一、Hibernate持久化类的编写规范
1.什么是持久化类
Hibernate是持久层的ORM影射框架,专注于数据的持久化工作。所谓持久化,就是将内存中的数据永久存储到关系型数据库中。那么知道了什么是持久化,什么又是持久化类呢?其实所谓的持久化类指的是一个Java类与数据库表建立了映射关系,那么这个类称为是持寺久化类。其实可以简单的理解为持久化类就是一个Java类有了一个映射文件与数据库的表建立了关系。那么我们在编写持久化类的时候有哪些要求呢?接下来我们来看一下:
- 持久化类需要提供无参数的构造方法。因为在 Hibernate的底层需要使用反射生成类的实例。
- 持久化类的属性需要私有,对私有的属性提供公有的get和set方法。因为在 Hibernate底层会将查询到的数据进行封装。
- 持久化类的属性要尽量使用包装类的类型。因为包装类和基本数据类型的默认值不同,包裝类的类型语义描述更清晰而基本数据类型不容易描述。
- 持久化类要有一个唯一标识OID与表的主键对应。因为 Hibernate中需要通过这个唯一标识OID区分在内存中是否是同一个持久化类。在Java中通过地址区分是否是同一个对象的,在关系型数据库的表中是通过主键区分是否同一条记录。那么 Hibernate就是通过这个OID来进行区分的。 Hibernate是不允许在内存中出现两个OID相同的持久化对象的。
- 持久化类尽量不要使用 final进行修饰。因为 Hibernate中有延迟加载的机制,这个机制中会产生代理对象,Hibernate产生代理对象使用的是字节码的增强技术完成的,其实就是产生了当前类的一个子类对象实现的。如果使用了 final修饰持久化类。那么就不能产生子类,从而就不会产生代理对象,那么 Hibernate的延迟加载策略(是一种优化手段)就会失效。
- 持久化类一般都实现序列化接口。
Tips: Bean:在软件开发中指的是可重用的组件。
JavaBean:指的是用java语言编写的可重用组件,在实际项目中,domain、service、dao都可以看成是JavaBean。
Tips: Hibernate中的对象标识符OID(Object Identifier)
Hibernate中把OID一直的对象,就认为是同一个对象,在同一个Session中不允许出现两个相同类型的对象的OID一致。
OID就是映射文件,对应数据库的 <id name="lkm_id"> <generator class="native"></generator> </id>
二、Hibernate主键生成策略
自然主键(业务主键):把具有业务含义的字段作为主键,称之为自然主键。例如在 customer表中,如果把name字段作为主键,其前提条件必须是:每一个客户的姓名不允许为null,不允许客户重名,并且不允许修改客户姓名。尽管这也是可行的,但是不能满足不断变化的业务需求,一旦出现了允许客户重名的业务需求,就必须修改数据模型,重新定义表的主键,这给数据库的维护增加了难度。
代理主键(逻辑主键):把不具备业务含义的字段作为主键,称之为代理主键。该字段一般取名为“ID”通常为整数类型,因为整数类型比字符串类型要节省更多的数据库空间。在上面例子中显然更合理的方式是使用代理主键。
|
名称 |
描述 |
|
increment |
(一般不用)用于long、short、int类型,由Hibernate自动以递增的方式生成唯一标识符,每次增量为1.只有当没有其它进程向同一张表中插入数据时才可以使用,不能在集群环境下使用。(先查询出当前最大值,在保存)适用于代理主键。 |
|
identity |
采用底层数据库本身提供的主键生成标识符,条件是数据库支持自动增长数据类型。在DB2、MySQL、MS SQL Server、Sybase和HypersonicSQL数据库中可以使用该生成器,该生成器要求在数据库中把主键定义为自增长类型。适用于代理主键。 |
|
sequence |
Hibernate根据底层数据库序列生成标识符。条件是数据库支持序列。适用于代理主键。(Oracle) |
|
native |
根据底层数据库对自动生成标识符的能力来选择identity、sequence、hilo(高低位算法:high low)三种生成器中的一种,适合跨数据库平台开发。适用于代理主键。 |
|
uuid |
Hibernate采用128位的UUID算法来生成标识符。该算法能够在网络环境中生成唯一的字符串标识符,其UUID被编码为一个长度为32位的十六进制字符串。这种策略并不流行,因为字符串类型的主键比整数类型的主键占用更多的数据库空间。适用于代理主键。 |
|
assigned |
由java程序负责生成标识符,如果不指定id元素的 generator属性,则默认使用该主键生成策略。适用于自然主键。 |
1.1瞬时态(临时态)
@Test public void test1(){ Customer ccustomer=new Customer(); //瞬时状态对象:没有持久化标识OID,没有被session管理 custoemr.setCust_name("Kevin"); Session s=HibernateUtil.openSession(); Transaction tx=s.beginTransaction(); s.save(customer); //持久态对象:有持久化标识OID,被session管理 tx.commit(); s.close(); System.out.println(customer); //托管态对象:有持久化标识OID,没有被session管理 }
3.Hibernate持久化对象三种状态转换
前面我们已经了解了持久化对象的三种状态,然后这三种状态是可以通过一系列方法互相进行转换的,下面来看持久化对象的状态演化图:
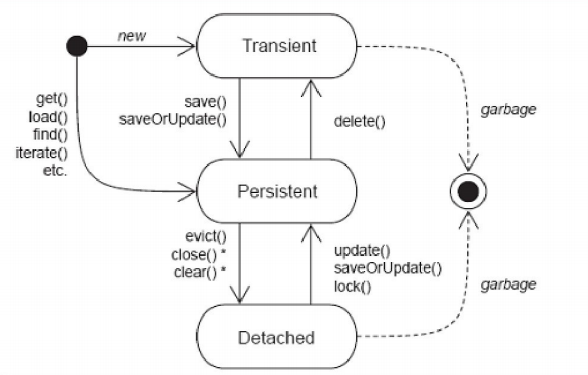
持久化对象的三种状态可以通过调用 Session中的一系列方法实现状态间的转换,具体如下:
3.1瞬时态转换到其他状态
通过前面学习可知,瞬时态的对象由new关键字创建,瞬时态对象转换到其他状态总结如下:
- 瞬时态转换为持久态:执行 Session的 save( )或 saveOrUpdate( )方法。
- 瞬时态转换为脱管态:为瞬时态对象设置持久化标识OID。
Customer customer= new Customer(); //瞬时态 customer.setCust_id(1); //托管态
持久化对象可以直接通过 Hibernate中 Session的get( )、 load( )方法,或者 Query查询从数据库中获得,持久态对象转换到其他状态总结如下:
- 持久态转换为瞬时态:执行 Session的 delete( )方法,需要注意的是被删除的持久化对象,不 建议再次使用。
- 持久态转换为脱管态:执行 Session的 evict( )、 close( )或 clear( )方法。 evict( )方法用于清除级缓存中某一个对象;close( )方法用于关闭 Session,清除一级缓存;clear( )方法用于清除级缓存的所有对象。
脱管态对象无法直接获得,是由其他状态对象转换而来的,脱管态对象转换到其他状态总结如下:
- 脱管态转换为持久态:执行 Session的 update( )、 saveOrUpdate( )或 lock( )方法。
- 脱管态转换为瞬时态:将脱管态对象的持久化标识OID设置为null 。
4.持久态对象能够自动更新数据库
@Test //测试持久态对象有自动更新数据库的能力 public void test() { Session session=HibernateUtil.getCurrSession(); Transaction transaction=session.beginTransaction(); //获得持久态对象 Customer customer=session.get(Customer.class, 1l); //持久态对象 customer.setCust_name("Kevin_Zhang"); //不用手动调用update就可以更新 transaction.commit(); //session.close(); 由于在HibernateUtil中,使用getCurrentSession函数将线程和session进行了绑定,所以无需在手动关闭 }
四、Hiberate的一级缓存
为什么使用缓存:减少和数据库交互的次数,从而提高效率
适用缓存的数据:经常查询的,并且不经常修改的。同时数据一旦出现问题,对最终结果影响不大的。
不适用于缓存的数据:不管是否经常查询,只要是经常修改的,都可以不用缓存。并且如果数据由于使用缓存,产生了异常数据,对最终结果影响很大,则不能使用。例如股市的牌价、银行的汇率、商品的库存等。
1.什么是Hibernate的一级缓存
在 Session接口的实现中包含一系列的Java集合,这些Java集合构成了 Session缓存。只要Session实例没有结束生命周期,存放在它缓存中的对象也不会结束生命周期。固一级缓存也被称为是 Session基本的缓存。Hibernate的一级缓存有如下特点:
- 当应用程序调用 Session接口的 save( )、 update( )、 saveOrUpdate( )时,如果 Session缓存中没有相应的对象,,Hibernate就会自动的把从数据库中查询到的相应对象信息加入到一级缓存
中去。 - 当调用 Session接口的 load( )、get( )方法,以及 Query接口的 list( )、 iterator( )方法时,会判断缓存中是否存在该对象,有则返回,不会查询数据库,如果缓存中没有要查询对象,再去数据库中查询对应对象,并添加到一级缓存中。
- 当调用 Session的 close( )方法时,Session缓存会被清空。
@Test //证明Hibernate的一级缓存确实存在 public void test1(){ Session session=HibernateUtil.openSession(); Transaction tx=session.beginTransaction(); //1.根据id查询客户 Customer customer1=session.get(Customer.class, 1l);//先在数据库查询,并把查询结果存入了一级缓存中,此时会产生查询的Sql语句 System.out.println(customer1); //2.根据id再次查询客户 Customer customer2=session.get(Customer.class, 1l);//先去一级缓存中查看,如果有直接拿过来用,如果没有,再去查询,此时没有产生查询的Sql语句 System.out.println(customer2); System.out.println(customer1==customer2);//true tx.commit(); session.close();//session关闭,一级缓存消失 }
Hibernate: select customer0_.cust_id as cust_id1_0_0_, customer0_.cust_name as cust_nam2_0_0_, customer0_.cust_source as cust_sou3_0_0_, customer0_.cust_industry as cust_ind4_0_0_, customer0_.cust_level as cust_lev5_0_0_, customer0_.cust_linkman as cust_lin6_0_0_, customer0_.cust_phone as cust_pho7_0_0_, customer0_.cust_mobile as cust_mob8_0_0_ from cst_customer customer0_ where customer0_.cust_id=? Customer [cust_id=1, cust_name=Kevin_Zhang, cust_source=America, cust_industry=2, cust_level=2, cust_linkman=null, cust_phone=null, cust_mobile=null] Customer [cust_id=1, cust_name=Kevin_Zhang, cust_source=America, cust_industry=2, cust_level=2, cust_linkman=null, cust_phone=null, cust_mobile=null] true
- 原子性( Atomic):表示将事务中所做的操作捆绑成一个不可分割的单元,即对事务所进行的数据修改等操作,要么全部执行,要么全都不执行。
- 一致性( Consistency):表示事务完成时,必须使所有的数据都保持一致状态。
- 隔离性( Isolation):指一个事务的执行不能被其它事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
- 持久性( durability):持久性也称永久性( permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。提交后的其他操作或故障不会对其有任何影响。
(3) 虚读 / 幻读:一个事务读到了另一个事务已经提交的 insert 的数据,导致在同一个事务中的多次查询结果不一致。
- 读未提交( Read Uncommitted,1级):一个事务在执行过程中,既可以访问其他事务未提交的新插入的数据,又可以访问未提交的修改数据。如果一个事务已经开始写数据,则另外一个事务则不允许同时进行写操作,但允许其他事务读此行数据。此隔离级别可防止丢失更新。
- 已提交读( Read Committed,2级):一个事务在执行过程中,既可以访问其他事务成功提交的新插入的数据,又可以访问成功修改的数据。读取数据的事务允许其他事务继续访问该行数据,但是未提交的写事务将会禁止其他事务访问该行。此隔离级别可有效防止脏读。
- 可重复读( Repeatable Read,4级):一个事务在执行过程中,可以访问其他事务成功提交的新插入的数据,但不可以访问成功修改的数据。读取数据的事务将会禁止写事务(但允许读事务),写事务则禁止任何其他事务。此隔离级别可有效的防止不可重复读和脏读。
- 序列化/串行化( Serializable,8级):提供严格的事务隔离。它要求事务序列化执行,事务只能一个接着一个地执行,但不能并发执行。此隔离级别可有效的防止脏读、不可重复读和幻读。
● Oracle:READ_UNCOMMITTED、 READ_COMMITTED、 SERIALIZABLE(默认 READ_COMMITTED)。
实际开发中,不会选择最高或者最低隔离级别,选择 READ_COMMITTED( oracle默认)、REPEATABLE_READ( mysql默认)。
- 获得 Hibernate的 Session对象
- 编写HQL语句。
- 调用 session.createquery创建査询对象。
- 如果HQL语句包含参数,则调用 Query的 setxxx设置参数。
- 调用 Query对象的lisO或 uniqueresulto方法执行查询。
//Query执行HQL语句 //1.查询所有记录: //获取Query对象 Query query=session.createQuery("from Customer"); //2.获取结果集 List list=query.list(); for(Object o:list) System.out.println(o);
//2.1条件查询: //获取Query对象 Query query=session.createQuery("from Customer where cust_level=? and cust_name like ?"); //给参数占位符赋值 query.setString(0, "4"); //hibernate的参数占位符从0开始 query.setString(1, "%K%"); //2.获取结果集 List list=query.list(); for(Object o:list) System.out.println(o);
//2.2条件查询: //1.获取Query对象 //给参数起名需要使用:参数名称 Query query=session.createQuery("from Customer where cust_level=:level and cust_name like :name"); //给参数占位符赋值 //query.setString("level", "4"); //hibernate的参数占位符从0开始 //query.setString("name", "%K%"); query.setParameter("level", "3"); query.setParameter("name", "%k%"); //2.获取结果集 List list=query.list(); for(Object o:list) System.out.println(o);
//3.分页查询: Query q=s.createQuery("from Customer "); q.setFirstResult(1); q.setMaxResults(2); //获取结果集 List list=q.list(); for(Object o:list) System.out.println(o);
//4.排序查询 Query q=session.createQuery("from Customer order by cust_level desc"); List list=q.list(); for(Object o:list) System.out.println(o);
//5.统计查询: Query q=s.createQuery("select count(*) from Customer"); //List list=q.list(); //for(Object o:list) //System.out.println(o); Long count=(Long)q.uniqueResult();//当返回的结果唯一时,可以使用此方法。如果返回结果不唯一,使用了此方法会抛异常 System.out.println(count); //6.投影查询 Query q=s.createQuery("select new com.Kevin.domain.Customer(cust_id,cust_name) from Customer"); List list=q.list(); for(Object o:list){ System.out.println("---------Element-----------"); System.out.println(o); }
● iterator( ) 方法:该方法用于查询语句,返回的结果是一个 Iterator对象,在读取时只能按照顺序方式读取,它仅把使用到的数据转换成Java实体对象。
● uniqueResult( ) 方法:该方法用于返回唯一的结果,在确保只有一条记录的查询时可以使用该方法。
● executeUpdate( ) 方法:该方法是 Hibernate3的新特寺性,它支持HQL语句的更新和删除操作。
● setFirstResult( ) 方法:该方法可以设置获取第一个记录的位置,也就是它表示从第几条记录开始查询,默认从0开始计算。
● setMaxResult( ) 方法:该方法用于设置结果集的最大记录数,通常与 setFirstResult( ) 方法结合使用,用于限制结果集的范围,以实现分页功能。
2.Criteria
org.hibernate.criterion.Criterion 是 Hibernate提供的一个面向对象查询条件接口,一个单独的查询就是 Criterion接口的一个实例,用于限制 Criteria对象的查询,在 Hibernate中 Criterion对象的创建通常是通过 Restrictions工厂类完成的,它提供了条件查询方法。
通常,使用 Criteria对象查询数据的主要步骤,具体如下:
- 获得 Hibernate 的 Session对象。
- 通过 Session 获得 Criteria对象。
- 使用 Restrictions 的静态方法创建 Criterion条件对象。 Restrictions类中提供了一系列用于设定查询条件的静态方法,这些静态方法都返回 Criterion实例,每个 Criterion实例代表一个查询条件。
- 向 Criteria对象中添加 Criterion查询条件。 Criteria的adO方法用于加入查询条件。
- 执行 Criteria的 list( ) 或 uniqueResult( ) 获得结果。
//Hibernate中的QBC查询示例 //基本查询 //获取Criteria对象 Criteria c=session.createCriteria(Customer.class); //获取结果集 List list=c.list(); for(Object o:list) System.out.println(o); //条件查询 Criteria c=session.createCriteria(Customer.class); //使用Criteria对象的add方法来添加条件 c.add(Restrictions.eq("cust_level","4")); c.add(Restrictions.ilike("cust_name", "%k%")); //c.add(Restrictions.or) //获取结果集 List list=c.list(); for(Object o:list) System.out.println(o); //排序查询 Criteria c=session.createCriteria(Customer.class); //添加排序 c.addOrder(Order.desc("cust_level")); //获取结果集 List list=c.list(); for(Object o:list) System.out.println(o); //分页查询 //QBC的分页查询方法和HQL的分页查询方法的方法含义是一样的 Criteria c=session.createCriteria(Customer.class); //设置分页条件 c.setFirstResult(0); c.setMaxResults(3); //获取结果集 List list=c.list(); for(Object o:list) System.out.println(o); //统计(投影)查询 Criteria c=session.createCriteria(Customer.class); //设置使用聚合函数 //c.setProjection(Projections.rowCount()); c.setProjection(Projections.count("cust_id")); //获取结果集 //List list=c.list(); //for(Object o:list) //System.out.println(o); Long count = (Long)c.uniqueResult(); System.out.println(count); //离线查询 // 使用DetachedCriteria对象,该对象不需要获取session。可以直接得到 //使用DetachedCriteria对象实现的查询,称之为离线查询 @Test public void test6(){ //获取离线对象不需要session DetachedCriteria dc=DetachedCriteria.forClass(Customer.class); //封装查询条件 dc.add(Restrictions.eq("cust_level","4")); dc.add(Restrictions.ilike("cust_name", "%K%")); List list=testService(dc); for(Object o:list) System.out.println(o); } private List testService(DetachedCriteria dc){ Session s=null; Transaction tx=null; try{ s=HibernateUtil.getCurrSession(); tx=s.beginTransaction(); List list=testDao(dc); tx.commit(); return list; }catch(Exception e){ tx.rollback(); } return null; } private List testDao(DetachedCriteria dc){ Session s=HibernateUtil.getCurrSession(); //把离线对象转换成在线对象 Criteria c=dc.getExecutableCriteria(s); return c.list(); }