在关系型数据库中 Join 是非常常见的操作,各种优化手段已经到了极致。在海量数据的环境下,不可避免的也会碰到这种类型的需求, 例如在数据分析时需要连接从不同的数据源中获取到数据。不同于传统的单机模式,在分布式存储下采用 MapReduce 编程模型,也有相应的处理措施和优化方法。
我们先简要地描述待解决的问题。假设有两个数据集:气象站数据库和天气记录数据库,并考虑如何合二为一。一个典型的查询是:输出气象站的历史信息,同时各行记录也包含气象站的元数据信息。
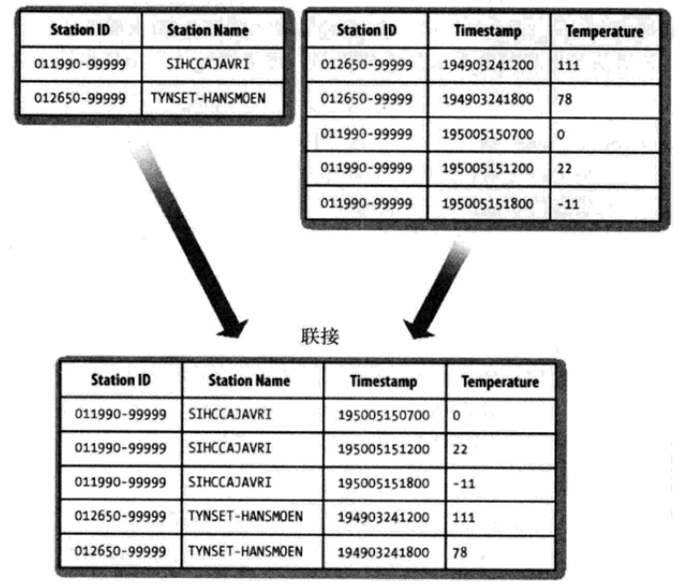
一、Reduce Join
在Reudce端进行连接是MapReduce框架实现join操作最常见的方式,其具体的实现原理如下:
Map端的主要工作:为来自不同表(文件)的key/value对打标签以区别不同来源的记录。然后用连接字段(两张表中相同的列)作为key,其余部分和新加的标志作为value,最后进行输出。
reduce端的主要工作:在reduce端以连接字段作为key的分组已经完成,我们只需要在每一个分组当中将那些来源于不同文件的记录(在map阶段已经打标志)分开,最后进行合并就ok了
实现方式一:二次排序

适用场景:其中一个表的连接字段key唯一
思路概述
二次排序的意思在map阶段只是对于不同表进行打标签排序,决定了在reduce阶段输出后两张中的先后顺序;而reduce的作用就是根本map输出的数据连接两张表。
代码实现
自定义TextPair作为两个文件的Mapper输出key。


package com.hadoop.reducejoin.test; import org.apache.hadoop.io.WritableComparable; import java.io.*; import org.apache.hadoop.io.*; import com.hadoop.mapreduce.test.IntPair; public class TextPair implements WritableComparable<TextPair> { private Text first;//Text 类型的实例变量 first private Text second;//Text 类型的实例变量 second public TextPair() { set(new Text(),new Text()); } public TextPair(String first, String second) { set(new Text(first),new Text(second)); } public TextPair(Text first, Text second) { set(first, second); } public void set(Text first, Text second) { this.first = first; this.second = second; } public Text getFirst() { return first; } public Text getSecond() { return second; } //将对象转换为字节流并写入到输出流out中 public void write(DataOutput out)throws IOException { first.write(out); second.write(out); } //从输入流in中读取字节流反序列化为对象 public void readFields(DataInput in)throws IOException { first.readFields(in); second.readFields(in); } @Override public int hashCode() { return first.hashCode() *163+second.hashCode(); } @Override public boolean equals(Object o) { if(o instanceof TextPair) { TextPair tp = (TextPair) o; return first.equals(tp.first) && second.equals(tp.second); } return false; } @Override public String toString() { return first +" "+ second; } @Override public int compareTo(TextPair o) { // TODO Auto-generated method stub if(!first.equals(o.first)){ return first.compareTo(o.first); } else if(!second.equals(o.second)){ return second.compareTo(o.second); }else{ return 0; } } }
package com.hadoop.reducejoin.test; import java.io.IOException; import java.util.Iterator; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.io.WritableComparator; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Partitioner; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.MultipleInputs; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; /* * 通过二次排序实现reduce join * 适用场景:其中一个表的连接字段key唯一 */ public class ReduceJoinBySecondarySort extends Configured implements Tool{ // JoinStationMapper 处理来自气象站数据 public static class JoinStationMapper extends Mapper< LongWritable,Text,TextPair,Text>{ protected void map(LongWritable key,Text value,Context context) throws IOException,InterruptedException{ String line = value.toString(); String[] arr = line.split("\s+");//解析天气记录数据 if(arr.length==2){//满足这种数据格式 //key=气象站id value=气象站名称 context.write(new TextPair(arr[0],"0"),new Text(arr[1])); } } } public static class JoinRecordMapper extends Mapper< LongWritable,Text,TextPair,Text>{ protected void map(LongWritable key,Text value,Context context) throws IOException,InterruptedException{ String line = value.toString(); String[] arr = line.split("\s+");//解析天气记录数据 if(arr.length==3){ //key=气象站id value=天气记录数据 context.write(new TextPair(arr[0],"1"),new Text(arr[1]+" "+arr[2])); } } } public static class KeyPartitioner extends Partitioner< TextPair,Text>{ public int getPartition(TextPair key,Text value,int numPartitions){ // &是位与运算 return (key.getFirst().hashCode()&Integer.MAX_VALUE)% numPartitions; } } public static class GroupingComparator extends WritableComparator{ protected GroupingComparator(){ super(TextPair.class, true); } @Override //Compare two WritableComparables. public int compare(WritableComparable w1, WritableComparable w2){ TextPair ip1 = (TextPair) w1; TextPair ip2 = (TextPair) w2; Text l = ip1.getFirst(); Text r = ip2.getFirst(); return l.compareTo(r); } } public static class JoinReducer extends Reducer< TextPair,Text,Text,Text>{ protected void reduce(TextPair key, Iterable< Text> values,Context context) throws IOException,InterruptedException{ Iterator< Text> iter = values.iterator(); Text stationName = new Text(iter.next());//气象站名称 while(iter.hasNext()){ Text record = iter.next();//天气记录的每条数据 Text outValue = new Text(stationName.toString()+" "+record.toString()); context.write(key.getFirst(),outValue); } } } public int run(String[] args) throws Exception{ Configuration conf = new Configuration();// 读取配置文件 Path mypath = new Path(args[2]); FileSystem hdfs = mypath.getFileSystem(conf);// 创建输出路径 if (hdfs.isDirectory(mypath)) { hdfs.delete(mypath, true); } Job job = Job.getInstance(conf, "join");// 新建一个任务 job.setJarByClass(ReduceJoinBySecondarySort.class);// 主类 Path recordInputPath = new Path(args[0]);//天气记录数据源 Path stationInputPath = new Path(args[1]);//气象站数据源 Path outputPath = new Path(args[2]);//输出路径 // 两个输入类型 MultipleInputs.addInputPath(job,recordInputPath,TextInputFormat.class,JoinRecordMapper.class);//读取天气记录Mapper MultipleInputs.addInputPath(job,stationInputPath,TextInputFormat.class,JoinStationMapper.class);//读取气象站Mapper FileOutputFormat.setOutputPath(job,outputPath); job.setReducerClass(JoinReducer.class);// Reducer job.setPartitionerClass(KeyPartitioner.class);//自定义分区 job.setGroupingComparatorClass(GroupingComparator.class);//自定义分组 job.setMapOutputKeyClass(TextPair.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); return job.waitForCompletion(true)?0:1; } public static void main(String[] args) throws Exception{ String[] args0 = {"hdfs://sparks:9000/middle/reduceJoin/records.txt" ,"hdfs://sparks:9000/middle/reduceJoin/station.txt" ,"hdfs://sparks:9000/middle/reduceJoin/secondSort-out" }; int exitCode = ToolRunner.run(new ReduceJoinBySecondarySort(),args0); System.exit(exitCode); } }
实现方式二:笛卡尔积

适用场景:两个表的连接字段key都不唯一(包含一对多,多对多的关系)
思路概述
在map阶段将来自不同表或文件的key、value打标签对区别不同的来源,在reduce阶段对于来自不同表或文件的相同key的数据分开,然后做笛卡尔积。这样就实现了连接表。
代码实现
package com.hadoop.reducejoin.test; import java.io.IOException; import java.util.ArrayList; import java.util.List; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.FileSplit; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; /* * 两个大表 * 通过笛卡尔积实现 reduce join * 适用场景:两个表的连接字段key都不唯一(包含一对多,多对多的关系) */ public class ReduceJoinByCartesianProduct { /** 为来自不同表(文件)的key/value对打标签以区别不同来源的记录。 然后用连接字段作为key,其余部分和新加的标志作为value,最后进行输出。 */ public static class ReduceJoinByCartesianProductMapper extends Mapper<Object,Text,Text,Text>{ private Text joinKey=new Text(); private Text combineValue=new Text(); @Override protected void map(Object key, Text value, Context context) throws IOException, InterruptedException { String pathName=((FileSplit)context.getInputSplit()).getPath().toString(); //如果数据来自于records,加一个records的标记 if(pathName.endsWith("records.txt")){ String line = value.toString(); String[] valueItems = line.split("\s+"); //过滤掉脏数据 if(valueItems.length!=3){ return; } joinKey.set(valueItems[0]); combineValue.set("records.txt" + valueItems[1] + " " + valueItems[2]); }else if(pathName.endsWith("station.txt")){ //如果数据来自于station,加一个station的标记 String line = value.toString(); String[] valueItems = line.split("\s+"); //过滤掉脏数据 if(valueItems.length!=2){ return; } joinKey.set(valueItems[0]); combineValue.set("station.txt" + valueItems[1]); } context.write(joinKey,combineValue); } } /* * reduce 端做笛卡尔积 */ public static class ReduceJoinByCartesianProductReducer extends Reducer<Text,Text,Text,Text>{ private List<String> leftTable=new ArrayList<String>(); private List<String> rightTable=new ArrayList<String>(); private Text result=new Text(); @Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { //一定要清空数据 leftTable.clear(); rightTable.clear(); //相同key的记录会分组到一起,我们需要把相同key下来自于不同表的数据分开,然后做笛卡尔积 for(Text value : values){ String val=value.toString(); if(val.startsWith("station.txt")){ leftTable.add(val.replaceFirst("station.txt","")); }else if(val.startsWith("records.txt")){ rightTable.add(val.replaceFirst("records.txt","")); } } //笛卡尔积 for(String leftPart:leftTable){ for(String rightPart:rightTable){ result.set(leftPart+" "+rightPart); context.write(key, result); } } } } public static void main(String[] arg0) throws Exception{ Configuration conf = new Configuration(); String[] args = {"hdfs://sparks:9000/middle/reduceJoin/records.txt" ,"hdfs://sparks:9000/middle/reduceJoin/station.txt" ,"hdfs://sparks:9000/middle/reduceJoin/JoinByCartesian-out" }; String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); if (otherArgs.length < 2) { System.err.println("Usage: reducejoin <in> [<in>...] <out>"); System.exit(2); } //输出路径 Path mypath = new Path(otherArgs[otherArgs.length - 1]); FileSystem hdfs = mypath.getFileSystem(conf);// 创建输出路径 if (hdfs.isDirectory(mypath)) { hdfs.delete(mypath, true); } Job job = Job.getInstance(conf, "ReduceJoinByCartesianProduct"); job.setJarByClass(ReduceJoinByCartesianProduct.class); job.setMapperClass(ReduceJoinByCartesianProductMapper.class); job.setReducerClass(ReduceJoinByCartesianProductReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); //添加输入路径 for (int i = 0; i < otherArgs.length - 1; ++i) { FileInputFormat.addInputPath(job, new Path(otherArgs[i])); } //添加输出路径 FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
实现方式三:分布式缓存

适用场景:一个大表和一个小表连接
分布式知识点补充
当 MapReduce 处理大型数据集间的 join 操作时,此时如果一个数据集很大而另外一个集合很小,以至于可以分发到集群中的每个节点之中。 这种情况下,我们就用到了 Hadoop 的分布式缓存机制,它能够在任务运行过程中及时地将文件和存档复制到任务节点以供使用。为了节约网络宽带,在每一个作业中, 各个文件通常只需要复制到一个节点一次。
1、用法
Hadoop 命令行选项中,有三个命令可以实现文件复制分发到任务的各个节点。
1)用户可以使用 -files 选项指定待分发的文件,文件内包含以逗号隔开的 URL 列表。文件可以存放在本地文件系统、HDFS、或其它 Hadoop 可读文件系统之中。 如果尚未指定文件系统,则这些文件被默认是本地的。即使默认文件系统并非本地文件系统,这也是成立的。
2)用户可以使用 -archives 选项向自己的任务中复制存档文件,比如JAR 文件、ZIP 文件、tar 文件和 gzipped tar文件,这些文件会被解档到任务节点。
3)用户可以使用 -libjars 选项把 JAR 文件添加到 mapper 和 reducer 任务的类路径中。如果作业 JAR 文件并非包含很多库 JAR 文件,这点会很有用。
2、工作机制
当用户启动一个作业,Hadoop 会把由 -files、-archives、和 -libjars 等选项所指定的文件复制到分布式文件系统之中。接着,在任务运行之前, tasktracker 将文件从分布式文件系统复制到本地磁盘(缓存)使任务能够访问文件。此时,这些文件就被视为 “本地化” 了。从任务的角度来看, 这些文件就已经在那儿了,它并不关心这些文件是否来自 HDFS 。此外,有 -libjars 指定的文件会在任务启动前添加到任务的类路径(classpath)中。
3、分布式缓存 API
由于可以通过 Hadoop 命令行间接使用分布式缓存,大多数应用不需要使用分布式缓存 API。然而,一些应用程序需要用到分布式缓存的更高级的特性,这就需要直接使用 API 了。 API 包括两部分:将数据放到缓存中的方法,以及从缓存中读取数据的方法。
1)首先掌握数据放到缓存中的方法,以下列举 Job 中可将数据放入到缓存中的相关方法:
public void addCacheFile(URI uri); public void addCacheArchive(URI uri);//以上两组方法将文件或存档添加到分布式缓存 public void setCacheFiles(URI[] files); public void setCacheArchives(URI[] archives);//以上两组方法将一次性向分布式缓存中添加一组文件或存档 public void addFileToClassPath(Path file); public void addArchiveToClassPath(Path archive);//以上两组方法将文件或存档添加到 MapReduce 任务的类路径 public void createSymlink();
在缓存中可以存放两类对象:文件(files)和存档(achives)。文件被直接放置在任务节点上,而存档则会被解档之后再将具体文件放置在任务节点上。
2)其次掌握在 map 或者 reduce 任务中,使用 API 从缓存中读取数据。
public Path[] getLocalCacheFiles() throws IOException; public Path[] getLocalCacheArchives() throws IOException; public Path[] getFileClassPaths(); public Path[] getArchiveClassPaths();
我们可以使用 getLocalCacheFiles()和getLocalCacheArchives()方法获取缓存中的文件或者存档的引用。 当处理存档时,将会返回一个包含解档文件的目的目录。相应的,用户可以通过 getFileClassPaths()和getArchivesClassPaths()方法获取被添加到任务的类路径下的文件和文档。
思路概述
小表作为缓存分发至各个节点,在reduce阶段,通过读取缓存中的小表过滤大表中一些不需要的数据和字段。
代码实现
package com.hadoop.reducejoin.test; import java.io.BufferedReader; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; import java.io.InputStreamReader; import java.net.URI; import java.util.Hashtable; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.Reducer.Context; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import org.apache.hadoop.util.bloom.Key; /* * 通过分布式缓存实现Reduce Join * 适用场景:其中一个表比较小,能放入内存 */ public class ReduceJoinByDistributedCache extends Configured implements Tool { //直接输出大表数据records.txt public static class ReduceJoinByDistributedCacheMapper extends Mapper< LongWritable, Text, Text, Text> { private Text combineValue=new Text(); public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] arr = line.split("\s+"); if (arr.length == 3) { combineValue.set(arr[1] + " " + arr[2]); context.write(new Text(arr[0]), combineValue); } } } //在reduce 端通过缓存文件实现join操作 public static class ReduceJoinByDistributedCacheReducer extends Reducer< Text, Text, Text, Text> { //定义Hashtable存放缓存数据 private Hashtable< String, String> table = new Hashtable< String, String>(); /** * 获取分布式缓存文件 */ protected void setup(Context context) throws IOException, InterruptedException { BufferedReader br; String infoAddr = null; // 返回缓存文件路径 Path[] cacheFilesPaths = context.getLocalCacheFiles(); for (Path path : cacheFilesPaths) { String pathStr = path.toString(); br = new BufferedReader(new FileReader(pathStr)); while (null != (infoAddr = br.readLine())) { // 按行读取并解析气象站数据 String line = infoAddr.toString(); String[] records = line.split("\s+"); if (null != records) // key为stationID,value为stationName table.put(records[0], records[1]); } } } public void reduce(Text key, Iterable< Text> values, Context context) throws IOException, InterruptedException { //天气记录根据stationId 获取stationName String stationName = table.get(key.toString()); for (Text value : values) { value.set(stationName + " " + value.toString()); context.write(key, value); } } } public int run(String[] arg0) throws Exception { Configuration conf = new Configuration(); String[] args = {"hdfs://sparks:9000/middle/reduceJoin/station.txt" ,"hdfs://sparks:9000/middle/reduceJoin/records.txt" ,"hdfs://sparks:9000/middle/reduceJoin/DistributedCache-out" }; String[] otherArgs = new GenericOptionsParser(conf, args) .getRemainingArgs(); if (otherArgs.length < 2) { System.err.println("Usage: cache <in> [<in>...] <out>"); System.exit(2); } //输出路径 Path mypath = new Path(otherArgs[otherArgs.length - 1]); FileSystem hdfs = mypath.getFileSystem(conf);// 创建输出路径 if (hdfs.isDirectory(mypath)) { hdfs.delete(mypath, true); } Job job = Job.getInstance(conf, "ReduceJoinByDistributedCache"); //添加缓存文件 job.addCacheFile(new Path(otherArgs[0]).toUri());//station.txt job.setJarByClass(ReduceJoinByDistributedCache.class); job.setMapperClass(ReduceJoinByDistributedCacheMapper.class); job.setReducerClass(ReduceJoinByDistributedCacheReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); //添加输入路径 for (int i = 1; i < otherArgs.length - 1; ++i) { FileInputFormat.addInputPath(job, new Path(otherArgs[i])); } //添加输出路径 FileOutputFormat.setOutputPath(job, new Path( otherArgs[otherArgs.length - 1])); return job.waitForCompletion(true) ? 0 : 1; } public static void main(String[] args) throws Exception { int ec = ToolRunner.run(new Configuration(),new ReduceJoinByDistributedCache(), args); System.exit(ec); } }
Reduce Join的不足
这里主要分析一下reduce join的一些不足。之所以会存在reduce join这种方式,是因为整体数据被分割了,每个map task只处理一部分数据而不能够获取到所有需要的join字段,因此我们可以充分利用mapreduce框架的特性,让他按照join key进行分区,将所有join key相同的记录集中起来进行处理,所以reduce join这种方式就出现了。
这种方式的缺点很明显就是会造成map和reduce端也就是shuffle阶段出现大量的数据传输,效率很低。