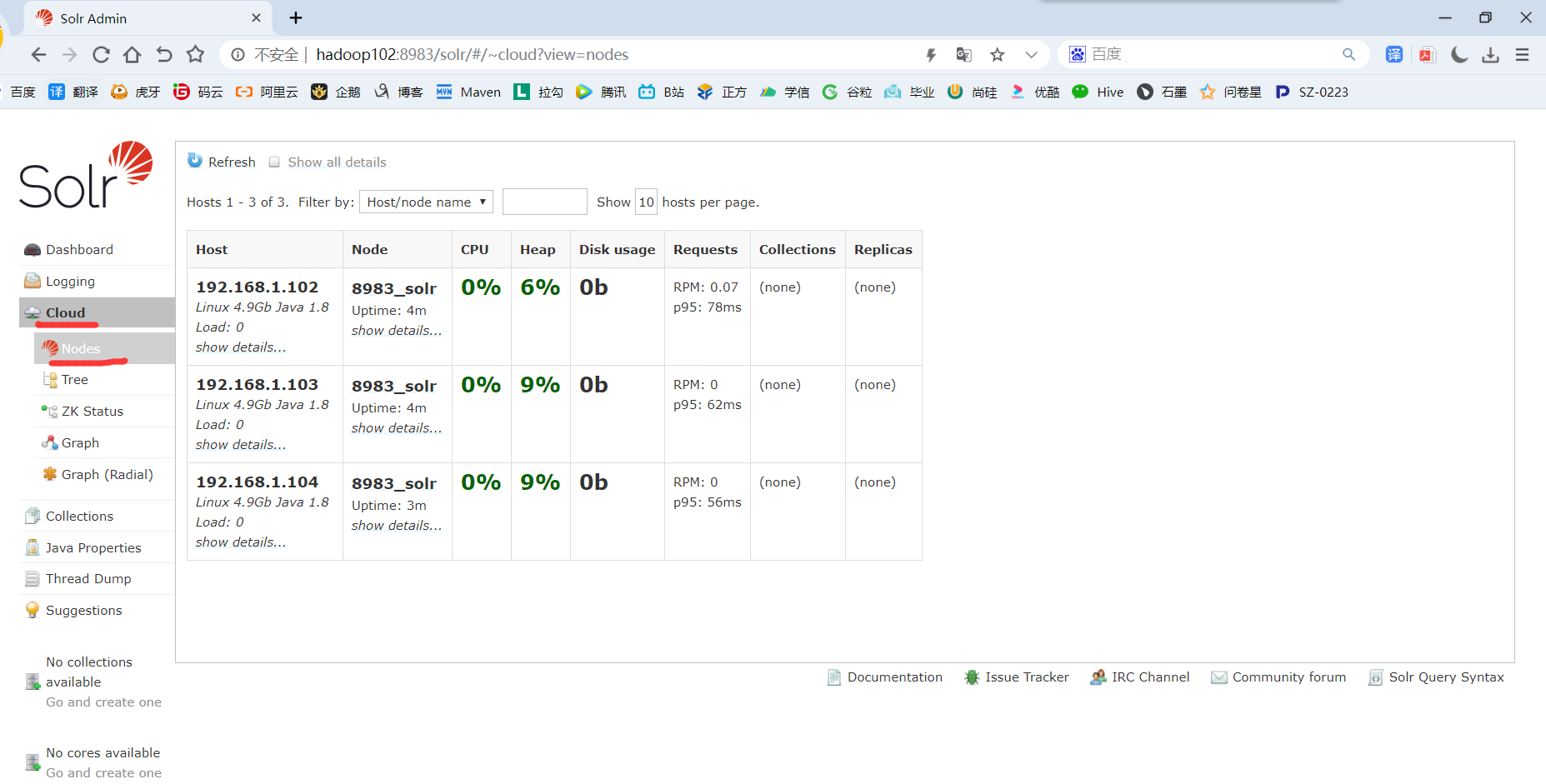
提示:UI界面出现Cloud菜单栏时,Solr的Cloud模式才算部署成功。
2.1.8 安装Atlas2.1.0
1)把 apache-atlas-2.1.0-bin.tar.gz 上传到hadoop102的/opt/software目录下
2)解压apache-atlas-2.1.0-bin.tar.gz到/opt/module/目录下面
tar -zxvf /opt/software/apache-atlas-2.1.0-bin.tar.gz -C /opt/module/
3)修改apache-atlas-2.1.0的名称为atlas
mv /opt/module/apache-atlas-2.1.0/ /opt/module/atlas
2.2 Atlas配置
2.2.1 Atlas集成Hbase
1)修改/opt/module/atlas/conf/atlas-application.properties配置文件中的以下参数:
vim /opt/module/atlas/conf/atlas-application.properties
#atlas将生成的graph(图标)存储到hbase,所以我们配置hbase的连接
atlas.graph.storage.hostname=hadoop102:2181,hadoop103:2181,hadoop104:2181
2)修改/opt/module/atlas/conf/atlas-env.sh配置文件,增加以下内容
vim /opt/module/atlas/conf/atlas-env.sh
export HBASE_CONF_DIR=/opt/module/hbase/conf
2.2.2 Atlas集成Solr
1)修改/opt/module/atlas/conf/atlas-application.properties配置文件中的以下参数:
vim /opt/module/atlas/conf/atlas-application.properties
#atlas需要将graph的index存储到solr,指定solr的Zookeeper地址,所以我们修改它
atlas.graph.index.search.solr.zookeeper-url=hadoop102:2181,hadoop103:2181,hadoop104:2181
2)分发 atlas
xsync /opt/module/atlas/
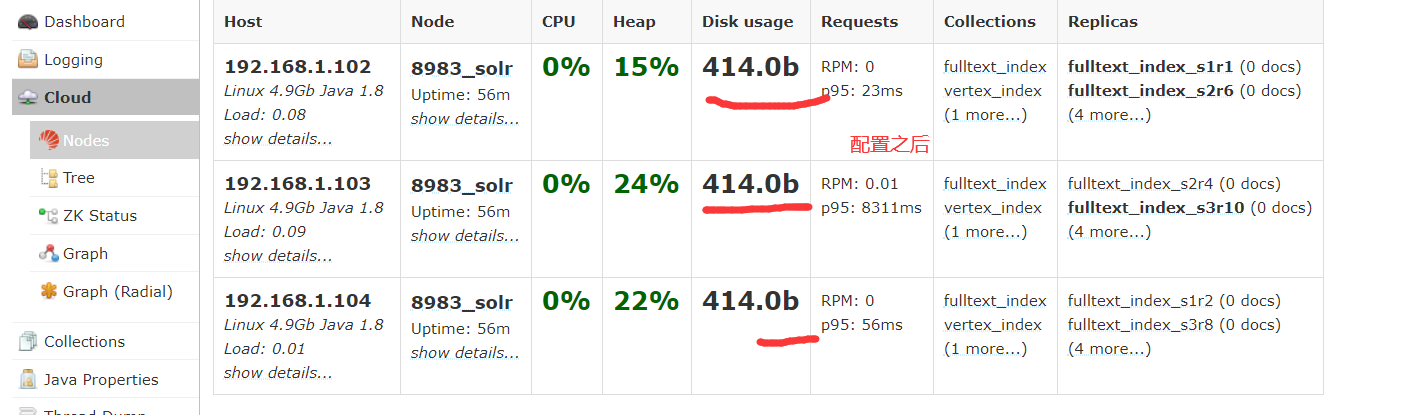
3)创建solr collection(随便找一个shell窗口依次执行即可)
/opt/module/solr/bin/solr create -c vertex_index -d /opt/module/atlas/conf/solr -shards 3 -replicationFactor 2
/opt/module/solr/bin/solr create -c edge_index -d /opt/module/atlas/conf/solr -shards 3 -replicationFactor 2
/opt/module/solr/bin/solr create -c fulltext_index -d /opt/module/atlas/conf/solr -shards 3 -replicationFactor 2
2.2.3 Atlas集成Kafka
修改/opt/module/atlas/conf/atlas-application.properties配置文件中的以下参数:
vim /opt/module/atlas/conf/atlas-application.properties
#是否开启内置的通知机制 atlas.notification.embedded=false #kafka中数据存放的目录 atlas.kafka.data=/opt/module/kafka/logs #kafka中Zookeeper的地址 atlas.kafka.zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka #kafka中集群的地址 atlas.kafka.bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092
2.2.4 Atlas Server配置
1)修改/opt/module/atlas/conf/ atlas-application.properties配置文件中的以下参数
vim /opt/module/atlas/conf/atlas-application.properties
#发送reset请求的url路径 atlas.rest.address=http://hadoop102:21000 #是否自启,把注释打开即可 atlas.server.run.setup.on.start=false #审计日志存储在hbase中,所以填写hbase的Zookeeper地址 atlas.audit.hbase.zookeeper.quorum=hadoop102:2181,hadoop103:2181,hadoop104:2181
2)记录性能指标,进入/opt/module/atlas/conf/路径,修改当前目录下的atlas-log4j.xml
cd /opt/module/atlas/conf/
vim atlas-log4j.xml
#去掉如下代码的注释 <appender name="perf_appender" class="org.apache.log4j.DailyRollingFileAppender"> <param name="file" value="${atlas.log.dir}/atlas_perf.log" /> <param name="datePattern" value="'.'yyyy-MM-dd" /> <param name="append" value="true" /> <layout class="org.apache.log4j.PatternLayout"> <param name="ConversionPattern" value="%d|%t|%m%n" /> </layout> </appender> <logger name="org.apache.atlas.perf" additivity="false"> <level value="debug" /> <appender-ref ref="perf_appender" /> </logger>
2.2.5 Atlas集成Hive
1)修改/opt/module/atlas/conf/atlas-application.properties配置文件,添加以下参数:
vim /opt/module/atlas/conf/atlas-application.properties
######### Hive Hook Configs ####### #Atlas集成Hive atlas.hook.hive.synchronous=false atlas.hook.hive.numRetries=3 atlas.hook.hive.queueSize=10000 atlas.cluster.name=primary
2)修改Hive配置文件,在/opt/module/hive/conf/hive-site.xml文件中增加以下参数,配置Hive Hook
vim /opt/module/hive/conf/hive-site.xml
<!-- 让hive在执行hql时,自动调用下方类中的钩子程序 -->
<property> <name>hive.exec.post.hooks</name> <value>org.apache.atlas.hive.hook.HiveHook</value> </property>
3)安装Hive Hook
(1)上传 apache-atlas-2.1.0-hive-hook.tar.gz 文件至 /opt/software
(2)解压Hive Hook 至 /opt/module
tar -zxvf /opt/software/apache-atlas-2.1.0-hive-hook.tar.gz -C /opt/module/
(3)将Hive Hook依赖复制到Atlas安装路径
cp -r /opt/module/apache-atlas-hive-hook-2.1.0/* /opt/module/atlas/
(4)修改/opt/module/hive/conf/hive-env.sh配置文件
#需先需改文件名,如果之前没有修改过的话
mv /opt/module/hive/conf/hive-env.sh.template /opt/module/hive/conf/hive-env.sh
vim /opt/module/hive/conf/hive-env.sh
#增加如下参数
#hive每次启动时会自动加载lib中的jar包和auxlib中的jar包,以及我们现在配置的这个路径下的jar包
export HIVE_AUX_JARS_PATH=/opt/module/atlas/hook/hive
(5)将Atlas配置文件/opt/module/atlas/conf/atlas-application.properties 拷贝到/opt/module/hive/conf目录
cp /opt/module/atlas/conf/atlas-application.properties /opt/module/hive/conf/
2.3 Atlas启动
1)启动Atlas所依赖的环境
(1)启动Hadoop集群
hdp.sh start
(2)启动Zookeeper集群
zookeeper.sh start
(3)启动Kafka集群
kafka.sh start
(4)启动Hbase集群,在HMaster节点执行以下命令,所以我在hadoop102上执行
start-hbase.sh
(5)启动Solr集群
xcall.sh /opt/module/solr/bin/solr start
(6)启动Atlas服务(hadoop102上启动)
/opt/module/atlas/bin/atlas_start.py

(a)错误信息查看路径:/opt/module/atlas/logs/*.out和application.log
(b)停止Atlas服务命令为
/opt/module/atlas/bin/atlas_stop.py
2)访问Atlas的WebUI(等待时间大概5分钟)
访问地址:http://hadoop102:21000 账户:admin 密码:admin
第3章 Atlas使用
Atlas的使用相对简单,其主要工作是同步各服务(主要是Hive)的元数据,并构建元数据实体之间的关联关系,然后对所存储的元数据建立索引,最终未用户提供数据血缘查看及元数据检索等功能
Atlas在安装之初,需手动执行一次元数据的全量导入,后续Atlas便会利用Hive Hook增量同步Hive的元数据。
3.1 Hive元数据初次导入
Atlas提供了一个Hive元数据导入的脚本,直接执行该脚本,即可完成Hive元数据的初次全量导入
1)导入Hive元数据
#执行以下命令
/opt/module/atlas/hook-bin/import-hive.sh
按提示输入用户名:admin;输入密码:admin
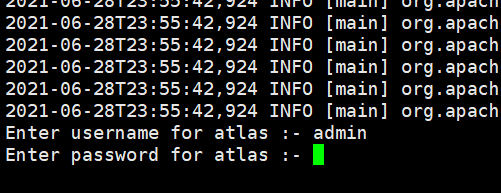
等待片刻,出现以下日志,即表明导入成功

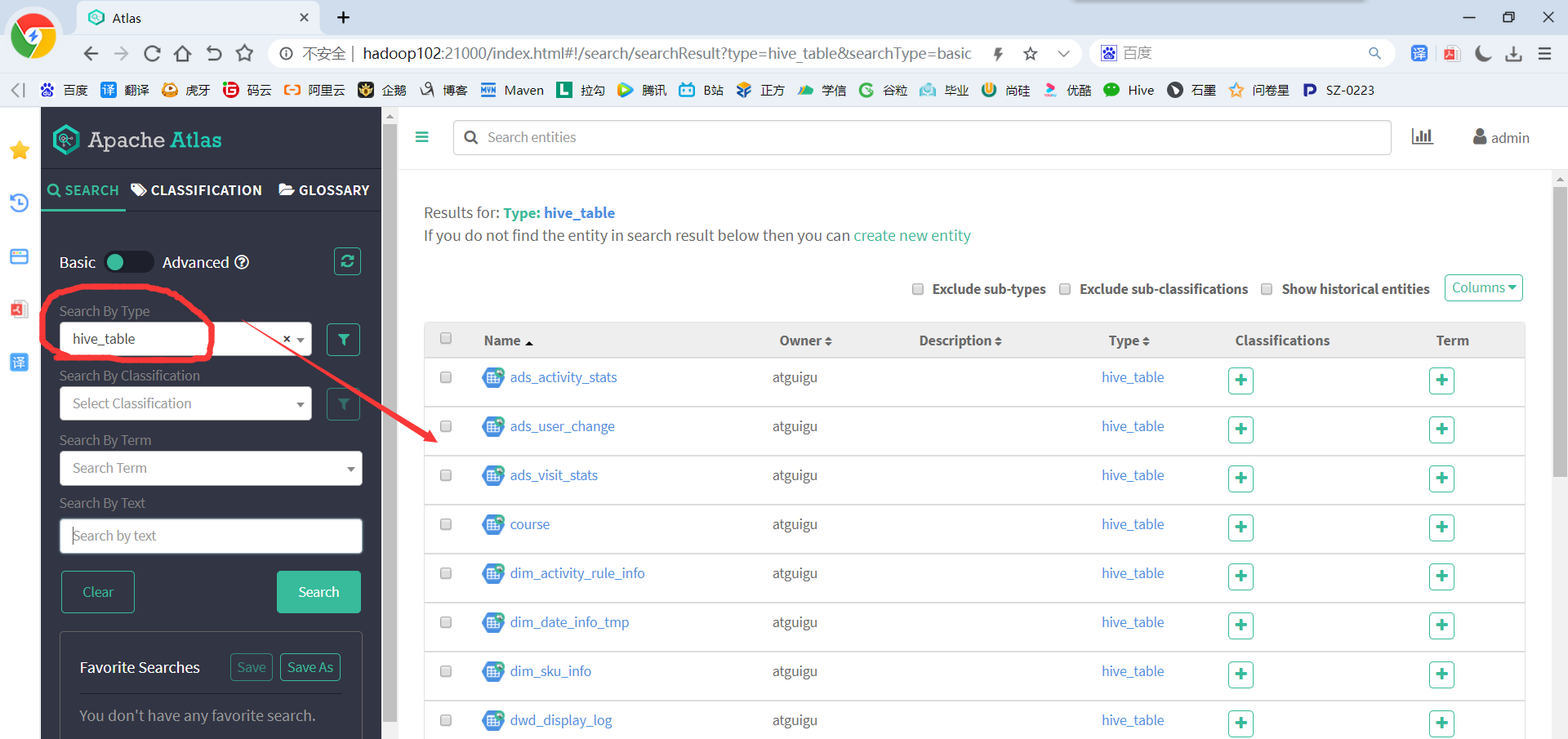
2)查看Hive元数据
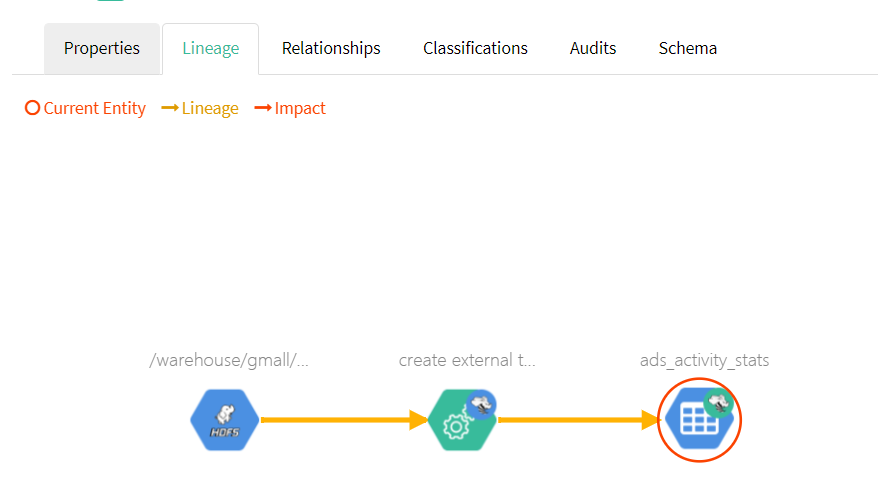
(1)搜索hive_table类型的元数据,可已看到Atlas已经拿到了Hive元数据
(2)任选一张表查看血缘依赖关系,发现此时并未出现期望的血缘依赖,原因是Atlas是根据Hive所执行的SQL语句获取表与表之间以及字段与字段之间的依赖关系的,例如执行insert into table_a select * from table_b语句,Atlas就能获取table_a与table_b之间的依赖关系。此时并未执行任何SQL语句,故还不能出现血缘依赖关系。
3.2 Hive元数据增量同步
Hive元数据的增量同步,无需人为干预,只要Hive中的元数据发生变化(执行DDL语句),Hive Hook就会将元数据的变动通知Atlas。除此之外,Atlas还会根据DML语句获取数据之间的血缘关系。
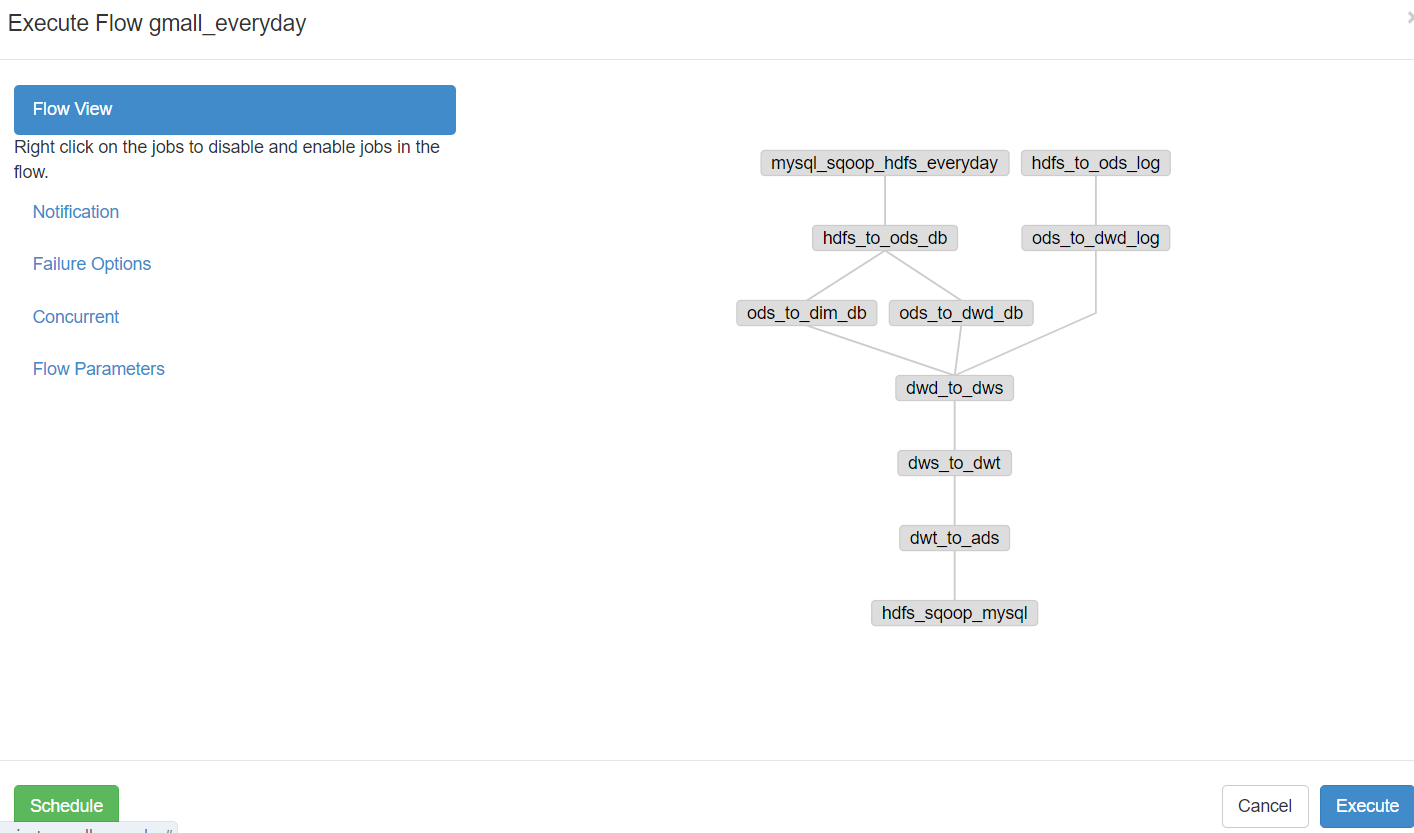
3.2.1 全流程调度
为查看血缘关系效果,此处使用Azkaban将数仓的全流程调度一次
1)新数据准备
(1)用户行为日志
(a)启动日志采集通道,包括Zookeeper,Kafka,Flume等
#第一层采集脚本:采集数据至kafka
flume-first.sh start
#第二层采集脚本:从kafka消费数据至hdfs
flume-second.sh start
(b)执行makeLogData.sh脚本,生成数据,然后等待采集脚本采集数据即可
makeLogData.sh 2021-06-11 1
(2)等待片刻,观察HDFS是否出现2021-06-11的日志文件

2)业务数据
(1)修改/opt/module/mock/application.properties,将模拟日期修改为2021-06-11,如下
vim /opt/module/mock/application.properties
#业务日期
mock.date=2021-06-11
(2)进入到/opt/module/mock路径,执行模拟生成业务数据的命令,如下:
java -jar gmall2020-mock-db-2021-01-22.jar
(3)观察mysql的gmall数据中是否出现2021-06-11的数据

3)启动Azkaban(在hadoop103上使用脚本启动)
azkaban.sh start
4)全流程调度,使用 gmall_everyday 工作流即可,详情请看:https://www.cnblogs.com/LzMingYueShanPao/p/14942069.html
4)运行结果
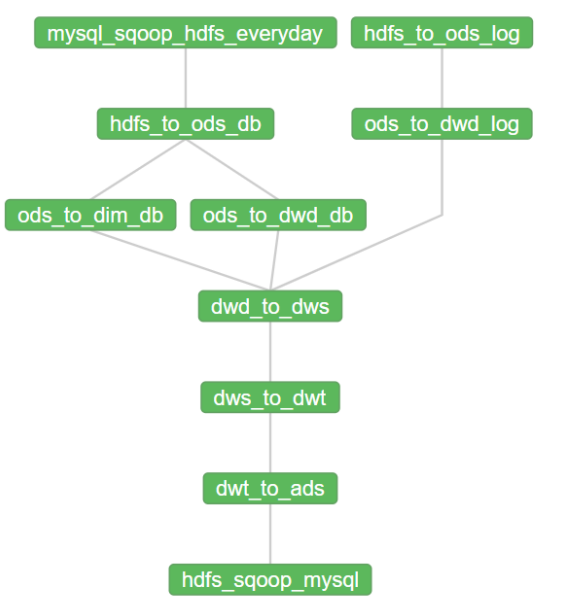
3.2.2 查看血缘依赖
此时再通过Atlas查看Hive元数据,即可发现血缘依赖

第4章 扩展内容
4.1 Atlas源码编译
4.1.1 安装Maven
1)Maven下载:https://maven.apache.org/download.cgi
2)把apache-maven-3.6.1-bin.tar.gz上传到linux的/opt/software目录下
3)解压apache-maven-3.6.1-bin.tar.gz到/opt/module/目录下面
tar -zxvf apache-maven-3.6.1-bin.tar.gz -C /opt/module/
4)修改apache-maven-3.6.1的名称为maven
mv apache-maven-3.6.1/ maven
5)添加环境变量到/etc/profile中
vim /etc/profile
#MAVEN_HOME export MAVEN_HOME=/opt/module/maven export PATH=$PATH:$MAVEN_HOME/bin
6)测试安装结果
source /etc/profile
mvn -v
7)修改setting.xml,指定为阿里云
cd /opt/module/maven/conf/
vim settings.xml
<!-- 添加阿里云镜像--> <mirror> <id>nexus-aliyun</id> <mirrorOf>central</mirrorOf> <name>Nexus aliyun</name> <url>http://maven.aliyun.com/nexus/content/groups/public</url> </mirror> <mirror> <id>UK</id> <name>UK Central</name> <url>http://uk.maven.org/maven2</url> <mirrorOf>central</mirrorOf> </mirror> <mirror> <id>repo1</id> <mirrorOf>central</mirrorOf> <name>Human Readable Name for this Mirror.</name> <url>http://repo1.maven.org/maven2/</url> </mirror> <mirror> <id>repo2</id> <mirrorOf>central</mirrorOf> <name>Human Readable Name for this Mirror.</name> <url>http://repo2.maven.org/maven2/</url> </mirror>
4.1.2 编译Atlas源码
1)把apache-atlas-2.1.0-sources.tar.gz上传到hadoop102的/opt/software目录下
2)解压apache-atlas-2.1.0-sources.tar.gz到/opt/module/目录下面
tar -zxvf apache-atlas-2.1.0-sources.tar.gz -C /opt/module/
3)下载Atlas依赖
export MAVEN_OPTS="-Xms2g -Xmx2g"
cd /opt/module/apache-atlas-sources-2.1.0/
mvn clean -DskipTests install
mvn clean -DskipTests package -Pdis
#一定要在${atlas_home}执行
cd distro/target/
mv apache-atlas-2.1.0-server.tar.gz /opt/software/
mv apache-atlas-2.1.0-hive-hook.tar.gz /opt/software/
提示:执行过程比较长,会下载很多依赖,大约需要半个小时,期间如果报错很有可能是因为TimeOut造成的网络中断,重试即可。
4.2 Atlas内存配置
如果计划存储数万个元数据对象,建议调整参数值获得最佳的JVM GC性能。以下是常见的服务器端选项,我们修改配置文件/opt/module/atlas/conf/atlas-env.sh
vim /opt/module/atlas/conf/atlas-env.sh
#设置Atlas内存
export ATLAS_SERVER_OPTS="-server -XX:SoftRefLRUPolicyMSPerMB=0 -XX:+CMSClassUnloadingEnabled -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+PrintTenuringDistribution -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=dumps/atlas_server.hprof -Xloggc:logs/gc-worker.log -verbose:gc -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=1m -XX:+PrintGCDetails -XX:+PrintHeapAtGC -XX:+PrintGCTimeStamps"
#建议JDK1.7使用以下配置
export ATLAS_SERVER_HEAP="-Xms15360m -Xmx15360m -XX:MaxNewSize=3072m -XX:PermSize=100M -XX:MaxPermSize=512m"
#建议JDK1.8使用以下配置
export ATLAS_SERVER_HEAP="-Xms15360m -Xmx15360m -XX:MaxNewSize=5120m -XX:MetaspaceSize=100M -XX:MaxMetaspaceSize=512m"
#如果是Mac OS用户需要配置
export ATLAS_SERVER_OPTS="-Djava.awt.headless=true -Djava.security.krb5.realm= -Djava.security.krb5.kdc="
参数说明: -XX:SoftRefLRUPolicyMSPerMB 此参数对管理具有许多并发用户的查询繁重工作负载的GC性能特别有用。
4.3 配置用户名密码
Atlas支持以下身份验证方法:File、Kerberos协议、LDAP协议,通过修改配置文件atlas-application.properties文件开启或关闭三种验证方法
atlas.authentication.method.kerberos=true|false atlas.authentication.method.ldap=true|false atlas.authentication.method.file=true|false
如果两个或多个身份证验证方法设置为true,如果较早的方法失败,则身份验证将回退到后一种方法。例如,如果Kerberos身份验证设置为true并且ldap身份验证也设置为true,那么,如果对于没有kerberos principal和keytab的请求,LDAP身份验证将作为后备方案。
本文主要讲解采用文件方式修改用户名和密码设置。其他方式可以参见官网配置即可
1)打开/opt/module/atlas/conf/users-credentials.properties文件
vim /opt/module/atlas/conf/users-credentials.properties
#username=group::sha256-password admin=ADMIN::8c6976e5b5410415bde908bd4dee15dfb167a9c873fc4bb8a81f6f2ab448a918 rangertagsync=RANGER_TAG_SYNC::e3f67240f5117d1753c940dae9eea772d36ed5fe9bd9c94a300e40413f1afb9d
(1)admin是用户名称
(2)8c6976e5b5410415bde908bd4dee15dfb167a9c873fc4bb8a81f6f2ab448a918是采用sha256加密的密码,默认密码为admin。
2)例如:修改用户名称为atguigu,密码为atguigu
(1)获取sha256加密的atguigu密码
echo -n "atguigu"|sha256sum
2628be627712c3555d65e0e5f9101dbdd403626e6646b72fdf728a20c5261dc2
(2)修改用户名和密码
vim /opt/module/atlas/conf/users-credentials.properties
#username=group::sha256-password atguigu=ADMIN::2628be627712c3555d65e0e5f9101dbdd403626e6646b72fdf728a20c5261dc2 rangertagsync=RANGER_TAG_SYNC::e3f67240f5117d1753c940dae9eea772d36ed5fe9bd9c94a300e40413f1afb9d