1、字符编码
#ASCII码里只能存英文和特殊字符 不能存中文 存英文占1个字节 8位
#中文编码为GBK 操作系统编码也为GBK
#为了统一存储中文和英文和其他语言文字出现了万国码Unicode 所有一个字符都占2个字节 16位
#英文文档改为Unicode编码大小变大一倍 为解决这种浪费空间问题
#出现了Unicode扩展集 Utf-8 为可变长的字符编码 默认英文字符按ASCII码存储 中文按照3个字节存储

编码都要先decode成unicode再转码成目标编码

#获取默认编码
import sys
print(sys.getdefaultencoding())
#文件头声明编码
#-*- coding:gbk -*-
#文件转码都要先转换成Unicode再转换成目标编码
#转换成Unicode时需要decode("自身编码") 并且传入自身编码即可以转换成unicode
#再转换成目标编码时 要encode("目标编码")
#ptyon3里 encode的时候不仅转换了编码 还变成了bits
s="你好"
#转换成gbk编码
s_gbk=s.encode("gbk")
print(s_gbk)
#gbk转换成utf-8
s_utf8=s_gbk.decode("gbk").encode("utf-8")
print(s_utf8)
#utf-8转换为gb2312
s_gb2312=s.encode("gb2312")
print(s_gb2312)
#gb2312转换为gbk
s_gbk2=s_gb2312.decode("gb2312").encode("gbk")
print(s_gbk2)
#gb2312转换为utf-8
s_utf8_2=s_gb2312.decode("gb2312").encode()
print(s_utf8_2)
print(s.encode("utf-8").decode("utf-8").encode("gb2312").decode("gb2312"))
#gbk向下兼容gb2312和gb23180
2、函数
1)函数定义
#定义函数的方法
def test(x):
'''the fuction definition'''
x=1
return x
def 定义函数关键字
test 函数名
() 内可定义形参
"" 文档描述(非必要,但是强烈建议为你的函数添加描述信息)
x=x+1 泛指代码块或程序处理逻辑
return 定义返回值
2)函数和过程的区别
#面向对象 --> 类--> class
#面向对象 -->过程 --> def
#函数式编程-->函数-->def
#定义函数 有返回值
def fun1():
print("in the fun1")
return 0
#定义过程 没有返回值 程序默认返回None
def fun2():
'''test1'''
print("in the fun2")
x=fun1()
y=fun2()
print("from func1 return is %s" % x)
print("from func2 return is %s" % y)
3) 返回值
#函数返回值 是整个函数执行的结果 可以是任意值
#数字 字符 列表 字典 方法
# 返回None
def test1():
print("test1")
#返回 0
def test2():
print("test2")
return 0
#返回 1,"123",[1,2,3],{"11":"22","33":"44"}
def test3():
print("test3")
return 1,"123",[1,2,3],{"11":"22","33":"44"}
#返回方法
def test4():
print("test4")
return test1()
4)函数参数及调用
形参:往方法里传入的参数 位置参数
实参:实际存在于内存空间的
形参与实参一一对应
def test(x,y): #x,y形参
print(x)
print(y)
test(1,2) #1,2 实参数
#位置参数调用:按顺序匹配形参和实参
test(1,2)
#关键字调用: 指定形参和实参的对应关系,与形参顺序无关
test(y=1,x=2)
#Error 位置参数调用不能和关键字调用混合调用
#混合用会按照位置参数来
#test(x=2,4)
#OK 关键字参数一定要在位置参数后
test(3,y=4)
#默认参数 :定义方法的时候给形参一个默认值
#特点:调用的时候 默认参数非必传
#用途:
def test1(x,y=2):
print(x)
print(y)
test1(1)
test1(2,3)
#参数组(*args) 可接收多个位置参数转换为元组
#*表示个数不固定 args为形参数名
def test(*args):
print(args)
test(1,2,3)
test("111")
#输出 (1, 2, 3, 4, 5)
test(*[1,2,3,4,5])
#输出([1, 2, 3, 4, 5],)
test([1,2,3,4,5])
def test1(x,*args):
print(x)
print(args)
test1(1,2,3,4,5)
#接收字典 **kwargs 接收多个关键字参数转化为字典
def test3(**kwargs):
print(kwargs)
print(kwargs["name"])
print(kwargs["age"])
#输出 {'name': '111', 'age': '20'}
test3(name='111',age='20',title="it")
test3(**{"name":"22","age":"18"})
#可扩展参数方法
def test4(name,age=18,*args,**kwargs):
print(name)
print(age)
print(args)
print(kwargs)
# test4("anne",age="18",sex="m")
# test4("lily",sex="f")
#不能写test4("alex",age=20,30,40,hobby="llll")
test4("alex",20,30,40,hobby="llll")
5)局部变量与作用域
#在子程序中定义的变量为局部变量, 在程序一开始定义的变量为全局变量
#全局变量的作用域是整个程序,局部变量的作用域是定义该变量的子程序
#当全局变量与局部变量同名时
#在定义局部变量的子程序内,局部变量起作用。在其他地方全局变量起作用
#局部变量:name 只在方法change_name里生效
#change_name就是name的作用域
def change_name(name):
print("befor change %s " % name)
name="Alex"
print("after change %s " % name)
name="alex"
change_name(name)
print(name)
#全局变量:在文件顶级定义的变量
#全局变量:数字、字符串、元组在函数里是改不了 。其他都可以改
#如果一定要在方法里改 在用之前加上golbal 也是可以改的
school="Oldboy edu."
def test1():
global school #可以改了
school="alex"
print(school)
test1()
print(school)
names=["Anne","Joe","Sue"]
def test2():
names[0]="Anne1"
print(names)
test2()
6)递归
在函数内部,可以调用其他函数。如果一个函数在内部调用自己本身,这个函数就是递归函数。
递归特性:
1.必须有一个明确的结束条件
2.每次更深入一层递归时,问题规模相比上次递归都应有所减少
3.递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过我,会导致栈溢出)
#递归例子
def calc(n):
print(n)
if int(n/2)>0:
return calc(int(n/2))
else:
return n
calc(10)
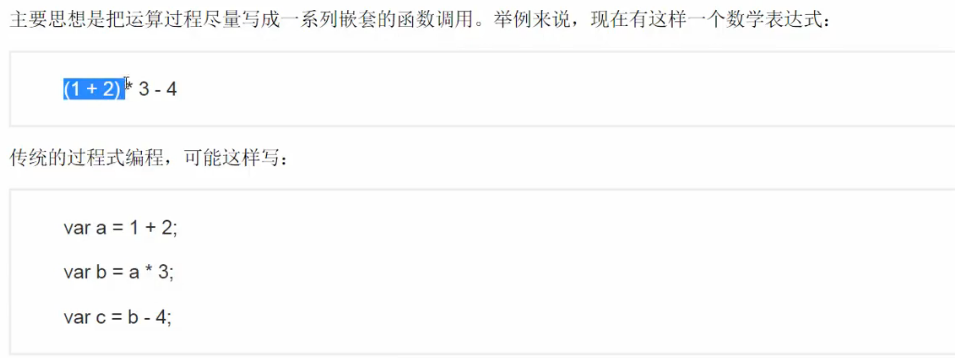
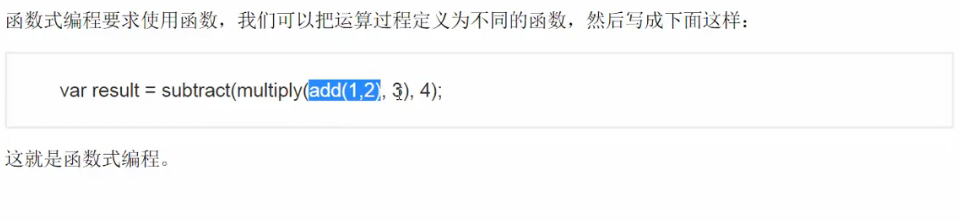
7) 函数式编程
8)高阶函数
变量可以指向函数,函数的参数能接收变量,那么一个函数就能接收另一个函数作为参数,这种函数就称之为高阶函数。
#高阶函数例子
def add(a,b,f):
return f(a)+f(b)
#abs 内置函数 求绝对值
print(add(3,-6,abs))