一、Logistic回归
Logistic回归(Logistic Regression,简称LR)是一种常用的处理二类分类问题的模型。
在二类分类问题中,把因变量y可能属于的两个类分别称为负类和正类,则因变量y∈{0, 1},其中0表示负类,1表示正类。线性回归![]() 的输出值在负无穷到正无穷的范围上,不太好解决这个问题。于是我们引入非线性变换,把线性回归的输出值压缩到(0, 1)之间,那就成了Logistic回归
的输出值在负无穷到正无穷的范围上,不太好解决这个问题。于是我们引入非线性变换,把线性回归的输出值压缩到(0, 1)之间,那就成了Logistic回归![]() ,使得
,使得![]() ≥0.5时,预测y=1,而当
≥0.5时,预测y=1,而当![]() <0.5时,预测y=0。Logistic回归的名字中尽管带有回归二字,可是它是实打实的分类算法。
<0.5时,预测y=0。Logistic回归的名字中尽管带有回归二字,可是它是实打实的分类算法。
线性回归和Logistic回归的形状如下图所示:
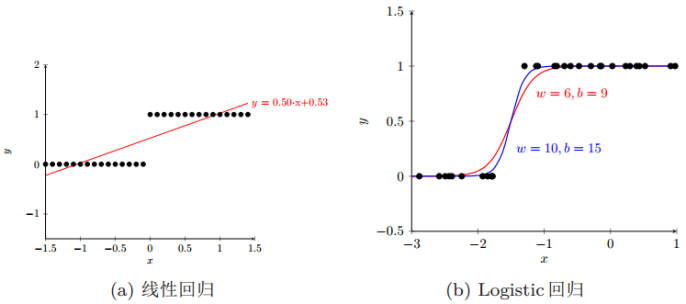
那用什么非线性变换把线性回归转化成Logistic回归呢?
1、Logistic回归的函数形式:
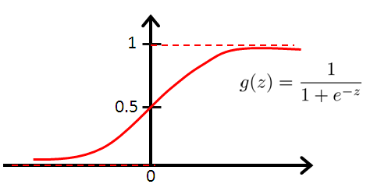
Logistic回归模型的函数形式为:![]() ,其中x代表样本的特征向量,g(z)代表sigmoid函数,公式为
,其中x代表样本的特征向量,g(z)代表sigmoid函数,公式为![]() 。下图为sigmoid函数的图形。
。下图为sigmoid函数的图形。
所以Logistic回归模型就是:

![]() 的作用是,对于给定的输入变量,根据选择的参数确定输出变量y=1的概率,即后验概率
的作用是,对于给定的输入变量,根据选择的参数确定输出变量y=1的概率,即后验概率![]() ,
,![]() 的取值范围是(0, 1)。
的取值范围是(0, 1)。
那么怎么根据![]() 的输出值来预测样本的类别呢?按照下面的规则:
的输出值来预测样本的类别呢?按照下面的规则:
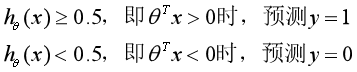
2、Logistic回归的损失函数
Logistic回归中的参数是θ,怎么估计这个参数呢?那么就要定义损失函数,通过最小化损失函数来求解参数。
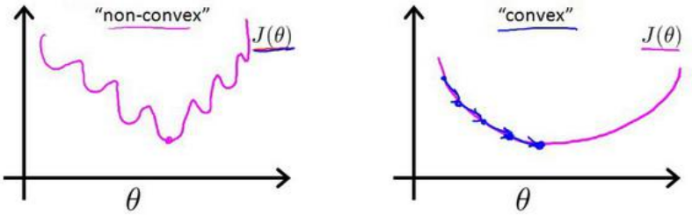
线性回归中的损失函数是平方误差损失函数,如果Logistic回归也采用这种损失函数形式,那么得到的损失函数将是一个非凸函数。这意味着损失函数会有很多局部极小值,因此不容易找到全局最小值。比如左边这个就是非凸函数的形状,明显右边这个平滑的图不容易陷入局部极小值陷阱。
假设训练数据集为{(x1,y1),(x2,y2),...(xm, ym)},即有m个样本,令x=[x0, x1, ..., xn]T,x0=1,即每个样本有n个特征,y∈{0, 1}。于是把Logistic回归的损失函数定义为对数损失函数:
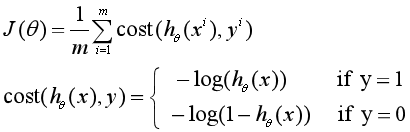
这个对数损失函数的特点是:当类别y=1时,损失随着![]() 的减小而增大,
的减小而增大,![]() 为1时,损失为0;当类别y=0时,损失随着的增大而增大,
为1时,损失为0;当类别y=0时,损失随着的增大而增大,![]() 为0时,损失为0。
为0时,损失为0。![]() 与损失
与损失![]() 的关系如下图:
的关系如下图:
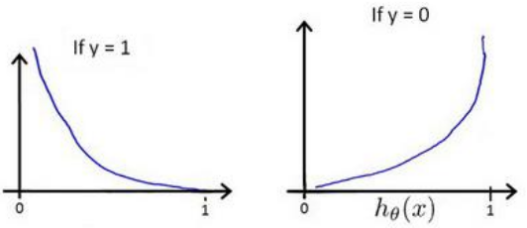
可以把损失 整理为以下的形式:
整理为以下的形式:
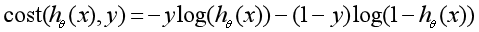
于是损失函数就成了:
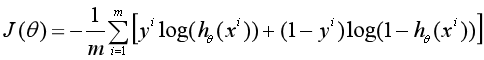
这个损失函数叫做对数似然损失函数,也有个很好听的名字:交叉熵损失函数(cross entropy loss)。这个损失函数是个凸函数,因此可以用梯度下降法求得使损失函数最小的参数。
3、Logistic回归的梯度下降法
得到了交叉熵损失函数后,可以用梯度下降法来求得使代价函数最小的参数,也就是按下面这个公式更新每个参数θj:

这个公式怎么推导的呢?如下是详细的推导过程。
已知:
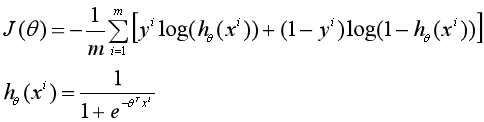
首先:
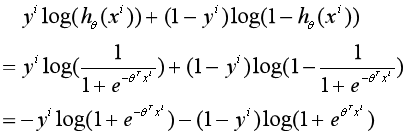
把上式代入损失函数中,并对θj求偏导:

这个推导比较长,但是推导的结果非常简洁漂亮。
将这个偏导数乘以学习了 ,得到了用梯度来更新参数
,得到了用梯度来更新参数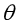 的公式,再用下面这个公式来同时更新所有的参数值,使损失函数最小化,直到模型收敛。
的公式,再用下面这个公式来同时更新所有的参数值,使损失函数最小化,直到模型收敛。
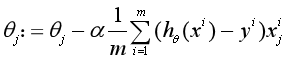
4、Logistic回归防止过拟合
在损失函数中加入参数θj的L2范数,限制θj的大小,以解决过拟合问题,那么加入正则化项的损失函数为:
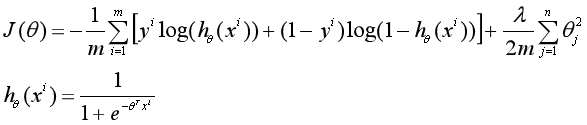
相应的,此时的梯度下降算法为:
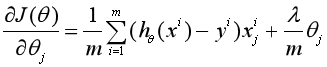
重复以下步骤直至收敛:
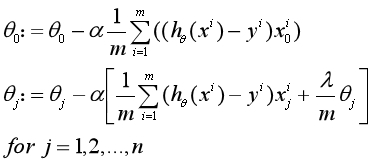
二、softmax回归
Logistic回归是用来解决二类分类问题的,如果要解决的问题是多分类问题呢?那就要用到softmax回归了,它是Logistic回归在多分类问题上的推广。此处神经网络模型开始乱入,softmax回归一般用于神经网络的输出层,此时输出层叫做softmax层。
1、softmax函数
首先介绍一下softmax函数,这个函数可以将一个向量(x1,x2,...,xK)映射为一个概率分布(z1,z2,...,zK):
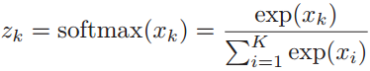
那么在多分类问题中,假设类别标签y∈{1, 2, ..., C}有C个取值,那么给定一个样本x,softmax回归预测x属于类别c的后验概率为:
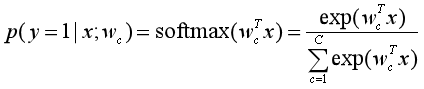
其中wc是第c类的权重向量。
那么样本x属于C个类别中每一个类别的概率用向量形式就可以写为:
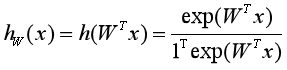
其中W=[w1,w2,...,wC]是由C个类的权重向量组成的矩阵,1表示元素全为1的向量,得到![]() 是由所有类别的后验概率组成的向量,第c个元素就是预测为第c类的概率,比如[0.05, 0.01, 0.9, 0.02, 0.02],预测为第3类。
是由所有类别的后验概率组成的向量,第c个元素就是预测为第c类的概率,比如[0.05, 0.01, 0.9, 0.02, 0.02],预测为第3类。
2、softmax回归的损失函数和梯度下降
假设训练数据集为{(x1,y1),(x2,y2),...(xM, yM)},即有M个样本,softmax回归使用交叉熵损失函数来学习最优的参数矩阵W,对样本进行分类。
由于涉及到多分类,所以损失函数的表示方法稍微复杂一些。我们用C维的one-hot向量y来表示类别标签。对于类别c,其向量表示为:
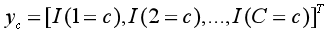
其中![]() 表示指示函数。
表示指示函数。
则softmax回归的交叉熵损失函数为:
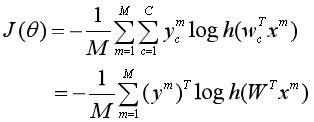
其中![]() 表示样本
表示样本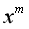 预测为每个类别的后验概率组成的向量。
预测为每个类别的后验概率组成的向量。
上面这个式子不太好理解,我们单独拿出一个样本来观察。假设类别有三类,预测一个样本x属于第2类的交叉熵损失为![]() ,其中
,其中![]() ,如果预测正确,如
,如果预测正确,如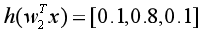 ,则交叉熵损失为
,则交叉熵损失为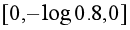 ,而如果预测错误,如
,而如果预测错误,如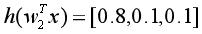 ,则交叉熵损失为
,则交叉熵损失为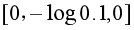 ,可见预测错误时损失非常大。
,可见预测错误时损失非常大。
同样的,用梯度下降法对损失函数进行优化求解,首先得到损失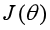 对参数向量W的梯度:
对参数向量W的梯度:
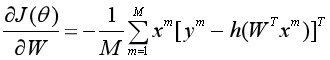
初始化W0=0,然后对所有参数WC进行迭代更新,直至收敛。

三、总结
Logistic回归这个可爱的模型,相比SVM、GBDT等模型,要简单得多,但是由于这个模型可解释性强,被广泛运用于各种业务场景中。此外,它也是如今大行其道的深度学习算法的基础之一。
逻辑回归的优点有以下几点:
1、模型的可解释性比较好,从特征的权重可以看到每个特征对结果的影响程度。
2、输出结果是样本属于类别的概率,方便根据需要调整阈值。
3、训练速度快,资源占用少。
而缺点是:
1、准确率并不是很高。因为形式非常简单(非常类似线性模型),很难去拟合数据的真实分布。
2、处理非线性数据较麻烦。逻辑回归在不引入其他方法的情况下,只能处理线性可分的数据。
3、很难处理数据不平衡的问题。
吴恩达老师说,学完了Logistic回归,就有了丰富的机器学习知识,目测比那些硅谷工程师还厉害。所以有公司要我吗?坐等。
参考资料:
1、吴恩达:《机器学习》
2、邱锡鹏:《神经网络与深度学习》
3、 https://blog.csdn.net/u010867294/article/details/79138603