关于带权并查集,到目前为止,基本上可以分为两类,一种是点权,另一种是边权,顾名思义,就是把权重加在点上或者边上。
1 点权。点权并查集的操作是在unite中操作的,在并查集中我们想要维护的值一般都在根上,比如说要维护一树上的最大值。
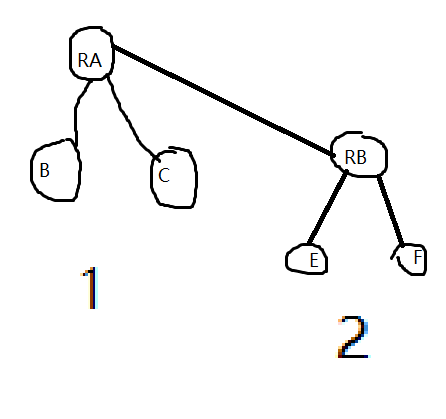
因为我们维护的最大值信息都在跟上,左边那颗树根RA保存了树1的最大值,RB保存了树2的最大值,所以合并的时候我们只要考虑RA和RB的关系就可以了,即谁大让谁做父节点。(掺杂了一点dp的思想...)
code:
ll find(ll x){
return fa[x]==x? x:fa[x]=find(fa[x]);
}
void unite(ll x,ll y){
ll fx=find(x);
ll fy=find(y);
if(val[fx]>val[fy]) fa[fy]=fx;
else fa[fx]=fy;
}
2 边权。边权并查集一般用来维护点与点之间的关系,是针对两点而言的。
首先看find函数,因为在find函数中,我们常常用到压缩路径的操作,在压缩路径的过程中会破坏边与边之间本来的关系。如果不加修改的话,显然是不行的。
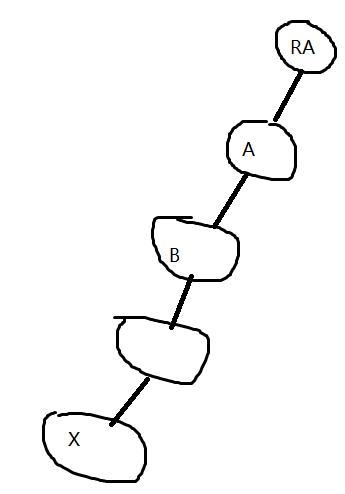
假如一颗树是这样的,我们要维护树的边权和,我们采用路径压缩,首先从x开始,一直往上走,直到走到RA,返会了RA,所以我们的int c=find(pre[x]),find(pre[x])返回的始终是RA。用一个数组sum[x]来记录x与其父节点之间的关系,sum[A]=sum[A]+sum[RA]。然后继续回溯,回溯到B处,把B链接到RA上,
那么sum[B]=sum[B]+sum[pre[B]]。就是B到其父节点和其父节点到B的爷爷节点上的值,而B到其爷爷节点的值我们已经处理过了,已经变成了pre[B]到祖先节点了,所以sum[B]的值就是B到祖先节点的值。
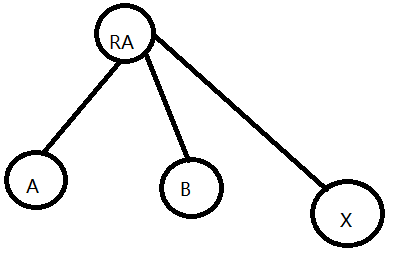
sum[x]也变成了到x和RA的关系
最终修改成了这个样子:
我们在来看一下合并操作
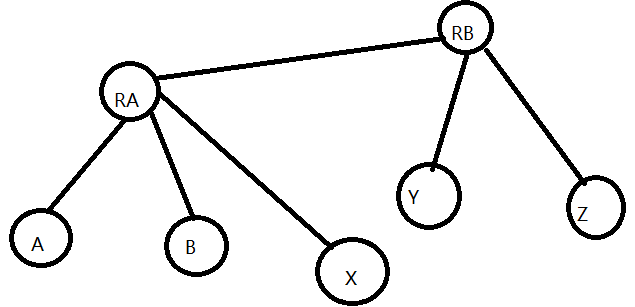
假设需要在x和y之间建立一个关系z。如果说让RB做RA的父节点,我们设RA和RB之间的关系为W,那么从x到RB有两条路径分别为X->RA->RB,x->y->RB。
这俩距离应该相等,所以sum[x]+w=z+sum[y]所以w=sum[y]-sum[x]+z。
code:
ll find(ll x){
if(fa[x]==x) return x;
else {
int c=find(fa[x]);
sum[x]=sum[x]+sum[fa[x]];
return fa[x]=c;
}
}
void unite(ll x,ll y,ll z){
ll fx=find(x);
ll fy=find(y);
fa[fx]=fy;
sum[fx]=sum[y]-sum[x]+z;
}
(如果哪里看不懂可以留言,做笔记的同时希望可以帮助到你...)