主流小网络包括:SqueezeNet, MobileNet(V1), 和CVPR 2018最新模型ShuffleNet, IGCV2, MobileNetV2
1、ImageNet上的top-1准确率 vs 理论计算量 vs 模型大小的对比,来自tensorflow/models,本文要探讨和分析的第一个问题:MobileNetV2到底优化了什么,能做到比MobileNetV1既好又快?
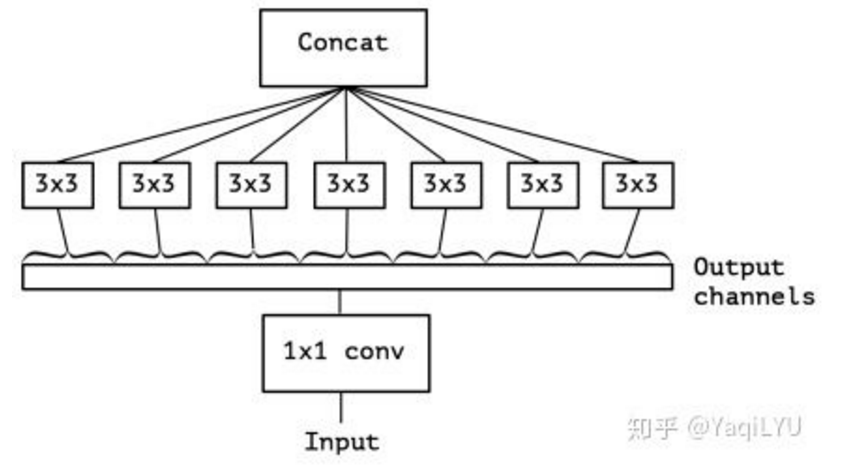
2、下图是ncnn框架的高端ARM高通820和低端ARM海思3519硬件实测速度对比,来自Tencent/ncnn,本文要探讨和分析的第二个问题:为什么理论计算很高的SqueezeNet反而非常快?为什么ShuffleNet要比架构技术接近的MobileNetV1和MobileNetV2快那么多?
SqueezeNet: DeepScale/SqueezeNet, berkeley和stanford合作论文,2016年2月挂arXiv,最新v4,ICLR 2017被拒。
-
- Iandola F N, Han S, Moskewicz M W, et al. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5 MB model size. arXiv:1602.07360, 2016.
MobileNet: tensorflow/models, Google论文,2017年4月挂arXiv,未投。
-
- Howard A G, Zhu M, Chen B, et al. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv:1704.04861, 2017.
ShuffleNet: 不开源,Face++论文,2017年7月挂arXiv最新v2,CVPR 2018论文。
-
- Zhang X, Zhou X, Lin M, et al. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices [C]// CVPR, 2018.
IGCV2: 未开源, Microsoft论文,2018年4月挂arXiv,CVPR 2018论文。
-
- Xie G, Wang J, Zhang T, et al. IGCV2: Interleaved Structured Sparse Convolutional Neural Networks [C]// CVPR, 2018.
MoibleNetV2: tensorflow/models, Google论文,2018年1月挂arXiv最新v3,CVPR 2018论文。
-
- Sandler M, Howard A, Zhu M, et al. Inverted Residuals and Linear Bottlenecks: Mobile Networks for Classification, Detection and Segmentation [C]// CVPR, 2018.
背景介绍
首先介绍CNN中不同层的参数数量和理论计算量,简单起见小写代表下标,卷积核Kh*Kw,输入通道数Cin,输出通道数Cout,输出特征图的分辨率为宽H高W。
参数数量用params表示,关系到模型大小,单位通常为M,通常参数用float32表示,所以模型大小是参数数量的4倍。
理论计算量用FLOPs或者M-Adds表示,这里用FLOPs写起来简单,关系到算法速度,大模型的单位通常为G,小模型通道为M。注意两点:
理论计算量通常只考虑乘加操作(Multi-Adds)的数量,而且只考虑CONV和FC等参数层的计算量,忽略BatchNorm和PReLU等等。一般情况,CONV和FC层也会忽略仅纯加操作的计算量,如bias偏置加和shotcut残差加等,目前技术有BN的CNN可以不加bias。
理论计算量通常和实际ARM实测速度会有不一致,主要是理论计算量太过理论化,没有考虑不同硬件IO速度和计算力差异,最重要的是inference framework部署框架优化水平和程度差异,不同框架的优化的关注点不一样,同一框架对不同层的优化程度也不一样。Inference Framework以我用过的ncnn为代表。
CONV标准卷积层:
- #params:
,没有bias为
- #FLOPs:
FC全连接层,卷积核k=1:
- #params:
,没有bias为
- #FLOPs:
CONV和FC是经典CNN架构(如VGGNet和ResNet)中最重要的组件,CONV位于前面,作用类似特征提取,FC位于后面,作用类似分类决策。我们还需要两个卷积的变种。
GCONV分组(Group)卷积层,输入按通道数划分为g组,每小组独立分别卷积,结果联结到一起作为输出,如图中上面部分,Output channels作为GCONV的输入,分了3组分别CONV3x3,组内有信息流通,但不同分组之间没有信息流通。
- #params:
- #FLOPs:
DWCONV深度分离(DepthWise)卷积层,是GCONV的极端情况,分组数量等于输入通道数量,即每个通道作为一个小组分别进行卷积,结果联结作为输出,Cin = Cout = g,没有bias项,如图中上面部分,Output channels作为DWCONV的输入,划分了输入通道数量相等的分组,通道之间完全没有信息流通。
- #params:
- #FLOPs:
- CONV层主要贡献了计算量,如VGGNet第二个CONV层贡献了1.85G的计算量,参数数量仅37k
- FC层主要贡献了参数数量,如VGGNet第一个FC层25088-4096就有接近98M参数,贡献模型大小392M,计算量仅103M
- GCONV和DWCONV层参数量和计算量都非常小,GCONV参数数量减少g倍,计算量降低g倍,g越大压缩加速越明显;DWCONV是g=Cin的极端情况,压缩加速比是Cin倍,如MobileNet中第一个DWCONV层参数数量不到0.3k,计算量仅3.2M,这两者是高效CNN的核心构成要素。
Block分析:设计CNN目前都采用堆block的方式,后面对每个模型只集中分析其block的设计。堆Block简化了网络设计问题:只要设计好block结构,对于典型224x224输入,设计CNN只需要考虑112x112、56x56、28x28、14x14、7x7 这5个分辨率阶段(stage)的block数量和通道数量就可以了。
CNN加深度一般都选择14x14这个分辨率阶段,多堆几个block,这一层的参数数量和计算量占比最大,所以我们选这一层作为特例分析每种block的参数数量和计算量,量化说明选择14x14x该层通道数的输入和输出情况。
NiN及相关
最早的的小网络要从Network in Network说起,NiN是Shuicheng Yan组ICLR 2014的论文,提出在CONV3x3中插入CONV1x1层,和Global Average Pooling (GAP)层,虽然论文并没有强调这两个组件对减小CNN体积的作用,
但它们确实成为CNN压缩加速的核心:
- 同等输入CONV1x1比CONV3x3参数数量少9倍,理论计算量降低9倍
- GAP层没有参数,计算量可以忽略不计,是压缩模型的关键技术
GoogLeNet就大量使用层和GAP,与同时期性能相近的VGG-19相比,22层GoogLeNet模型参数少20倍以上,速度快10倍以上。GoogLeNet是最早的高效小网络,Inception系列沿袭这一架构理念,在均衡网络深度和模型大小方面都比较优秀。
(提问:截止2018.5.27,VGGNet论文的引用量是11499,GoogLeNet的应用量是7440次,同一时期的两个经典结构,看起来明显更好的GoogLeNet影响力为何反而不如VGGNet?
早期检测、跟踪和分割等方向的经典方法,如SSD, C-COT, FCN,骨架网络BackBone默认都是VGGNet,为什么都没有选更小更快的GoogLeNet?)
此外,ResNet还采用了另一项常用技术:
- 用CONV/s2(步进2的卷积)代替CONV+MaxPool,将Pool层合并到上一个CONV层,近似减少一半参数数量和计算量
综合以上技术,即使152层的ResNet,也比VGGNet小7倍,快12倍以上。目标检测的YOLO系列中,YOLOv2中提出的DarkNet-19采用了CONV1x1和GAP设计,YOLOv3的DarkNet-53加入了CONV/s2设计,两个CNN都是以上压缩加速技术的实例。
SqueezeNet
论文非常的标题党:同等精度比AlexNet小50倍,<0.5M的模型大小。SqueezeNet的核心设计理念是模型可以不快但一定要小,分析三个设计策略:
- 用CONV1x1代替CONV3x3,大量CONV3x3被替换,大幅减少参数和计算量
- 用squeeze层减少输入到CONV3x3的通道数,继续减少剩余CONV3x3层的参数数量和计算量
- 延迟下采样,保持激活的分辨率较大,同等参数数量效果更好,但这样会严重增加计算量
此外,保证conv10的通道数是1000,这样GAP后直接是1000个输出,这样连接到输出的最后一个FC层也省了,仅0.5M参数就完成了收尾部分,简直丧心病狂,但这种做法非常低效,仅conv10这一层的计算量就有100M。
SqueezeNet共8个Fire Module,2个CONV和4个POOL,没有BN,最终模型4.8M,在ImageNet上top-1 acc 57.5%, top-5 acc 80.3%,性能是AlexNet水平,经过DeepCompression进一步压缩后模型大小可以达到逆天的0.47M,但DeepCompression方法也是仅关心压缩不关心加速的。最后实验还测试了shotcut,证明类似ResNet那样最简单的shotcut最好,top-1和top-5分别提升2.9%和2.2%,性能提升明显且不会增加参数数量,几乎不会影响计算量,shotcut简直是a free lunch! (ResNet赛高)
论文描述的模型是SqueezeNet v1.0,后来代码又更新了SqueezeNet v1.1,模型大小和性能不变的情况下快了2.4倍:
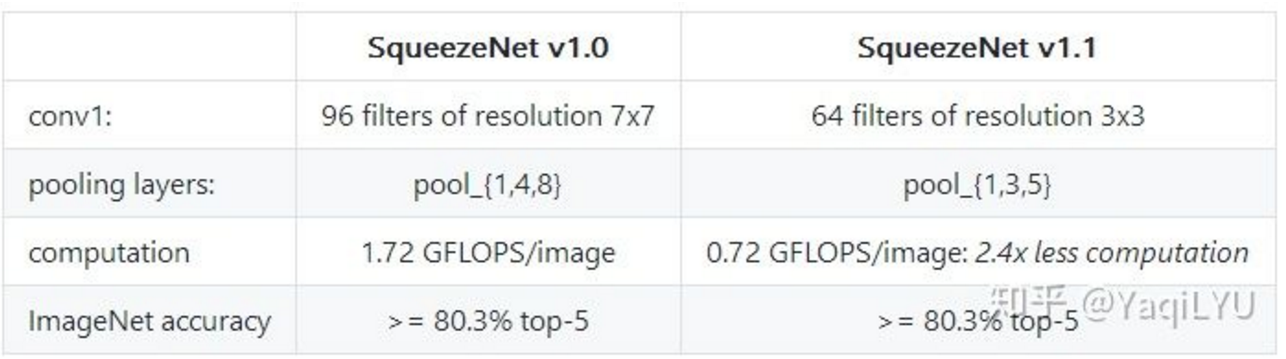
主要修改了第一层的卷积核大小和通道数,把下采样提前了,即抛弃了策略3。
SqueezeNet的计算量在MobileNet论文中是1700M,在ShuffleNet论文中是833,根据最新论文结果,SqueezeNet v1.0的理论计算量是837M,SqueezeNet v1.1的理论计算量是352M,ncnn-benchmark中所用测试模型就是SqueezeNet v1.1,所以在benchmark中SqueezeNet确实应该比MobileNet和AlexNet快。
stage的通道数量:【128 256 384-512 0】
stage的block数量:【2 2 4 0】
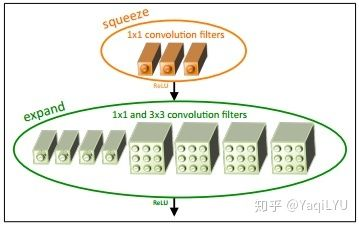
Block分析:加shotcut的一个典型SqueezeNet block,即论文中的Fire module
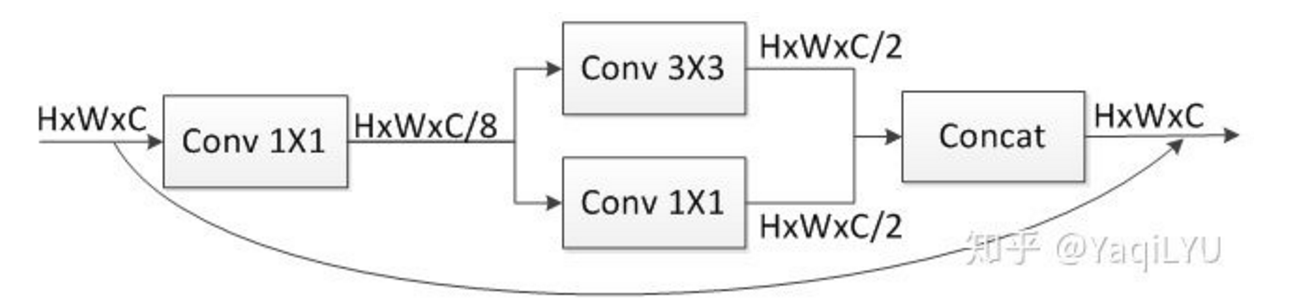
- #params:
- #FLOPs:
第一个CONV1x1将输入通道数压缩(squeeze)到1/8送给CONV3x3,上下两路CONV扩展(expand)四倍后联结,还原输入通道数量。block中CONV1x1和CONV3x3的参数数量之比是1:3,计算量之比也是1:3。
SqueezeNet中虽然大量使用CONV1x1,但CONV3x3占比依然在75%以上,inferece framework中CONV3x3的优化对速度影响更大。
(提问:如果要优化SqueezeNet而不用DWCONV,可以从哪几个方面修改结构?)
MobileNet
MobileNet是第一个面向移动端的小网络,设计兼顾模型小和速度快,提出了Depthwise Separable Convolution深度分离卷积,由DWCONV3x3 + CONV1x1组成,DWCONV3x3将CONV3x3的计算量降低到恐怖程度,后面的CONV1x1帮助信息在通道之间流通。这种结构非常高效,代替CONV后性能微小下降换取速度数倍提升。
MobileNet参数数量4.2M,计算量569M,top-1 70.6%,性能是GoogLeNet和VGG16水平,比最庞大的VGG16模型小32倍,计算量低27倍,比设计高效的GoogLeNet模型更小,计算量低2.5倍。
设计简单的直筒结构,是Google两年前的工作(参考回答Alan Huang:如何评价mobilenet v2 ?),第一层是CONV,之后堆叠DWCONV3x3 + CONV1x1, 每层都加BN没有shotcut,DWCONV/S2方式下采样,GAP后连FC到1000个分类输出,仅这个1024-1000的FC层就有1M参数。
论文提供了两个用户定制参数:
- Width Multiplier宽度乘子:所有层的通道数乘
,即CNN变瘦,模型大小近似下降
倍,计算量下降
- Resolution Multiplier分辨率乘子:输入分辨率乘
,等价于所有层的分辨率乘
倍
减少网络的层数也可以减少模型大小和计算量,即CNN变浅,实验给出同等参数和计算量,变浅比边瘦性能要差很多,强烈建议不要减深度!
(提问:很多论文都证明,同等参数和计算量,深度模型比宽度模型更好,深度也是一种正则方式?)
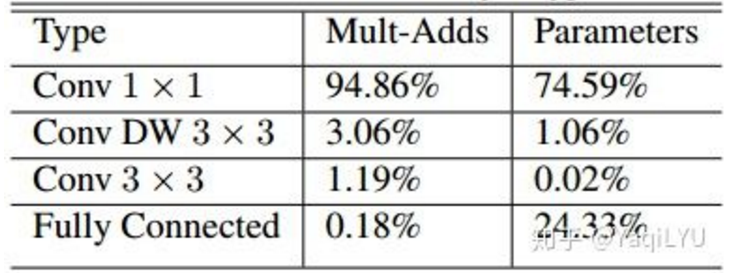
论文统计了不同类型层的计算量和参数数量,仅一个CONV一个FC,计算量可以忽略,前面也提到FC层参数占比较大,重点关注,大量使用的DWCONV33计算量仅3%,参数数量仅1%,其貌不扬的CONV1x1竟然是罪魁祸首,CONV1x1计算量占95%,参数数量占75%,所以MobileNet速度快不快,与inferece framework中CONV1x1的优化程度密切相关。
每个stage的通道数量:【128 256 512 1024】
每个stage的block数量:【2 2 6 2】
Block分析:MobileNet虽然没有明确指出,Depthwise Separable Convolution也可以看做block

- #params:
- #FLOPs:
DWCONV3x3以极低代价卷积产生特征,CONV1x1辅助通道信息流通,两者完美配合。block中CONV1x1和DWCONV3x3的计算量、参数数量比例是C:9,以疯狂加深度层14x14x512为例,二者比例是512:9=56.89,依然很震惊有木有,SqueezeNet中核心压缩加速手段CONV1x1,在MobileNet中反倒成了开销大户。
进一步优化MobileNet,降低CONV1x1的占比是关键。
DWCONV-bottleneck block
MobileNet的结构是类似VGGNet的直筒形式,目前ResNet已经取代了VGGNet,我们是不是按照ResNet中比较高效的bottleneck block构建更先进的DWCONV-bottleneck block呢?当然很简单,按照ResNet论文,CONV3x3换成DWCONV3x3就完成了。

- #params:
- #FLOPs:
ResNet代替VGGNet的历史告诉我们,这样做一定比MobileNet更好,要试一试吗?别着急,仔细看参数数量和计算量都增加了数倍(约8倍),block中CONV1x1和DWCONV3x3的计算量、参数数量比例是8C:9,还是以深度层14x14x512为例,二者比例高达8*512:9=455.11,再次震惊,这样做性能是上去了,但模型大小和速度都严重下降了,对于移动端这是我们最不愿看到的结果。
我终于把问题说明白了,铺垫的如此之多,CVPR 2018三篇高效小网络ShuffleNet, IGCV2和MobileNetV2就要隆重出场了。