ThreadLocal和ThreadLocalMap源码分析
@
背景分析
相信很多程序猿在平常实现功能的过程当中,都会遇到想要某些静态变量,不管是单线程亦或者是多线程在使用,都不会产生相互之间的影响,也就是这个静态变量在线程之间是读写隔离的。
有一个我们经常使用的工具类,它的并发问题就是用ThreadLocal来解决的,我相信大多数人都看过,那就是SimpleDateFormat日期格式化的工具类的多线程问题,大家去网上搜的话,应该会有一堆人都说使用ThreadLocal。
定义
那究竟何谓ThreadLocal呢?通过我们的Chinese English,我们也可以翻译出来,那就是线程本地的意思,而且我们是用来存放我们需要能够线程隔离的变量的,那就是线程本地变量。也就是说,当我们把变量保存在ThreadLocal当中时,就能够实现这个变量的线程隔离了。
例子
我们先来看两个例子,这里也刚好涉及到两个概念,分别是值传递和引用传递。
- 值传递
public class ThreadLocalTest {
private static ThreadLocal<Integer> threadLocal = new ThreadLocal<Integer>(){
protected Integer initialValue(){
return 0;
}
};
// 值传递
@Test
public void testValue(){
for (int i = 0; i < 5; i++){
new Thread(() -> {
Integer temp = threadLocal.get();
threadLocal.set(temp + 5);
System.out.println("current thread is " + Thread.currentThread().getName() + " num is " + threadLocal.get());
}, "thread-" + i).start();
}
}
}
以上程序的输出结果是:
current thread is thread-1 num is 5
current thread is thread-3 num is 5
current thread is thread-0 num is 5
current thread is thread-4 num is 5
current thread is thread-2 num is 5
我们可以看到,每一个线程打印出来的都是5,哪怕我是先通过ThreadLocal.get()方法获取变量,然后再set进去,依然不会进行重复叠加。
这就是线程隔离。
但是对于引用传递来说,我们又需要多注意一下了,直接上例子看看。
- 引用传递
public class ThreadLocalTest {
static NumIndex numIndex = new NumIndex();
private static ThreadLocal<NumIndex> threadLocal1 = new ThreadLocal<NumIndex>(){
protected NumIndex initialValue(){
return numIndex;
}
};
static class NumIndex{
int num = 0;
public void increment(){
num++;
}
}
// 引用传递
@Test
public void testReference(){
for (int i = 0; i < 5; i++){
new Thread(() -> {
NumIndex index = threadLocal1.get();
index.increment();
threadLocal1.set(index);
System.out.println("current thread is " + Thread.currentThread().getName() + " num is " + threadLocal1.get().num);
}, "thread-" + i).start();
}
}
}
我们看看运行的结果
current thread is thread-0 num is 2
current thread is thread-2 num is 3
current thread is thread-1 num is 2
current thread is thread-4 num is 5
current thread is thread-3 num is 4
我们看到值不但没有被隔离,而且还出现了线程安全的问题。
所以我们一定要注意值传递和引用传递的区别,在这里也不讲这两个概念了。
源码分析
想要更加深入地了解ThreadLocal这个东西的作用,最后还是得回到撸源码,看看Josh Bloch and Doug Lea这两位大神究竟是怎么实现的?整个类加起来也不过七八百行而已。
在这里,我分开两部分来说,分别是ThreadLocal和ThreadLocalMap这两个的源码分析。
ThreadLocalMap源码分析
思而再三,最后还是决定先讲ThreadLocalMap的源码解析,为什么呢?
ThreadLocalMap是ThreadLocal里面的一个静态内部类,但是确实一个很关键的东西,我们既然是在看源码并且想要弄懂这个东西,那我们就一定要有一种思维,那就是如果是我们要实现这么个功能,我们要怎么做?以及看到别人的代码,要学会思考别人为什么要这么做?
我希望通过我的文章,不求能够带给你什么牛逼的技术,但是至少能让你明白,我们需要学习的是这些大牛的严谨的思维逻辑。
言归正传,ThreadLocalMap究竟是什么?我们要这么想,既然是线程本地变量,而且我们可以通过get和set方法能够获取和赋值。
1、那我们赋值的内容,究竟保存在什么结构当中?
2、它究竟是怎么做到线程隔离的?
3、当我get和set的时候,它究竟是怎么做到线程-value的对应关系进行保存的?
通过以上三个问题,再结合ThreadLocalMap这个名字,我想大家也知道这个是什么了。
没错,它就是ThreadLocal非常核心的内容,是维护我们线程与变量之间关系的一个类,看到是Map结尾,那我们也能够知道它实际上就是一个键值对。至于KEY是什么,我们会在源码分析当中看出来。
Entry内部类
以下源码都是抽取讲解部分的内容来展示
static class ThreadLocalMap {
/**
* 自定义一个Entry类,并继承自弱引用
* 用来保存ThreadLocal和Value之间的对应关系
*
* 之所以用弱引用,是为了解决线程与ThreadLocal之间的强绑定关系
* 会导致如果线程没有被回收,则GC便一直无法回收这部分内容
*/
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
/**
* The initial capacity -- MUST be a power of two.
* Entry数组的初始化大小
*/
private static final int INITIAL_CAPACITY = 16;
/**
* The table, resized as necessary.
* table.length MUST always be a power of two.
* <ThreadLocal, 保存的泛型值>数组
* 长度必须是2的N次幂
* 这个可以参考为什么HashMap里维护的数组也必须是2的N次幂
* 主要是为了减少碰撞,能够让保存的元素尽量的分散
* 关键代码还是hashcode & table.length - 1
*/
private Entry[] table;
/**
* The number of entries in the table.
* table里的元素个数
*/
private int size = 0;
/**
* The next size value at which to resize.
* 扩容的阈值
*/
private int threshold; // Default to 0
/**
* Set the resize threshold to maintain at worst a 2/3 load factor.
* 根据长度计算扩容的阈值
*/
private void setThreshold(int len) {
threshold = len * 2 / 3;
}
/**
* 通过以下两个获取next和prev的代码可以看出,entry数组实际上是一个环形结构
*/
/**
* Increment i modulo len.
* 获取下一个索引,超出长度则返回0
*/
private static int nextIndex(int i, int len) {
return ((i + 1 < len) ? i + 1 : 0);
}
/**
* Decrement i modulo len.
* 返回上一个索引,如果-1为负数,返回长度-1的索引
*/
private static int prevIndex(int i, int len) {
return ((i - 1 >= 0) ? i - 1 : len - 1);
}
/**
* 构造参数创建一个ThreadLocalMap代码
* ThreadLocal为key,我们的泛型为value
*/
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
// 初始化table的大小为16
table = new Entry[INITIAL_CAPACITY];
// 通过hashcode & (长度-1)的位运算,确定键值对的位置
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
// 创建一个新节点保存在table当中
table[i] = new Entry(firstKey, firstValue);
// 设置table内元素为1
size = 1;
// 设置扩容阈值
setThreshold(INITIAL_CAPACITY);
}
/**
* ThreadLocal本身是线程隔离的,按道理是不会出现数据共享和传递的行为的
* 这是InheritableThreadLocal提供了了一种父子间数据共享的机制
* @param parentMap the map associated with parent thread.
*/
private ThreadLocalMap(ThreadLocalMap parentMap) {
Entry[] parentTable = parentMap.table;
int len = parentTable.length;
setThreshold(len);
table = new Entry[len];
for (int j = 0; j < len; j++) {
Entry e = parentTable[j];
if (e != null) {
@SuppressWarnings("unchecked")
ThreadLocal<Object> key = (ThreadLocal<Object>) e.get();
if (key != null) {
Object value = key.childValue(e.value);
Entry c = new Entry(key, value);
int h = key.threadLocalHashCode & (len - 1);
while (table[h] != null)
h = nextIndex(h, len);
table[h] = c;
size++;
}
}
}
}
}
一些简单的东西直接看我上面的注释就可以了。
我们可以看到,在ThreadLocalMap这个内部类当中,又定义了一个Entry内部类,并且继承自弱引用,泛型是ThreadLocal,其中有一个构造方法,通过这个我们就大致可以猜出,ThreadLocalMap当中的key实际上就是当前ThreadLocal对象。
至于为什么要用弱引用呢?我想我源码上面的注释其实也写得很明白了,这ThreadLocal实际上就是个线程本地变量隔离作用的工具类而已,当线程走完了,肯定希望能回收这部分产生的资源,所以就用了弱引用。
我相信有人会有疑问,如果在我要用的时候,被回收了怎么办?下面的代码会一步步地让你明白,你考虑到的问题,这些大牛都已经想到并且解决了。接着往下学吧!
getEntry和getEntryAfterMiss方法
通过方法名我们就能看得出是从ThreadLocal对应的ThreadLocalMap当中获取Entry节点,在这我们就要思考了。
1)我们要通过什么获取对应的Entry
2)我们通过上面知道使用了弱引用,如果被GC回收了没有获取到怎么办?
3)不在通过计算得到的下标上,又要怎么办?
4)如果ThreadLocal对应的ThreadLocalMap不存在要怎么办?
以上这4个问题是我自己在看源码的时候能够想到的东西,有些问题的答案光看THreadLocalMap的源码是看不出所以然的,需要结合之后的ThreadLocal源码分析。
在这我们来看看大牛的源码是怎么解决以上问题的吧。
/**
* 获取ThreadLocal的索引位置,通过下标索引获取内容
*/
private Entry getEntry(ThreadLocal<?> key) {
// 通过hashcode确定下标
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
// 如果找到则直接返回
if (e != null && e.get() == key)
return e;
else
// 找不到的话接着从i位置开始向后遍历,基于线性探测法,是有可能在i之后的位置找到的
return getEntryAfterMiss(key, i, e);
}
private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) {
Entry[] tab = table;
int len = tab.length;
// 循环向后遍历
while (e != null) {
// 获取节点对应的k
ThreadLocal<?> k = e.get();
// 相等则返回
if (k == key)
return e;
// 如果为null,触发一次连续段清理
if (k == null)
expungeStaleEntry(i);
// 获取下一个下标接着进行判断
else
i = nextIndex(i, len);
e = tab[i];
}
return null;
}
一看这两个方法名,我们就知道这两个方法就是获取Entry节点的方法。
我们首先看getEntry(ThreadLocal<?> key)和getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e)这个方法就看出来了,直接根据ThreadLocal对象来获取,所以我们可以再次证明,key就是ThreadLocal对象,我们来看看它的流程
1、首先根据key的hashcode & table.length - 1来确定在table当中的下标
2、如果获取到直接返回,没获取到的话,就接着往后遍历看是否能获取到(因为用的是线性探测法,往后遍历有可能获取到结果)
3、进入了getEntryAfterMiss方法进行线性探测,如果获取到则直接返回;获取的key为null,则触发一次连续段清理(实际上在很多方法当中都会触发该方法,经常会进行连续段清理,这是ThreadLocal核心的清理方法)。
expungeStaleEntry方法
这可以说是ThreadLocal非常核心的一个清理方法,为什么会需要清理呢?或许很多人想不明白,我们用List或者是Map也好,都没有说要清理里面的内容。
但是这里是对于线程来说的隔离的本地变量,并且使用的是弱引用,那便有可能在GC的时候就被回收了。
1)如果有很多Entry节点已经被回收了,但是在table数组中还留着位置,这时候不清理就会浪费资源
2)在清理节点的同时,可以将后续非空的Entry节点重新计算下标进行排放,这样子在get的时候就能快速定位资源,加快效率。
我们来看看别人源码是怎么做的吧!
/**
* 这个函数可以看做是ThreadLocal里的核心清理函数,它主要做的事情就是
* 1、从staleSlot开始,向后遍历将ThreadLocal对象被回收所在Entry节点的value和Entry节点本身设置null,方便GC,并且size自减1
* 2、并且会对非null的Entry节点进行rehash,只要不是在当前位置,就会将Entry挪到下一个为null的位置上
* 所以实际上是对从staleSlot开始做一个连续段的清理和rehash操作
*/
private int expungeStaleEntry(int staleSlot) {
// 新的引用指向table
Entry[] tab = table;
// 获取长度
int len = tab.length;
// expunge entry at staleSlot
// 先将传过来的下标置null
tab[staleSlot].value = null;
tab[staleSlot] = null;
// table的size-1
size--;
// Rehash until we encounter null
Entry e;
int i;
// 遍历删除指定节点所有后续节点当中,ThreadLocal被回收的节点
for (i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
// 获取entry当中的key
ThreadLocal<?> k = e.get();
// 如果ThreadLocal为null,则将value以及数组下标所在位置设置null,方便GC
// 并且size-1
if (k == null) {
e.value = null;
tab[i] = null;
size--;
} else { // 如果不为null
// 重新计算key的下标
int h = k.threadLocalHashCode & (len - 1);
// 如果是当前位置则遍历下一个
// 不是当前位置,则重新从i开始找到下一个为null的坐标进行赋值
if (h != i) {
tab[i] = null;
// Unlike Knuth 6.4 Algorithm R, we must scan until
// null because multiple entries could have been stale.
while (tab[h] != null)
h = nextIndex(h, len);
tab[h] = e;
}
}
}
return i;
}
上面的代码注释我相信已经是写的很清楚了,这个方法实际上就是从staleSlot开始做一个连续段的清理和rehash操作。
set方法系列
接下来我们看看set方法,自然就是要将我们的变量保存进ThreadLocal当中,实际上就是保存到ThreadLocalMap当中去,在这里我们一样要思考几个问题。
1)如果该ThreadLocal对应的ThreadLocalMap还不存在,要怎么处理?
2)如果所计算的下标,在table当中已经存在Entry节点了怎么办?
我想通过上面部分代码的讲解,对这两个问题,大家也都比较有思路了吧。
老规矩,接下来看看代码实现
/**
* ThreadLocalMap的set方法,这个方法还是挺关键的
* 通过这个方法,我们可以看出该哈希表是用线性探测法来解决冲突的
*/
private void set(ThreadLocal<?> key, Object value) {
// 新开一个引用指向table
Entry[] tab = table;
// 获取table的长度
int len = tab.length;
// 获取对应ThreadLocal在table当中的下标
int i = key.threadLocalHashCode & (len-1);
/**
* 从该下标开始循环遍历
* 1、如遇相同key,则直接替换value
* 2、如果该key已经被回收失效,则替换该失效的key
*/
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
if (k == key) {
e.value = value;
return;
}
// 如果 k 为null,则替换当前失效的k所在Entry节点
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
// 找到空的位置,创建Entry对象并插入
tab[i] = new Entry(key, value);
// table内元素size自增
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
private void replaceStaleEntry(ThreadLocal<?> key, Object value,
int staleSlot) {
// 新开一个引用指向table
Entry[] tab = table;
// 获取table的长度
int len = tab.length;
Entry e;
// 记录当前失效的节点下标
int slotToExpunge = staleSlot;
/**
* 通过这个for循环的prevIndex(staleSlot, len)可以看出
* 这是由staleSlot下标开始向前扫描
* 查找并记录最前位置value为null的下标
*/
for (int i = prevIndex(staleSlot, len);
(e = tab[i]) != null;
i = prevIndex(i, len))
if (e.get() == null)
slotToExpunge = i;
/**
* 通过for循环nextIndex(staleSlot, len)可以看出
* 这是由staleSlot下标开始向后扫描
*/
for (int i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
// 获取Entry节点对应的ThreadLocal对象
ThreadLocal<?> k = e.get();
/**
* 如果与新的key对应,直接赋值value
* 则直接替换i与staleSlot两个下标
*/
if (k == key) {
e.value = value;
tab[i] = tab[staleSlot];
tab[staleSlot] = e;
// Start expunge at preceding stale entry if it exists
// 通过注释看出,i之前的节点里,没有value为null的情况
if (slotToExpunge == staleSlot)
slotToExpunge = i;
/**
* 在调用cleanSomeSlots进行启发式清理之前
* 会先调用expungeStaleEntry方法从slotToExpunge到table下标所在为null的连续段进行一次清理
* 返回值便是table[]为null的下标
* 然后以该下标--len进行一次启发式清理
* 最终里面的方法实际上还是调用了expungeStaleEntry
* 可以看出expungeStaleEntry方法是ThreadLocal核心的清理函数
*/
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
return;
}
/**
* 如果当前下标所在已经失效,并且向后扫描过程当中没有找到失效的Entry节点
* 则slotToExpunge赋值为当前位置
*/
if (k == null && slotToExpunge == staleSlot)
slotToExpunge = i;
}
// If key not found, put new entry in stale slot
// 如果并没有在table当中找到该key,则直接在当前位置new一个Entry
tab[staleSlot].value = null;
tab[staleSlot] = new Entry(key, value);
/**
* 在上面的for循环探测过程当中
* 如果发现任何无效的Entry节点,则slotToExpunge会被重新赋值
* 就会触发连续段清理和启发式清理
*/
if (slotToExpunge != staleSlot)
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
}
/**
* 启发式地清理被回收的Entry
* i对应的Entry是非无效的,有可能是失效被回收了,也有可能是null
* 会有两个地方调用到这个方法
* 1、set方法,在判断是否需要resize之前,会清理并rehash一遍
* 2、替换失效的节点时候,也会进行一次清理
*/
private boolean cleanSomeSlots(int i, int n) {
boolean removed = false;
Entry[] tab = table;
int len = tab.length;
do {
i = nextIndex(i, len);
Entry e = tab[i];
// Entry对象不为空,但是ThreadLocal这个key已经为null
if (e != null && e.get() == null) {
n = len;
removed = true;
/**
* 调用该方法进行回收
* 实际上不是只回收 i 这一个节点而已
* 而是对 i 开始到table所在下标为null的范围内,对那些节点都进行一次清理和rehash
*/
i = expungeStaleEntry(i);
}
} while ( (n >>>= 1) != 0);
return removed;
}
/**
* 对table进行扩容,因为要保证table的长度是2的幂,所以扩容就扩大2倍
*/
private void resize() {
// 获取旧table的长度,并且创建一个长度为旧长度2倍的Entry数组
Entry[] oldTab = table;
int oldLen = oldTab.length;
int newLen = oldLen * 2;
Entry[] newTab = new Entry[newLen];
// 记录插入的有效Entry节点数
int count = 0;
/**
* 从下标0开始,逐个向后遍历插入到新的table当中
* 1、如遇到key已经为null,则value设置null,方便GC回收
* 2、通过hashcode & len - 1计算下标,如果该位置已经有Entry数组,则通过线性探测向后探测插入
*/
for (int j = 0; j < oldLen; ++j) {
Entry e = oldTab[j];
if (e != null) {
ThreadLocal<?> k = e.get();
if (k == null) {
e.value = null; // Help the GC
} else {
int h = k.threadLocalHashCode & (newLen - 1);
while (newTab[h] != null)
h = nextIndex(h, newLen);
newTab[h] = e;
count++;
}
}
}
// 重新设置扩容的阈值
setThreshold(newLen);
// 更新size
size = count;
// 指向新的Entry数组
table = newTab;
}
以上的代码就是调用set方法往ThreadLocalMap当中保存K-V关系的一系列代码,我就不分开再一个个讲了,这样大家看起来估计也比较方便,有连续性。
我们可以来看看一整个的set流程:
1、先通过hashcode & (len - 1)来定位该ThreadLocal在table当中的下标
2、for循环向后遍历
1)如果获取Entry节点的key与我们需要操作的ThreadLocal相等,则直接替换value
2)如果遍历的时候拿到了key为null的情况,则调用replaceStaleEntry方法进行与之替换。
3、如果上述两个情况都是,则直接在计算的出来的下标当中new一个Entry阶段插入。
4、进行一次启发式地清理并且如果插入节点后的size大于扩容的阈值,则调用resize方法进行扩容。
remove方法
既然是Map形式进行存储,我们有put方法,那肯定就会有remove的时候,任何一种数据结构,肯定都得符合增删改查的。
我们直接来看看代码。
/**
* Remove the entry for key.
* 将ThreadLocal对象对应的Entry节点从table当中删除
*/
private void remove(ThreadLocal<?> key) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
if (e.get() == key) {
// 将引用设置null,方便GC
e.clear();
// 从该位置开始进行一次连续段清理
expungeStaleEntry(i);
return;
}
}
}
我们可以看到,remove节点的时候,也会使用线性探测的方式,当找到对应key的时候,就会调用clear将引用指向null,并且会触发一次连续段清理。
我相信通过以上对ThreadLocalMap的源码分析,已经让大家对其有了个基本的概念认识,相信对大家理解ThreadLocal这个概念的时候,已经不是停留在知道它就是为了实现线程本地变量而已了。
那接下来我们来看看ThreadLocal的源码分析吧。
ThreadLocal源码分析
ThreadLocal的源码相对于来说就简单很多了,因为主要都是ThreadLocalMap这个内部类在干活,在管理我们的本地变量。
get方法系列
/**
* 获取当前线程本地变量的值
*/
public T get() {
// 获取当前线程
Thread t = Thread.currentThread();
// 获取当前线程对应的ThreadLocalMap
ThreadLocalMap map = getMap(t);
// 如果map不为空
if (map != null) {
// 如果当前ThreadLocal对象对应的Entry还存在
ThreadLocalMap.Entry e = map.getEntry(this);
// 并且Entry不为null,返回对应的值,否则都执行setInitialValue方法
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
// 如果该线程对应的ThreadLocalMap还不存在,则执行初始化方法
return setInitialValue();
}
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
private T setInitialValue() {
// 获取初始值,一般是子类重写
T value = initialValue();
// 获取当前线程
Thread t = Thread.currentThread();
// 获取当前线程对应的ThreadLocalMap
ThreadLocalMap map = getMap(t);
// 如果map不为null
if (map != null)
// 调用ThreadLocalMap的set方法进行赋值
map.set(this, value);
// 否则创建个ThreadLocalMap进行赋值
else
createMap(t, value);
return value;
}
/**
* 构造参数创建一个ThreadLocalMap代码
* ThreadLocal为key,我们的泛型为value
*/
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
// 初始化table的大小为16
table = new Entry[INITIAL_CAPACITY];
// 通过hashcode & (长度-1)的位运算,确定键值对的位置
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
// 创建一个新节点保存在table当中
table[i] = new Entry(firstKey, firstValue);
// 设置table内元素为1
size = 1;
// 设置扩容阈值
setThreshold(INITIAL_CAPACITY);
}
ThreadLocal的get方法也不难,就几行代码,但是当它结合了ThreadLocalMap的方法后,这整个逻辑就值得我们深入研究写这个工具的人的思维了。
我们来看看它的一个流程吧。
1、获取当前线程,根据当前线程获取对应的ThreadLocalMap
2、在ThreadLocalMap当中获取该ThreadLocal对象对应的Entry节点,并且返回对应的值
3、如果获取到的ThreadLocalMap为null,则证明还没有初始化,就调用setInitialValue方法
1)在调用setInitialValue方法的时候,会双重保证,再进行获取一次ThreadLocalMap
2)如果依然为null,就最终调用ThreadLocalMap的构造方法
set方法系列
在这里我也不对ThreadLocal的set方法做太多介绍了,结合上面的ThreadLocalMap的set方法,我想就可以对上面每个方法思考出的问题有个大概的答案。
public void set(T value) {
// 获取当前线程
Thread t = Thread.currentThread();
// 获取线程所对应的ThreadLocalMap,从这可以看出每个线程都是独立的
ThreadLocalMap map = getMap(t);
// 如果map不为空,则k-v赋值,看出k是this,也就是当前ThreaLocal对象
if (map != null)
map.set(this, value);
// 如果获取的map为空,则创建一个并保存k-v关系
else
createMap(t, value);
}
其实ThreadLocal的set方法很简单的,最主要的都是调用了ThreadLocalMap的set方法,里面才是真正核心的执行流程。
不过我们照样来看看这个流程:
1、获取当前线程,根据当前线程获取对应的ThreadLocalMap
2、如果对应的ThreadLocalMap不为null,则调用其的set方法保存对应关系
3、如果map为null,就最终调用ThreadLocalMap的构造方法创建一个ThreadLocalMap并保存对应关系
执行流程总结
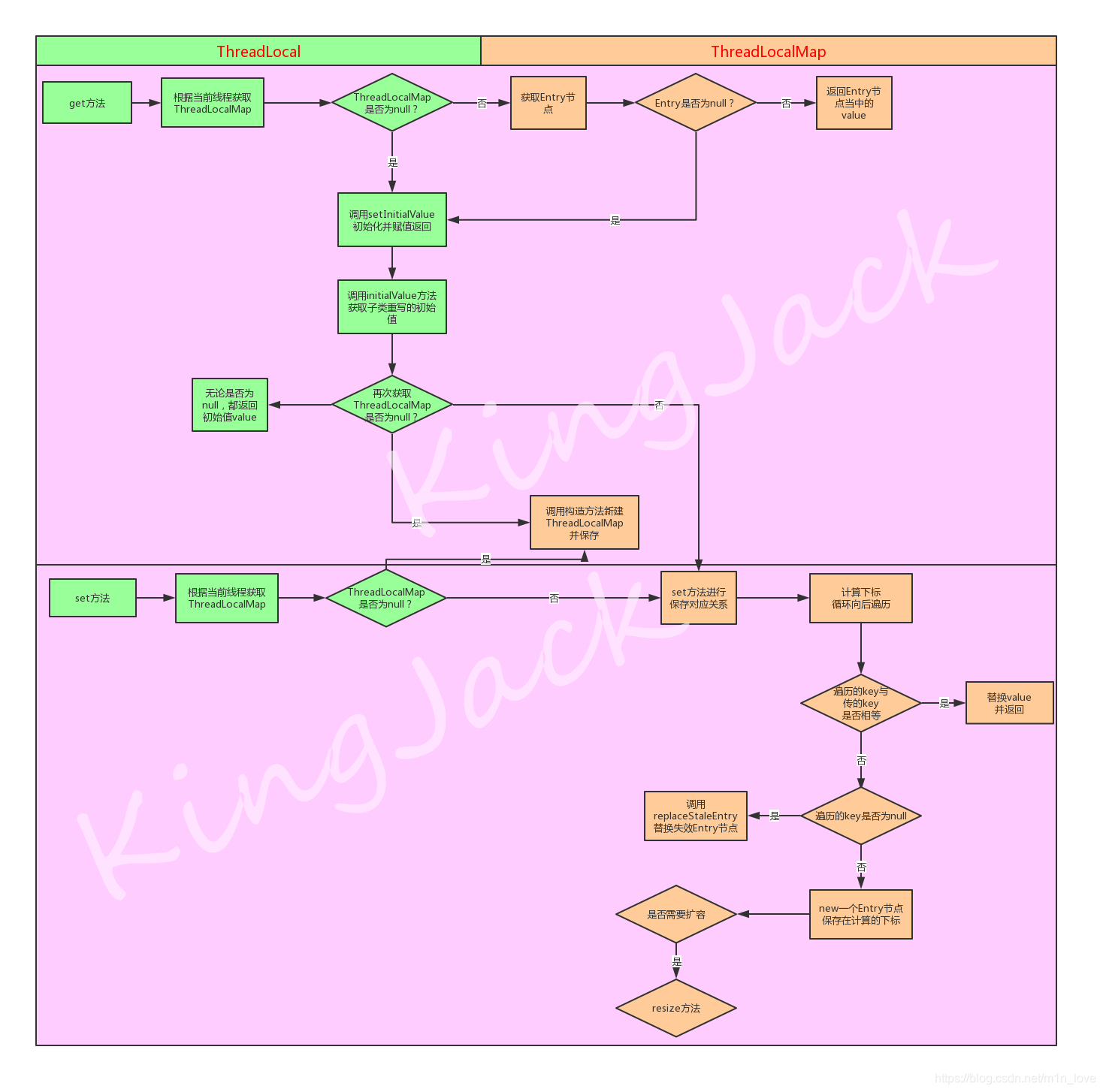
源码分析总结
上面通过对ThreadLocal和ThreadLocalMap两个类的源码进行了分析,我想对于ThreadLocal这个功能的一整个流程,大家都有了个比较清楚的了解了。我真的是很佩服Josh Bloch and Doug Lea这两位大神,他们在实现这个东西的时候,不是说光实现了就可以了,考虑了很多情况,例如:GC问题、如何维护好数据存储的问题以及线程与本地变量之间应该以何种方式建立对应关系。
他们写的代码逻辑非常之严谨,看到这区区几百行的代码,才真正地发现,我们其实主要不是在技术上与别人的差距,而是在功能实现的一整套思维逻辑上面就与他们有着巨大的差距,最明显的一点就是,我们单纯是为了实现而实现,基本上不会考虑其他异常情况,更加不会考虑到一些GC问题。
所以通过该篇源码的分析,让我真正地意识到,我们不能光是看源码做翻译而已,我们一定要学会他们是如何思考实现这么个功能,我们要学会他们思考每一个功能的逻辑。