银行分控模型的建立
一、Logistic回归模型:
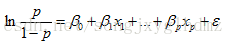
(一)Logistic回归建模步骤
1. 根据分析目的设置指标变量(因变量和自变量),根据收集到的数据进行筛选
2. 用ln(p/1-p)和自变量x1...xp列出线性回归方程,估计出模型中的回归系数
3. 进行模型检验。模型有效性检验的函数有很多,比如正确率、混淆矩阵、ROC曲线、KS值
4. 模型应用。
(二)对某银行在降低贷款拖欠率的数据进行建模
代码:
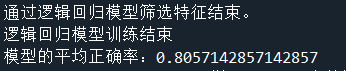
#银行分控模型的建立 # 逻辑回归 自动建模 import pandas as pd # 参数初始化 filename=r'data\bankloan.xls' data=pd.read_excel(filename) x=data.iloc[:,:8].values #将数据的0-8列生成数组形式,用于后期进行训练模型(数据仅有8列) y=data.iloc[:,8].values #将数据的第8列生成数组形式,用于后期进行训练模型 from sklearn.linear_model import LogisticRegression as LR #导入逻辑回归模型 print(u'通过逻辑回归模型筛选特征结束。') data2=data.drop(u'违约',1) lr=LR() # 建立逻辑回归模型 lr.fit(x,y) # 用筛选后的特征数据来训练模型 print(u'逻辑回归模型训练结束') print(u'模型的平均正确率:%s'%lr.score(x,y)) # 给出模型的平均正确率为80.6%
运行结果:
逻辑回归本质上还是一种线性模型。筛选出来的特征并不一定就跟结果没有关系,只是它们之间有可能是非线性关系。在真实应用中,还是要根据问题的实际背景对筛选结果进行分析。对于非线性关系的特征筛选方法有决策树、神经网络等
二、神经网络建模
人工神经网络(Artificial Neural Networks, ANN),是模拟生物神经网络进行信息处 理的一种数学模型。它以对大脑的生理研究成果为基础,其目的在于模拟大脑的某些机理与 机制,实现一些特定的功能。
人工神经网络的学习也称为训练,指的是神经网络在受到外部环境的刺激下调整神经网 络的参数,使神经网络以一种新的方式对外部环境作出反应的一个过程。在分类与预测中, 人工神将网络主要使用有指导的学习方式,即根据给定的训练样本,调整人工神经网络的参 数以使网络输出接近于已知的样本类标记或其他形式的因变量。
代码:
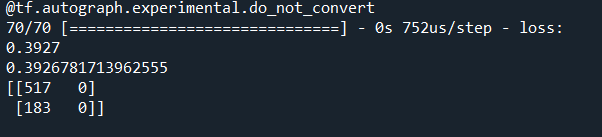
#神经网络预测 import pandas as pd import numpy as np # 参数初始化 filename=r'data\bankloan.xls' data=pd.read_excel(filename) x=data.iloc[:,:8].values y=data.iloc[:,8].values # 获取二分类数据 from keras.models import Sequential from keras.layers.core import Dense, Activation model = Sequential() # 建立模型 model.add(Dense(input_dim = 8, units = 10)) model.add(Activation('relu')) # 用relu函数作为激活函数,能够大幅提供准确度 model.add(Dense(input_dim = 18, units = 1)) model.add(Activation('sigmoid')) # 由于是0-1输出,用sigmoid函数作为激活函数 model.compile(loss = 'binary_crossentropy', optimizer = 'adam') # 编译模型。由于我们做的是二元分类,所以我们指定损失函数为binary_crossentropy,以及模式为binary # 另外常见的损失函数还有mean_squared_error、categorical_crossentropy等,请阅读帮助文件。 # 求解方法我们指定用adam,还有sgd、rmsprop等可选 model.fit(x, y, epochs = 1000, batch_size = 10) # 训练模型,学习一千次 predict_x=model.predict(x) classes_x=np.argmax(predict_x,axis=1) score = model.evaluate(x,y,batch_size=10) # 模型评估 print(score) from cm_plot import * #导入自行编写的混淆矩阵可视化函数 cm_plot(y,classes_x).show() #显示混淆矩阵可视化结果
运行结果:
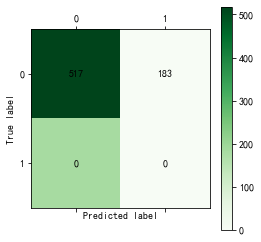
三、聚类分析算法
聚类分析仅根据样本数据本身将样本分组。其目标是实现组内的对象相互之间是相似的 (相关的),而不同组中的对象是不同的(不相关的)。组内的相似性越大,组间差别越大,聚类效果就越好。
(一)聚类结果可视化的工具——TSNE
TSNE 是 Laurens van der Maaten 和 Geoffrey Hintton 在 2008 年提出的,它的定位是高维 数据的可视化。我们总喜欢能够直观地展示研究结果,聚类也不例外。然而,通常来说输入 的特征数是高维的(大于3维),一般难以直接以原特征对聚类结果进行展示。而TSNE提供 了一种有效的数据降维方式,让我们可以在2维或者3维的空间中展示聚类结果。
代码:
#用TSNE进行数据降维并展示聚类结果 import pandas as pd #参数初始化 inputfile = r'data\bankloan.xls' #销量及其他属性数据 outputfile = 'data_type.xls' #保存结果的文件名 k = 3 #聚类的类别 iteration = 500 #聚类最大循环次数 data = pd.read_excel(inputfile, index_col = '年龄') #读取数据 data_zs = 1.0*(data - data.mean())/data.std() #数据标准化 if __name__ == '__main__': from sklearn.cluster import KMeans model = KMeans(n_clusters = k, n_jobs = 4, max_iter = iteration) #分为k类,并发数4 model.fit(data_zs) #开始聚类 #简单打印结果 r1 = pd.Series(model.labels_).value_counts() #统计各个类别的数目 r2 = pd.DataFrame(model.cluster_centers_) #找出聚类中心 r = pd.concat([r2, r1], axis = 1) #横向连接(0是纵向),得到聚类中心对应的类别下的数目 r.columns = list(data.columns) + [u'类别数目'] #重命名表头 print(r) #详细输出原始数据及其类别 r = pd.concat([data, pd.Series(model.labels_, index = data.index)], axis = 1) #详细输出每个样本对应的类别 r.columns = list(data.columns) + [u'聚类类别'] #重命名表头 r.to_excel(outputfile) #保存结果 # 用TSNE进行数据降维并展示聚类结果 from sklearn.manifold import TSNE tsne = TSNE() tsne.fit_transform(data_zs) #进行数据降维 tsne = pd.DataFrame(tsne.embedding_, index = data_zs.index) #转换数据格式 import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号 #不同类别用不同颜色和样式绘图 d = tsne[r[u'聚类类别'] == 0] plt.plot(d[0], d[1], 'r.') d = tsne[r[u'聚类类别'] == 1] plt.plot(d[0], d[1], 'go') d = tsne[r[u'聚类类别'] == 2] plt.plot(d[0], d[1], 'b*') plt.show()
运行结果:
