1. 快速看完整部教材,列出你仍然不懂的5到10个问题,发布在你的个人博客上。
2.1.2 “单元测试必须由最熟悉代码的人(程序的作者)来写
并不认同这里这个“必须”。在我自身实习的经验中,一般都会采用开发和测试分离的模式,即大家在构思设计的时候约定好公共的接口模式,然后并行开始开发和测试程序的构建,大家公共的部分就是统一的接口,测试人员不需要知道内部的实现细节,而且根据接口来构造一系列的强覆盖逻辑,保证接口对正常功能和异常功能都能正确处理。这样做一提高了效率,二是测试不会被开发的设计思路所束缚,完全从一个外部的角度来思考,这样设计测试样例一般会更全面。
不过写到此处想到另一个问题:完全不了解内部细节,那可能会出现覆盖不到接口内部分逻辑的情况,有可能有隐藏的分支并没有覆盖到,留下了隐患。还有就是接口内部一些可能产生的副作用也不能及时发现,这的确也是存在的问题。
10.3 规格说明书
关于规格说明书我有一个一直以来的疑问,就是规格说明书-注释-代码之间的联系和配合,严格来说,他们之间有很多重复的内容,好的代码风格本身就有一定的说明作用,注释是程序员最好的助手,文档又是真正开发不可或缺的一部分,如何构建一种最合适的模式,使得每个层次都有合理的功能而有不冗余呢。
16.1.5 迷思之五: 要成为领域的专家,才能创新
在目前的环境下,仅仅成为领域的专家,似乎并不太足够了。在各行各业都高度专业化的今天,各个行业领域之间的壁垒也越来越重,很多领域的专家往往会不知不觉地局限于自己的领域,所以说,领域专家只是一个创新的必要条件。那么在现在的环境下,交叉学科似乎正在成为新兴的创新爆发点,借鉴其他学科的思路的观点,结合本领域的知识,将会产生更多的可能。深度学习中的很多优秀设计便是来源于神经科学,比如神经元的基本模型,还有生物学,比如借鉴人的视网膜细胞来组织新的卷积层,结合大脑的计算模式来构建新的高度并行化的神经网络芯片。
2.请问 “软件” 和 “软件工程” 这些词汇是如何出现的 - 何时、何地、何人?
软件: 这个词是在1958年,由John Tukey在其论文"The Teaching of Concrete Mathematics"中提出的
Tukey's 1958 paper "The Teaching of Concrete Mathematics"[10] contained the earliest known usage of the term "software"
软件工程: 这个词是在1969 年(阿波罗 11 号期间),由Margaret Hamiltion提出的
Q:你是在这段期间发明了“软件工程”一词吗?
A:软件在这个计划的初期还被当作初初学步的孩子一般对待,完全不像其他工程学科;例如像硬件工程那样的受到重视,而且在大家的眼光中他就像是艺术、魔术一般,而不是一门科学。
我一直以来坚信这项发明流着艺术与科学的血液,虽然当时很少人是这么想。因此,我致力于为软件以及那些发明者争取应有的正统性与尊重,所以我开始使用“软件工程”这样的字眼来将之与硬件还有其他工程学类做出区别。
3.大家知道了软件和软件工程的起源,请问软件工程发展的过程中有什么你觉得有趣的冷知识和故事?
- 丰田的一万多个全局变量的故事。28万行代码中有1万多个全局变量,简直就是bug培养基。
其中还有人专门做过测试。
软件设计的基本要求是模块尽量简单化,因为这样可以一来更易于阅读二来更易于维护,但丰田的工程师显然没有遵循这原则。Barr使用一种工具自动根据代码的可能分支数量评估函数的复杂度,结果是丰田的软件中至少有67条函数复杂度超过50,意味着运行这个函数可能出现超过50种不同的执行结果,属于“非可测”级别。因为为了测试这50个不同的结果,必须准备至少50条不同的测试用例以及相应的文档,在生产环境中是根本不现实的。而在这67条函数中还有12条复杂度超过100,达到“非可维护”级别,意味着一旦发现缺陷(Bug)也无法修复,因为实在太复杂,修复缺陷的过程中会产生新的缺陷。其中最复杂的一条函数有超过1300行代码,146个可能执行路径——正好用于根据各传感器数值计算节气门开关角度。
4.上网调查一下目前流行的源程序版本管理软件和项目管理软件都有哪些, 各有什么优缺点?
下表是2018年源代码托管软件的用户数和项目数,出自https://en.wikipedia.org/wiki/Comparison_of_source-code-hosting_facilities#Popularity
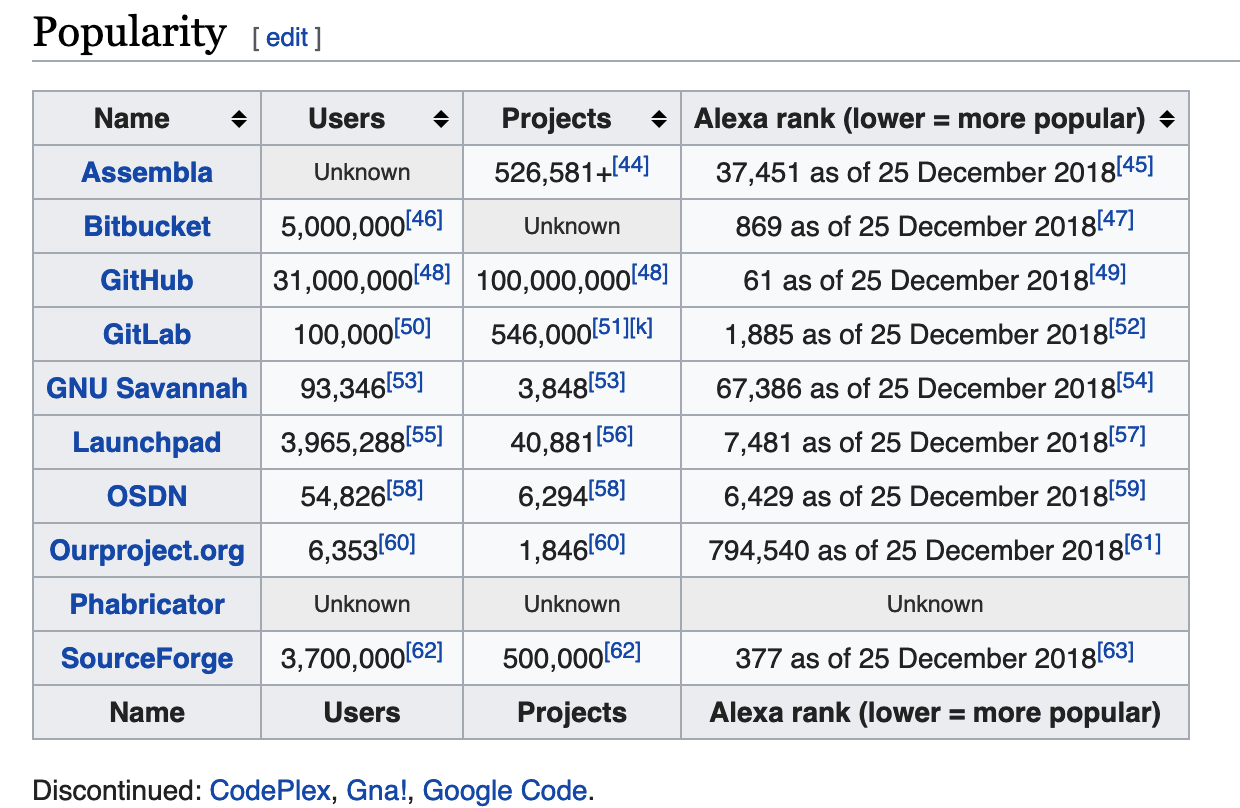
从中可以看到一般最熟悉的git(github,gitlab)还是占据了最主要的部分,下面是几大主流软件的优缺点对比。
Git
优点:
- 免费且开源。
- Git支持分支功能(branch)。如果开发一个新的产品功能,可以建立一个分支,对这个分支的进行修改,而不至于会影响到主支上的代码。或者是fork。
- 可拿Git做备份系统,或者同步多台机器的文档,很方便。
- 支持离线工作,有本地仓库和远程仓库。本地提交可以稍后提交到服务器上,不用和集中的代码管理服务器交互。 只有最终完成的版本才需要向一个中心的集中的代码管理服务器提交。
- Git 提交都是原子的,且是整个项目范围的。
- Git 中的每个工作树都包含一个具有完整项目历史的仓库,还原和版本回退非常方便。
- P.S. 推广一下自己写的git简易教程 https://github.com/OO-guide-2019/git-guide
缺点:
- 学习成本大。由浅入深的过度很漫长,需要大量时间的投入。(有合适的教程其实很快)
- Git版本库需要频繁的手动维护。
SVN
优点:
- 对目录的组织的管理更加方便。SVN不光对文件做版本跟踪,也会对目录做版本跟踪。因此可以根据项目的需要,对目录结构随时进行修改,可以把现有的目录移动到新的地方。
- 保证提交操作的完整性。SVN对提交操作的处理方式类似数据库的事务处理,要么全部成功,要么全部无效,保证了原子性。
- SVN允许一个文件有任意多的可命名属性,功能十分完全。
缺点:
- 不能离线工作。所有的版本信息都放在服务器上。如果脱离了服务器,开发者基本上可以说是无法工作的。
- 提交、更新、浏览历史的速度慢。耗费CPU资源。
- 代码不能及时提交。强迫使用者即时处理冲突,然后才能提交。
- 不能恢复到历史版本。SVN记录了单个文件的历史版本,但没有记录全局版本,不能恢复到上次的状态。这一点是很致命的。
Microsoft TFS
优点:
- 任务版上能将需求、项目进度一览无余,集成了项目管理、版本控制、BUG 跟踪。
- 能有效实现 SCRUM,能与 VS 无缝接合。
缺点:
- 搭建、维护tfs比较复杂,硬件要求也比较高。
- 整个系统是用 asp 实现的,用浏览器访问较慢。
Mercurial
优点:
- 学习门槛较低。整体上看,hg需要掌握的命令要比git少很多。
- 可以一键完全恢复到某一个历史版本。
- 封装好。相比git,hg很少暴露一些实现内的细节。
- 照顾 svn 的迁移用户。hg 的很多命令是迁移自 svn 命令的,习惯 svn 命令的团队,几乎可以零成本的切换到 hg。
- hg的版本库不需要维护。
缺点:
- 分支管理不灵活。Mercurial的branch管理和Git相比不是很方便。不适合大型团队使用。
5.关于版本控制软件的个人理解
目的:版本控制软件的目的主要是两点,版本记录控制,团队协作
从使用者角度来看,一款好的版本控制软件需要满足如下的需求:
- 简单易学易上手,这一点需要建立在软件本身指令的设计,与操作系统shell命令的结合,详细但又不啰嗦的教程,以及面向真正开发需求的实践练习。就拿git来说,很多入门者觉得痛苦的一个重要因素就是其对基本shell命令本就不太熟悉,对于命令行式开发和运维相关熟练度远远不够,而同时目前的教程更像是一部工具说明书,即以各个命令本身为基本单元,而不是git工作的整个流程,所以就会带来一种割裂感,此外,没有真正意义上的对于整个git协同开发的练习,单单看教程记忆自然不能熟练掌握(所以也就有那么多人吐槽git学起来难)
- 支持强大的版本控制操作,对个人来说,主要的需求有两点,一是不同版本路线的开发,即多个branch的开发,每个branch负责一种设计思路,二是能够方便的回退到某个版本,换句话说就是强大的存档读档功能,而对团队来说,协作就是最重要的点,以git为例,在团队开发时以fork为主,每个人的修改要想整合进来必须经过pull request,这样的机制就使得每个人可以各司其职,减少了造成冲突的可能性。就算是在一个分支中出现了merge时的冲突,git也提供了良好的冲突处理机制,更有git rebase这种高级操作,使得处理起来非常方便。
- 支持网页查看,对于阅读源代码和配置文件,不一定需要笨重地每次都clone到本地仓库一份,像github和gitlab提供的网页界面阅读代码,使得这个过程变的非常轻便。
- 对于大文件的管理,在开发大型项目的时候,我们可能会生成一些几十甚至几百MB级别以上的文件,那么像基本的github就不支持这样的大文件传输,但有的时候我们确实需要将其托管在远程仓库进行管理,这时,像git-lfs这样的工具便可以提供非常舒适的体验(强烈推荐)
从版本控制软件设计者来看,其需要考虑的因素如下:
- 对功能的封装,解耦合(抱歉我是git吹),考虑一个项目内,可能有正在编辑的文件,可能有已经编辑好的文件,可能有远程服务器上的文件,如果一视同仁,其实会非常混乱,但是像git这样的设计,工作区,暂存区,本地仓库,远程仓库,将复杂的事情解耦成为几个不同的阶段,就非常清楚。
- 面向安全的封装,对于内部的具体实现,是否暴露给用户,这一点需要考虑,暴露给用户的话可以支持更多的开发者,但是也带来了一定程度上的安全风险
- CPU等本地硬件资源的消耗和传输速度保证,比如大家都可以发现,git clone/pull/push都是使用多线程来操作的,如何利用好本地硬件资源且不带来过度的负担,也需要认真考虑
- 本地和服务器的关系,一般来说我们希望本地可以直接工作,断网时也可以本地版本控制,另一方面,服务器上也可以进行修改,不依赖本地。不过现在网络传输基本不会出现什么问题。
- 图形化界面,可能是因为基本使用命令行的缘故,所以git的GUI十分丑陋。。。
- 数据的分析和统计,在github和gitlab有很多对于项目开发情况的可视化数据统计,这对于一个团队的开发也是很棒的信息。