前言
欢迎来到传说已久的史诗级副本——OO,目前距离ddl还有一天,您目前未完成的任务是:从零开始的JAVA求生路,某不科学的指导书翻译之旅,以及code-debug-code命运bug门。没错,这就是我面向对象课程第一次作业ddl前一天的真实写照。在这样的窘迫状况下,我连忙抄起一本博客,打开Eclipse,瞄着越来越近的ddl,开始一日速成面向对象。
什么?没有函数,哎我感觉这什么类的方法跟函数一样哎,不管了就当函数用。没有scanf ??那cin呢??哇什么都没有我拿什么写代码,Scanner?这个类的说明看不太明白啊,范围限制在哪找不到啊,算了凑合使吧。哎这个方法怎么一百来行了,好像也没有规定不能写这么长吧,不管了完成任务先。历经千辛万苦写了个输入控制,状态机的图画了慢慢一页A4纸,哎哎哎隔壁老王好像用了正什么则表达式,一行就解决问题,赶紧赶紧谷歌百度齐上手,照猫画虎来一通先。我感觉自己仿佛在搬砖,还搬的是一小块一小块的碎砖,堆不起来就拿点水泥糊起来,东边的砖厂说这办法好使,西边的工头说那套路好用。终于,在手工添加30多条print,进行了一下午的debug之后,我的第一个java程序就诞生了。
我方伤亡情况
第一次作业,公测加互测一共被炸了三个BUG……
(1)指导书理解错误,由于是赶工作品,指导书仅仅粗略扫了一遍,“输入不允许相同指数”这一点就被我毫不留情的忽略了,我还特意做了相同指数的特殊处理,结果直接判为无效输入就好。。。此时真切感受到需求才是一切开发的源头。这段时间以来很多人都在诟病指导书,老实说一些语言的表述确实存在问题,但是我觉得核心点并不在于此。老师的初衷是希望大家自己去分析需求,感受实际工程开发可能遇到的各种千奇百怪的需求(为以后与产品经理互怼提供经验),但是指导书的表意不明问题确实存在,正像某位同学说的“写那么多字不如来个样例多清楚明了”,但老师认为有了样例就和算法题模式一样了,达不到课程设计的目的。我个人觉得,现实中需求的麻烦之处主要在于两点,一是需求者的表述和开发者的所需的输入相差太大,很难完成从实际问题到代码工程的建模,这一点我觉得通过也是指导书的主要训练目的,但由于语言叙述的问题,以及助教和论坛答疑无法模拟真实中需求双方的交流,所以目前会让我们感觉很痛苦。二是需求的多变,从而考验软件的可扩展性之类之类的,而这一点我在本次课程中感受到的很少,回顾我自己写过的代码,如果突然加入一些特殊的条件,我想是会给我带来很大的困难的,因为最初设计还是带有一些面向过程的思想,很多方法的数据处理能力很局限。不过在理论课上听到老师提到了这一点,但确实在作业中没有面对改需求的挑战确实有点遗憾。此外,我看到很多同学在阅读指导书时采用自己新开一个文档提炼关键字句的方法,这是很好的做法,如果在分析指导书的同时伴随着测试样例的构造,我觉得就是完美的设计准备了。
(2)某个方法的使用没有考虑周全,导致在边界条件下出了问题,我想这个主要还是语言熟练度的问题。。。毕竟一天速成的代价。
(3)代码中有一处逻辑错误,这个锅就得自己来背了,鉴于第一次作业逻辑之简单我就直接脑中构思然后开始实现了,不过还是出了纰漏。我想这就是工程能力的不足吧。回想起上学期的计组,课程的核心难度并不大,问题其实主要在于50条+指令集和各种各样的异常处理,问题或者工程的复杂度一大,仅凭脑中思考远远不够了,这时候就很需要将脑中想法具象化,通过纸笔,文档或者表格将整个思路记述下来,这种实体存在的东西将会使我们的整个开发过程更可靠。
第二次作业,不好意思一个BUG都没有,心疼一秒测我作业的同学。
第三次作业,又中了三箭……
emmmm这次我又又又犯懒了,又是个一天速成计划。不过相对于之前,我对于java和OOP的理解已经有所提高,但由于时间分配的问题导致在ddl之前留了尾巴。
(1)由于这次连readme都没交上去。。。所以很无奈的被测试者自定义了一波,这确实是自己懒的结果。
(2)我的测试脚本运用能力其实挺差的……所以我都是基本从设计角度尽力去完备,而所使用的测试数据集并不大,这导致我的作业非常依赖最初的构思。而本次作业指导书中确实有些笼统,而我又没有及时查看答疑,导致我在距离ddl前两小时才发现任何同时输出都必须按照输入顺序,就算是已经晋升为主请求也不能例外。于是乎,手忙脚乱的我开始临时修改,这自然就暴露出我代码可扩展性的严重问题了,牵一发而动全身,几个方法的耦合度太高,最终使得在ddl之前我没有解决最后的bug。最终的提交版本中我的command方法是这样的:
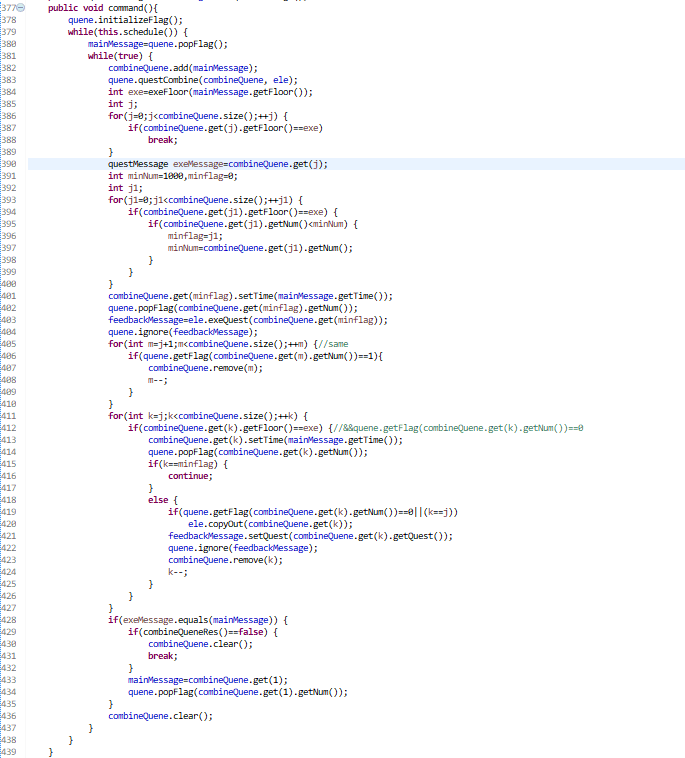
很明显可以看到我使用了很多临时变量和临时添加的分支循环,一个补丁打上去,新的bug又冒出来。。。最终便倒在了ddl之前。
当晚我重构了这部分代码之后,心情立马就好多了,终于消灭这块长长的裹脚布了……
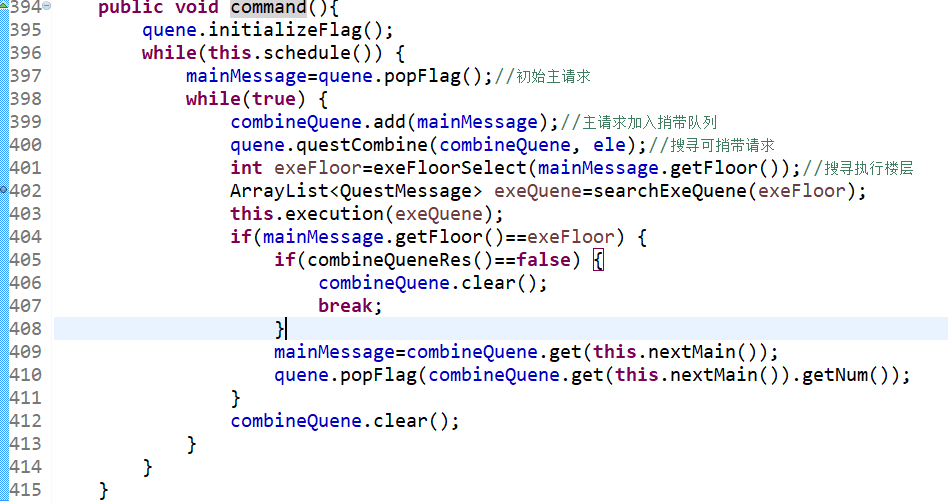
需求清楚是第一!!!时间线绝对要有富余!!!设计思路一定要具象化!!!方法内部一定要及时封装!!!好好学测试脚本技术!!!
(3)第三个bug就是就是一种编程的习惯问题了,我们经常会将常量通过宏定义(C语言),static final修饰(java)等方式在程序的开头就进行规范,以便于之后修改,但是我自己却忽略了对于某一块功能代码的整合封装,请看下图:


这是输入处理中对于初始条件的判断,你会好奇我干嘛贴出来两处,这是因为电梯作业中我是对FR楼层请求,ER电梯请求的输入分开进行处理,这是两部分各自的初始条件判断。两者的具体在哪里?对就是一个是简单的time不等于0一个是封装成一个初始状态判断函数。。。相信聪明的读者一定想到了,第二次作业时的判断条件似乎time!=0,而第三次作业是对整句输入都有要求,于是乎,我改了上面忘了下面。。。最终导致了BUG的产生。其实在最初设计的时候,time!=0这种写法我相信很多人都会这样做,方便又省事,但是当需求变了,当你在程序中有多处这样相同功能的代码,你能全部记起来一一进行修改吗。。。这怕是很难百分百做到的,而如果在最初设计的时候就封装成initJudge函数,以后再怎么修改也很容易。
深不可测的内伤
没有BUG你的程序就是完美的了?太年轻了。。。当我兴致勃勃的把自己的代码拿给某位大佬看时,我才知道自己好多地方简直反工程。。。尤其在安装IDEA打开自己的代码之后,我又一次觉得自己的工程能力还差个十万八千里……整个文件全在一个java文件里。。。浩浩荡荡五百多行(怪不得我鼠标滚轮使用量巨高)。然后各种不规范的命名,驼峰姓名法,大小写,英语和拼音,下划线……你能想到的命名方法我都有。命名的重要性相信不用我多说,如果拿自然语言来说,你觉得一篇中英俄法德混用,还偶尔有个火星文的文章你看着能好受吗,更别说拿给别人看了。
通过IDEA的语法检查,我发现了很多细小的warning,结合这些对于代码做修改会使整个代码内容更加规范化。例如:
(1)某些属性和方法可以使用更低级的访问权限,有利于数据的保护(能private的绝不public)。
(2)对于一些常量或者是枚举类型,最好使用final修饰保证不会被误修改。偶同事还可以单独建一个类将这些全局都会使用的内容统一放进去以便管理,当然跟某一个类密切相关的仍然放在其中即可。
(3)无用的变量或者无用的方法定义,在代码实现中我们时常会有一些临时的想法,但后来在最终的实现中又被遗忘了,这些冗余可以通过IDEA筛选出来很方便的清除。
(4)对于数组或者是集合的遍历,可以使用foreach语法来代替for循环,更为简洁强大。
(5)数组的copy不用傻傻的写循环了,可以使用更高性能的的System.arraycopy()方法。
(6)在对象初始化时的一些多余的初始化行为,也建议清除。
(7)正则表达式很多人使用的还很生硬,需要一些高级操作,比如使用?来简化[0,1]等等类似的操作。
(8)一些不必要的成员变量可以缩小作用域,变为局部变量。
当然每个人的代码中可能还有自己的细节问题,在这里再安利一波IDEA,希望大家不要忽视这些细节。
量化分析
量化的数据结果更能说明代码的质量,这里我使用IDEA对于我的第三次作业进行分析:
例如:long method,指除注释内容外代码长度较长的方法,这是重构代码时需要关心的问题之一,我的代码中出现了两处(我刚刚重构好的command还是长)。

其他的问题,method with too many parameters, 'if' statement has too many branches, redundant local variable and so on就等着大家去一一探索啦。
当然,我们还可以使用metrics对代码复杂度进行分析,在这里我使用了chidamber-kemerer metrics,一种面向对象代码评价标准进行评价,得到的结果如下:

其中CBO是指Coupling between objects,即类之间的耦合度,对一个类调用另一个类的方法或变量进行计数,该值应该是越低越好,可以看出我的代码类之间的耦合度还是较高的。其他的属性大家可以参阅http://www.virtualmachinery.com/sidebar3.htm,从而对自己的代码进一步分析。
当然还有其他角度的分析,如complexity metrics:

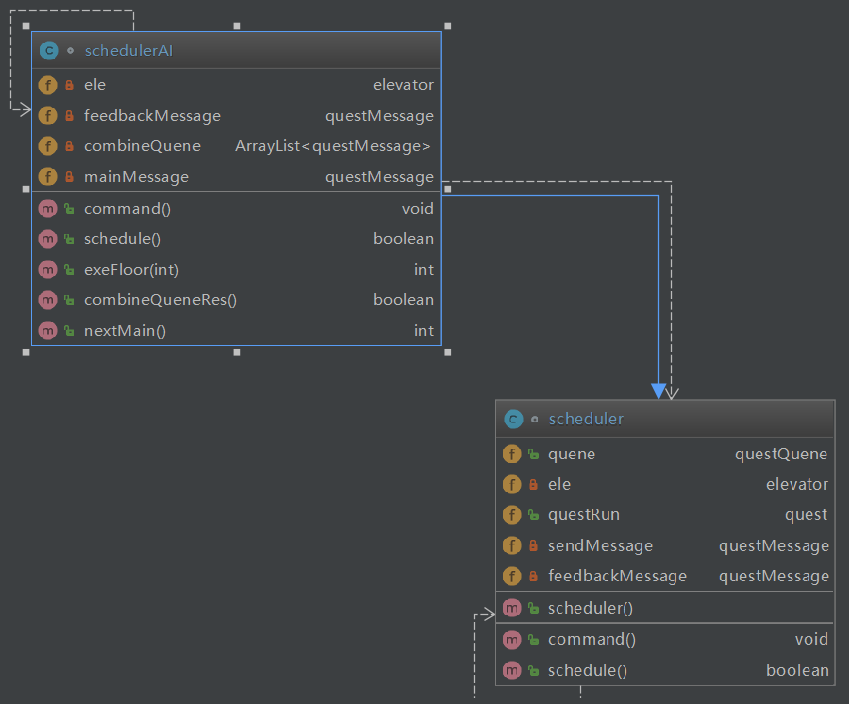
OCavg是平均操作复杂度,可以看到代码quest类和schedulerAI类还是十分臃肿。。。有待进一步优化。从类图角度也能很清楚的发现该问题。
互测大厮杀
OO课最被众人吐槽的一点,便是互测制度了。这个本意是鼓励双方互相找bug从而提高代码质量的制度却总会出现问题。这也是我博客的题目之含义。在最初我们很多人所写的都是伪面向对象,实面向过程程序。我第一次互测时抽到的第一份代码就是这样,全局一个类,一口气一百多行,就俩方法,我反正公测AC了你能拿我怎么着。但是在后面几次作业中,我拿到的程序也慢慢有了改观,有了一些OOP的感觉,但还是有一个方法写了100行+的情况出现。我想还是得更加主动的去拥抱课程,拥抱规则,尝试多了练习多了慢慢就有灵感。
那这个面向人品又从何说起呢?首先,第一次作业由于个人信息问题很快进行了重新分配,不好意思我抽到了大礼包(即空作业,无任何文件),自然轻松愉快的免去了互测任务。而之后的几次作业,个人信息问题成了大家争论的焦点,不小心在文档中夹杂了个人信息,运气好了测试者会放过你,运气不好就被申请无效作业,一周的辛苦全都白费。人品好了像我一样捡到大礼包,人品不好自己成为大礼包。
到了后来,随着大家测试脚本技术的进步和测试数据的共享化,很多人又进入了面向数据编程时代,设计时并不去做详细的规划,写出个大概之后就开始拿大规模数据集开始测试,然后根据测试结果一点一点debug,往代码中打补丁,出现一个bug就新开一个if分支,然后进行相关的处理,整个数据集跑下来,无数个分支和循环,简直是所谓面向if编程,这样的代码虽说也能完成设计要求,但代码质量和可读性是极差的。那么到了测试阶段,由于代码可读性之差,导致很多人无法或者不愿意去阅读对方代码,而是又一次通过数据集进行测试,一组数据对应一个BUG。事实上,很多不同的测试样例错误是由于同一处代码错误导致的,一些关键位置的错误,如果测试者恶意构造的话,是可以构造足够多的样例挂满整个分支树的,这样的恶性循环我相信是所有人都不愿意看到的。
我的后两次互测,拿到的程序还算较好,代码错误暂且不论整体还是比较清晰的,认真去读是可以搞清楚整个逻辑的。我每次测试会先看整体设计的outline,了解大概结构后通过几组简单数据进行初步测试,以单步调试+打印输出的方式运行,如果找到代码中错误的点并给予注释标记,通过几个简单的样例去读对方的代码,找出他设计逻辑的缺陷,然后构造测试样例找出BUG,以此类推重复上述操作,一处代码错误对应一处互测错误。暴力数据测试,咬文嚼字测试,在我看来都不是好的测试方法,当然,想要通过阅读代码辅以数据来测试是需要可读性很好的代码的,我也理解那些不愿意去阅读对方代码的同学。所以,这更要求我们在写代码的时候要注意命名,封装等等一系列的事情,只有你先写出好的可读性高的代码,才会使每次都会遇到认真负责的测试者。同样,你越多读别人代码,就越清楚什么样的代码风格是好的,什么样的是坏的,在自己写代码时也能有更良好的编程习惯和风格,而这样的良性循环我想才是这个课程的最终目的吧。
关于这门课,每个人都有不同的看法,因为每个人都站在不同的角度不同的高度,这无可厚非,但我觉得有一点是相同的,尽管每个人能从这门课中得到的东西不一样,但大家都希望从这门课获得能力的提升。而想要得到提升的基本条件,就是一个真正面向对象的编程,一个面向认真态度的编程。