编写更好的C#代码
引言
开发人员总是喜欢就编码规范进行争论,但更重要的是如何能够在项目中自始至终地遵循编码规范,以保证项目代码的一致性。并且团队中的所有人都需要明确编码规范所起到的作用。在这篇文章中,我会介绍一些在我多年的从业过程中所学习和总结的一些较好的实践。
举例为先
我们先来看一个 FizzBuzz 示例。FizzBuzz 要求编写一个程序,遍历从 1 到 100 的数字。其中如果某数字是 3 的倍数,则程序输出 “Fizz”。如果某数字是 5 的倍数,则输出 “Buzz”。如果某数字即是 3 的倍数也是 5 的倍数,则输出 “FizzBuzz”。如果数字既不是 3 的倍数也不是 5 的倍数,则只需输出该数字本身。

示例1:

1 public static void Test() 2 { 3 for (int i = 1; i < 101; i++) 4 { 5 if (i % 3 == 0 && i % 5 == 0) 6 { 7 Console.WriteLine("FizzBuzz"); 8 } 9 else if (i % 3 == 0) 10 { 11 Console.WriteLine("Fizz"); 12 } 13 else if (i % 5 == 0) 14 { 15 Console.WriteLine("Buzz"); 16 } 17 else 18 { 19 Console.WriteLine(i); 20 } 21 } 22 }
什么感觉?这段代码需要改进吗?
示例2:
1 public static void Check() 2 { 3 for (int i = 1; i <= 100; i++) 4 { 5 string output = ""; 6 if (i % 3 == 0) { output = "Fizz"; } 7 if (i % 5 == 0) { output = output + "Buzz"; } 8 if (output == "") { output = i.ToString(); } 9 Console.WriteLine(output); 10 } 11 }
现在感觉如何?还能不能进一步改进?
好,让我们来尝试改进下。代码命名对所有软件开发人员来说都是件非常困难的事情。我们花费了大量的时间来做这件事,而且有太多的需要被命名的元素,例如属性、方法、类、文件、项目等。不过我们的确需要花费一些精力在这些命名上,以使代码中的名称更有意义,进而可以提高代码的可读性。
1 public void DoFizzBuzz() 2 { 3 for (int number = 1; number <= 100; number++) 4 { 5 var output = GetFizzBuzzOutput(number); 6 Console.WriteLine(output); 7 } 8 } 9 10 private static string GetFizzBuzzOutput(int number) 11 { 12 string output = string.Empty; 13 if (number % 3 == 0) 14 { 15 output = "Fizz"; 16 } 17 if (number % 5 == 0) 18 { 19 output += "Buzz"; 20 } 21 if (string.IsNullOrEmpty(output)) 22 { 23 output = number.ToString(); 24 } 25 return output; 26 }
这次感觉怎样?是不是比之前的示例要好些?是不是可读性更好些?
什么是更好的代码?
首先就是代码要为人来编写,其次是为机器。从长期来看,编写可读性好的代码不会比编写混乱的代码要花费更长的时间。如果你能够非常容易地读懂你写的代码,那么想确认其可以正常工作就更容易了。这应该已经是编写易读代码足够充分的理由了。在很多情况下都需要阅读代码,例如在代码评审中会阅读你写的代码,在你或者其他人修复Bug时会阅读你写的代码,在代码需要修改时也会读到。还有就是当其他人准备在类似的项目或有类似功能的项目中尝试复用你的部分代码时也会先阅读你的代码。
“如果你只为你自己写代码,为什么要使代码更具可读性?”
好,编写易读的代码最主要的原因是,在未来的一到两周,你将工作在另一个项目上。而此时,有其他人需要修复当前项目的一个Bug,那么将会发生什么?我敢保证他肯定会迷失在你自己编写的恐怖代码中。

从我的个人观点来看,好的代码应该拥有以下几个特征:
- 代码容易编写,并易于修改和扩展。
- 代码干净,并表述准确。
- 代码有价值,并注重质量。
所以,要时刻考虑先为人来编写代码,然后再满足机器的需要。
如何改进可读性?

首先,你需要阅读学习其他人编写的代码,来了解什么是好的代码,什么是不好的代码。也就是那些你感觉非常容易理解的代码,和感觉看起来超级复杂的代码。然后,进行实践。最后花费一些时间、经验和实践来改进你的代码的可读性。一般来讲仅通过培训这种方式,在任何软件公司中推动编码规范都有些困难。而诸如结对代码评审,自动化代码评审工具等也可以帮助你。目前流行的工具有:
- FxCop:对 .NET 代码进行静态代码分析,提供了多种规则来进行不同形式的分析。
- StyleCop:开源项目,其使用代码风格和一致性规范来对分析C#代码。可在 Visual Studio 中运行,也可以集成到 MSBuild 中。StyleCop 也已经被集成到了一些第三方开发工具中。
- JetBrains ReSharper:非常著名的提升生产力的工具,可以使 Microsoft Visual Studio IDE 更加强大。全世界的 .NET 开发人员可能都无法想象,工作中怎么能没有 ReSharper 的代码审查、代码自动重构、快速导航和编码助手等这些强大的功能呢。
规范是什么?

依据维基百科上的描述:“Coding conventions are a set of guidelines for a specific programming language that recommend programming style, practices and methods for each aspect of a piece program written in this language. These conventions usually cover file organization, indentation, comments, declarations, statements, white space, naming conventions, programming practices, programming principles, programming rules of thumb, architectural best practices, etc. These are guidelines for software structural quality. Software programmers are highly recommended to follow these guidelines to help improve the readability of their source code and make software maintenance easier. Coding conventions are only applicable to the human maintainers and peer reviewers of a software project. Conventions may be formalized in a documented set of rules that an entire team or company follows, or may be as informal as the habitual coding practices of an individual. Coding conventions are not enforced by compilers. As a result, not following some or all of the rules has no impact on the executable programs created from the source code.”。
你应该能说出属性、局部变量、方法名、类名等的不同,因为它们使用不同的大小写约定,所以这些约定非常有价值。通过互联网,你已经了解了很多相应的准则和规范,你所需要的仅是找到一种规范或者建立你自己的规范,然后始终遵循该规范。
下面使用到的源代码(类库设计准则)是由微软的 Special Interest Group 团队开发的,我只是做了些扩展。
大小写约定
下面是一些关于C#编码标准、命名约定和最佳实践的示例,可以根据你自己的需要来使用。
Pascal Casing
标示符中的首字母,后续串联的每个单词的首字母均为大写。如果需要,标示符的前几个字母均可大写。
Camel Casing
标示符的首字母为小写,后续串联的每个单词的首字母为大写。
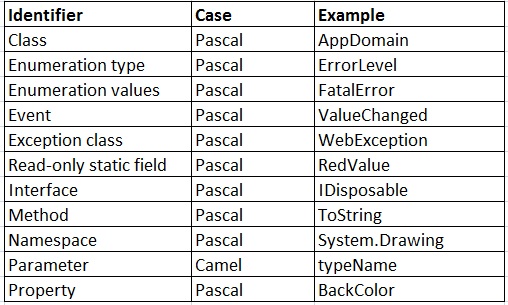
参考:标示符大小写规则
一些命名约定示例
在互联网上你可以找到足够多的资源,我只是推荐几个其中我最喜欢的:
这里我展示了一些最基本的示例,但就像我上面已经提到的,找到一个适合你的规范,然后坚持使用。
要使用 Pascal Casing 为类和方法命名。
public class Product { public void GetActiveProducts() { //... } public void CalculateProductAdditinalCost() { //... } }
要使用 Camel Casing 为方法的参数和局部变量命名。
public class ProductCategory { public void Save(ProductCategory productCategory) { // ... } }
不要使用缩写语。
// Correct ProductCategory productCategory; // Avoid ProductCategory prodCat;
不要在标示符中使用下划线。
// Correct ProductCategory productCategory; // Avoid ProductCategory product_Category;
要在接口名称前使用字母 I 。
public interface IAddress { }
要在类的顶端定义所有成员变量,在最顶端定义静态变量。
public class Product { public static string BrandName; public string Name { get; set; } public DateTime DateAvailable { get; set; } public Product() { // ... } }
要使用单数的词汇定义枚举,除非是BitField枚举。
public enum Direction { North, East, South, West }
不要为枚举名称添加Enum后缀。
//Avoid public enum DirectionEnum { North, East, South, West }
为什么我们需要编码规范?
在大型项目中,开发人员会常依赖于编码规范。他们建立了很多规范和准则,以至于记住这些规范和准则已经变成了日常工作的一部分。计算机并不关心你写的代码可读性是否好,比起读懂那些高级的程序语言语句,计算机更容易理解二进制的机器指令。
编码规范提供了很多明显的好处,当然有可能你得到的更多。通常这些项目整体范围的规划,将使能够将精力更多的集中在代码中更重要的部分上。
- 编码规范可以帮助跨项目的传递知识。
- 编码规范可以帮助你在新的项目上更快速的理解代码。
- 编码规范强调组织中关联项目间的关系。
你需要编写可读性高的代码,以此来帮助其他人来理解你的代码。代码命名对我们软件开发人员来说是件非常困难的事情,我们在这上面已经花费了大量的时间,并且有太多的需要命名的元素,例如属性、方法、类、文件、项目等。所以我们确实需要花费一些精力在命名规范上,以使名称更有意义,进而提高代码的可读性。
还有,编码规范可以让你晚上睡得更香。

开发人员最应该遵循的几个规则

始终控制类的大小
我曾经看到过,并且也曾写过一些超大的类。而且不幸的是,结果总是不好的。后来我找到了真正原因,就是那些超大的类在尝试做太多的事情,这违反了单一职责原则(SRP),也就是面向对象设计原则 SOLID 中的 S。
“The single responsibility principle states that every object should have a single responsibility, and that responsibility should be entirely encapsulated by the class. All its services should be narrowly aligned with that responsibility.”
或者按照 Martin Fowler 的定义:"THERE SHOULD NEVER BE MORE THAN ONE REASON FOR A CLASS TO CHANGE."

为什么一定要将两个职责分离到单独的类中呢?因为每一个职责都是变化的中心。在需求变更时,这个变更将会出现在负责该职责的类中。如果一个类承担了多个职责,就会有一个以上的原因导致其变化。如果一个类有多重职责,则说明这些职责已经耦合到了一起。并且某个职责的变化将有可能削弱或限制这个类满足其他职责的能力。这种耦合将会导致非常脆弱的设计,进而在职责发生变化时,设计可能被意想不到的破坏了。
避免过时的注释
先说什么过时的注释。按照 Robert C. Martin 的定义:
"A comment that has gotten old, irrelevant, and incorrect is obsolete. Comments get old quickly. It is best not to write a comment that will become obsolete. If you find an obsolete comment, it is best to update it or get rid of it as quickly as possible. Obsolete comments tend to migrate away from the code they once described. They become floating islands of irrelevance and misdirection in the code."
针对这个主题,不同水平的开发人员可能都会有自己的见解。我的建议是尝试避免为单独的方法或短小的类进行注释。因为我所见过的大部分的注释都是在尝试描述代码的目的或意图,或者某些注释可能本身就没什么意义。通常开发人员通过写注释来提高代码的可读性和可维护性,但要保证你所写的注释不会成为代码中的噪音。比起注释,我认为合理的方法命名将更为有效,比如你可以为一个方法起一个更有意义的名字。大部分注释都可能变成了无意义的代码噪音,让我们来看看下面这些注释:
//ensure that we are not exporting //deleted products if (product.IsDeleted && !product.IsExported) { ExportProducts = false; } // This is a for loop that prints the 1 million times for (int i = 0; i < 1000000; i++) { Console.WriteLine(i); }
如果我们不写注释,而是命名一个方法,比如叫 CancelExportForDeletedProducts() ,情况会怎样?所以,合适的方法命名比注释更有效。然而某些情况下,代码注释也会非常有帮助,比如 Visual Studio 会从注释生成 API 文档。此处的注释略有不同,你需要使用 “///” 标识符来注释,这样其他开发人员才能看到 API 或类库的智能提示。
我没有说总是要避免注释。按照 Kent Beck 说法,可以使用更多的注释来描述程序整体是如何工作的,而不是对单独的方法进行注释。如果注释是在尝试描述代码的目的或意图,那就错了。如果你在代码中看到了密密麻麻的的注释,你可能就会意识到有这么多注释说明代码写的很糟糕。了解更多信息可以阅读下面这几本书:
- 《Professional Refactoring in C# and ASP.NET》 by Danijel Arsenovski
- 《重构:改善既有代码设计》 by Martin Fowler, Kent Beck, John Brant, William Opdyke, Don Roberts
避免不必要的Region
Region 是 Visual Studio 提供的一个功能,它允许你将代码分块。Region 的存在是因为它可以使大文件导航变得容易。Region 还常被用于隐藏丑陋的代码,或者类已经膨胀的非常大了需要分块。而如果一个类做了太多的事情,也就说明其违反了单一职责原则。所以,下次当你想新增一个 Region 时,先考虑下有没有可能将这个 Region 分离到一个单独的类中。
保持方法的短小
方法中的代码行数越多,则方法越难理解。我们推荐每个方法中只包含 20-25 行代码。但有些人说 1-10 行更合理,这只是些个人喜好,没有硬性的规则。抽取方法是最常见的重构方式之一。如果你发现一个方法过长,或者已经需要一个注释来描述它的目的了,那么你就可以应用抽取方法了。人们总是会问一个方法到底多长合适,但其实长度并不是问题的根源。当你在处理复杂的方法时,跟踪所有局部变量是最复杂和消耗时间的,而通过抽取一个方法可以节省一些时间。可以使用 Visual Studio 来抽取方法,它会帮助你跟踪局部变量,并将其传递给新的方法或者接收方法的返回值。
Using ReSharper
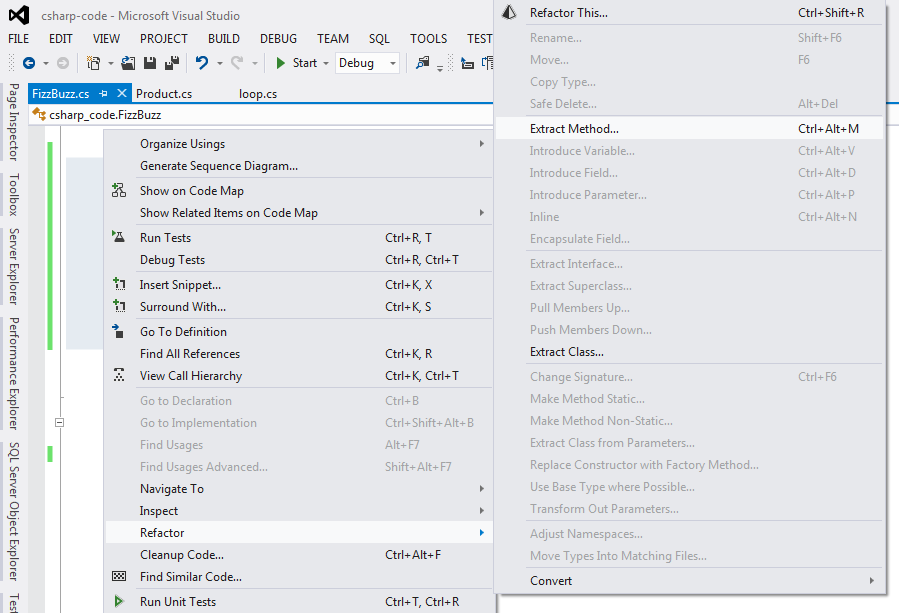
Using Microsoft Visual Studio

更多的信息可以参考 MSDN。
按照《重构:改善既有代码设计》中的描述,
"Extract Method is one of the most common refactoring I do. I look at a method that is too long or look at code that needs a comment to understand its purpose. I then turn that fragment of code into its own method. I prefer short, well-named methods for several reasons. First, it increases the chances that other methods can use a method when the method is finely grained. Second, it allows the higher-level methods to read more like a series of comments. Overriding also is easier when the methods are finely grained. It does take a little getting used to if you are used to seeing larger methods. And small methods really work only when you have good names, so you need to pay attention to naming. People sometimes ask me what length I look for in a method. To me length is not the issue. The key is the semantic distance between the method name and the method body. If extracting improves clarity, do it, even if the name is longer than the code you have extracted."
避免过多的参数
通过声明一个类来代替多个参数。创建一个类,用于包含所有的参数。通常来讲,这是一个较好的设计,并且这个抽象非常的有价值。
//avoid public void Checkout(string shippingName, string shippingCity, string shippingSate, string shippingZip, string billingName, string billingCity, string billingSate, string billingZip) { } //DO public void Checkout(ShippingAddress shippingAddress, BillingAddress billingAddress) { }
我们需要引入类来代替所有的参数。
避免复杂的表达式
if(product.Price>500 && !product.IsDeleted && !product.IsFeatured && product.IsExported) { // do something }
复杂的表达式意味着其背后隐藏了一些涵义,我们可以通过使用属性来封装这些表达式,进而使代码更易读些。
把警告等同于错误
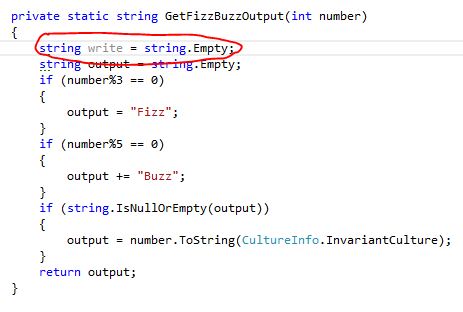
如果你注意看代码,你会发现一个变量被声明了但从没被使用过。正常来讲,我们编译工程后会得到一个警告,但仍可以运行工程而不会发生任何错误。但是我们应该尽可能地移除这些警告。通过如下步骤可以在工程上设置将警告等同于错误:
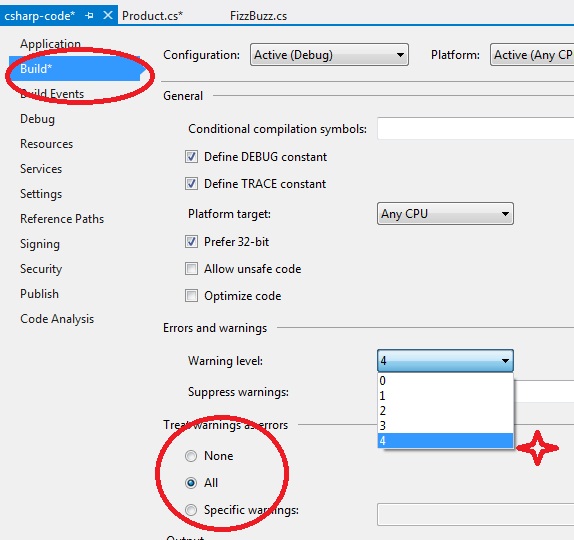
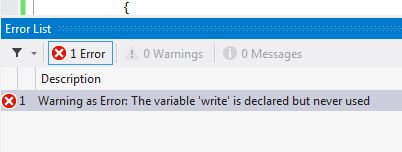
精简多处返回
在每段程序中都减少函数返回的数量。假设从底部开始阅读代码,你很难意识到有可能在上面的某处已经返回了,这样的代码将是非常难理解的。
仅使用一处返回可以增强可读性。如果程序这么写的话可能看起来比较干净,但不立即返回也意味着需要编写更多代码。
//avoid if(product.Price>15) { return false; } else if(product.IsDeleted) { return false; } else if(!product.IsFeatured) { return false; } else if() { //..... } return true;
//DO var isValid = true; if(product.Price>15) { isValid= false; } else if(product.IsDeleted) { isValid= false; } else if(!product.IsFeatured) { isValid= false; } return isValid;
你可以想象在这 20-30 行代码中就散落了 4 个退出点,这会使你非常难理解到底程序内部做了什么,到底会执行什么,什么时候执行。
关于这一点我得到了很多人的回复,一些人同意这个观点,有些则不同意这是一个好的编码标准。为了找出潜在的问题,我做了些单元测试,发现如果复杂的方法包含多个退出点,通常情况下会需要一组测试来覆盖所有的路径。
if( BADFunction() == true) { // expression if( anotherFunction() == true ) { // expression return true; } else { //error } } else { //error } return false;
if( !GoodFunction()) { // error. return false } // expression if( !GoodFunction2()) { //error. return false; } // more expression return true;
进一步理解可以参考 Steve McConnell 的《代码大全》。
使用断言
在软件开发中,断言代码常被用于检查程序代码是否按照其设计在执行。通常 True 代表所有操作按照预期的完成,False 代表已经侦测到了一些意外的错误。断言通常会接收两个参数,一个布尔型的表达式用于一个描述假设为真的假定,一个消息参数用于描述断言失败的原因。
尤其在开发大型的、复杂的高可靠系统中,断言通常是非常有用的功能。
例如:如果系统假设将最多支持 100,000 用户记录,系统中可能会包含一个断言来检查用户记录数小于等于 100,000,在这种范围下,断言不会起作用。但如果用户记录数量超过了 100,000,则断言将会抛出一个错误来告诉你记录数已经超出了范围。
检查循环端点值
一个循环通常会涉及三种条件值:第一个值、中间的某值和最后一个值。但如果你有任何其他的特定条件,也需要进行检测。如果循环中包含了复杂的计算,请不要使用计算器,要手工检查计算结果。
总结
通常在任何软件公司中推行编码规范都需要按照组织行为、项目属性和领域来进行,在此我想再次强调“找到一个适合你的编码规范,并一直遵循它”。
如果你认为我遗漏了某个特别有用的编码准则,请在评论中描述,我会尝试补充到文章中。
Coding For Fun.
译者注:原文作者 Monjurul Habib 看起来是孟加拉国人,我感觉作者的英语非常生硬,有些地方我实在是理解不上去,读者见谅。