系统改变号SCN
System Change Number
我们看到的SCN一串数字,由时间通过函数算出来的,或者通过函数将SCN转成时间,简单的理解,SCN相当于时间。
两个时间的比较就是两个字符串比较,但是计算机内部比较倾向于数字之间的比较
时间使用来比较先后以及比较新旧的。所以在Oracle数据库中用的较多,可以经常在数据库接触到SCN,通过SCN的大小来判断数据的新旧或者先后顺序。
SQL> select dbms_flashback.get_system_change_number,SCN_TO_TIMESTAMP(dbms_flashback.get_system_change_number) from dual;

SCN在数据库中的应用
1.控制文件
系统SCN
select checkpoint_change# from v$database;

文件SCN
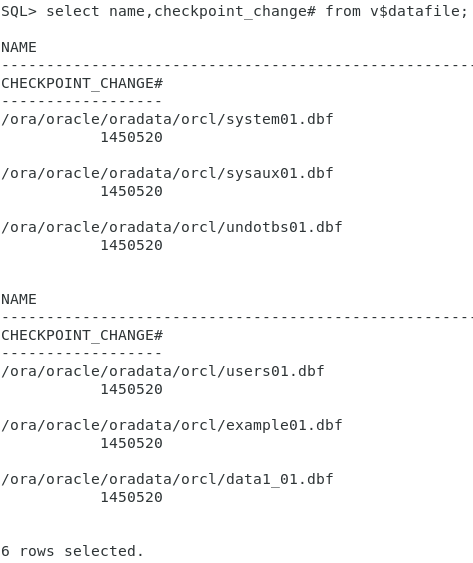
select name,checkpoint_change# from v$datafile;
结束SCN
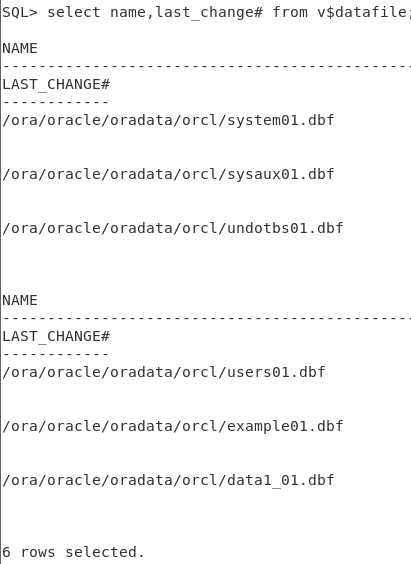
select name,last_change# from v$datafile;
检查点信息
增量检查点并不会去更新数据文件头,以及控制文件中的数据库SCN以及数据文件条目的SCN信息,而只是每3秒由CKPT进程去更新控制文件中的low cache rba信息,也就是检查点的位置。
select CPDRT,
CPLRBA_SEQ||'.'||CPLRBA_BNO||'.'||CPLRBA_BOF "Low RBA",
CPODR_SEQ||'.'||CPODR_BNO||'.'||CPODR_BOF "On disk RBA",CPODS,CPODT,CPHBT FROM x$kcccp;

CPDRT---检查点队列中的脏块数目
CPODS---是On disk RBA的SCN
CPODT---是On disk RBA的时间戳
CPHBT----是心跳
控制文件有三个SCN号,假设系统有四个数据文件,在控制文件中有一个系统SCN,对于每个数据文件有文件SCN,针对四个文件还有一个结束SCN,在文件的头部有开始SCN,目的只有一个保证数据文件的一致性!!
正常的情况下,数据库打开以后,系统SCN,在控制文件中的文件SCN,和开始SCN是相等的,因为数据库正常运行中,所以结束SCN应该是空。
数据库正常关闭以后,会将buffercache的所有缓存写到磁盘上,同时使用关闭时间点更新系统SCN,文件SCN和头部SCN。同时并将终止SCN设置成与其他三类SCN一样。
当数据库正常关闭以后,系统SCN,文件SCN,开始SCN,结束SCN都是一样的
如果数据库非正常关闭,此时的终止SCN是空的,当数据库下一次启动后就会发现终止SCN为空,也就是知道数据库非正常关闭,需要进行恢复。但是当进行恢复时,Oracle发现其他三类SCN是一样的,唯独终止SCN为空,此时Orace就知道,需要做实例恢复。
Oracle在做实例恢复的时候:
1.需要部分redolog日志,不需要所有的redolog,不需要归档log
2.需要的日志,在控制文件中记录着LRBA和O你 disk RBA,Oracle只找这段日志。而这段日志存在在redolog中。
redolog的状态:I 、Active 、current
当日志跑完了后,证明数据已经恢复,此时就可以正常的使用数据库了。
Oracle判断是否进行实例恢复是通过这些SCN的!!
SCN的作用:保证数据库的数据的一致性!!!
假设一种情况:
关闭数据库,此时将四个数据文件中的一个文件删除换成一个旧的备份文件,那么在oracle在祁东的时候就会发现,该文件的开始SCN与系统SCN和文件SCN是不一样的,这时Oracle通过日志将SCN跑成一样的。
在行业中经常说的一句话: 跑日志----目的:提升SCN
通过SCN可以判断文件的新旧,如果是旧的文件,旧的SCN,那么就会通过跑日志,将SCN更新成新的。实际上,就是将新文件进行恢复。
以上是四个SCN关联起来的作用。对于以后进行数据的恢复有很大的帮助。
每一个日志条文件的头部都有两个SCN,一个叫first,另个叫next
first是这一条日志的第一个SCN号,而next为最后一个SCN号(下一条日志的第一个SCN)
那么first和next记录的是这个日志文件所有的SCN号的范围
假设:有一个控制文件,四个dbf数据文件,还有日志文件
数据库在正常运行的期间,会有四个SCN号,分别是控制文件的系统SCN,文件SCN,结束SCN以及文件头部的开始SCN,除了结束SCN为空,其他三个SCN是相等的。
查看系统SCN和文件SCN
select name,checkpoint_change# from v$datafile;

在查看日志文件当前文件的SCN
select * from v$log;

这些SCN相等的,假如说这时数据库崩溃,此时需要恢复文件,只需要恢复884269之后文件即可,需要用到的日志就是当前日志即可(current)
此时做一个操作,执行两次强制日志切换,再去查看系统 文件以及firstSCN号
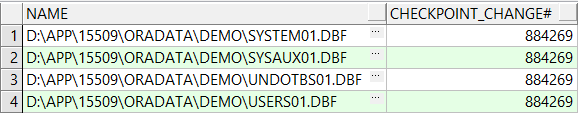
这时原来的current变为active(884269)

在这种状态下,数据库如果崩溃,需进行日志恢复,需要用到61号日志开始一直到63号日志,也就是三个日志。
文件的SCN号主要用来标识文件的新旧程度
当做日志切换的时候,系统的SCN号是不发生改变的,这四类SCN号的主要作用标志着文件的新旧程度以及一致程度。
其实在控制文件中是有具体的LRBA地址,具体oracle恢复时去找LRBA地址进行恢复
此时做另外一个操作,将buffer_cache中的所有脏块写入磁盘,此时在查看日志

日志状态由原来的active变为inactive
active----代表日志文件中的日志所对应的脏缓冲区未写入磁盘 代表日志不能被覆盖
脏缓冲区还未写回去意味着实例恢复的时候还需要active的日志
控制文件中的3个SCN号以及dbf头部的SCN号记录的是日志文件中的current和active日志的SCN号
在控制文件中的SCN号只是用来确定使用哪个日志文件进行恢复,而在日志之中,并不是所有的日志都要用到,控制文件中的LRBA地址决定的是使用日志文件中的哪些日志进行恢复。
系统,文件,起始SCN对应的是日志文件中最老的active日志的firstSCN号。
当检查点队列发生的时候,系统 ,文件,结束,起始SCN没有被更新,只是更新了控制文件中的LRBA地址。
而这四个SCN什么时候会更新呢?只有在数据库关闭的时候会更新。
而三个SCN什么时候会更新呢?只有日志状态的active变成inactive才会更新。
数据库非正常关闭的话,结束SCN为空,此时oracle会知道需要进行数据库恢复,但是当dbf文件被替换成旧的dbf时,需要用到归档日志和redolog日志一起将dbf文件恢复到最新。
做一个操作, 将数据库关闭,将控制文件以及四个dbf文件全部换成旧的,当oracle启动对四类SCN号进行判断的时候,是没有办法确定四个文件是新还是旧,需要看redolog中的on disk RBA(redolog中current的最后一条日志)会比四个SCN号要新,所以要恢复,仅仅使用redolog是没有办法进行恢复的。还需要归档日志。
查询以往日志的first和next
select recid,sequence#,first_change#,next_change# from v$log_history where rownum<6;
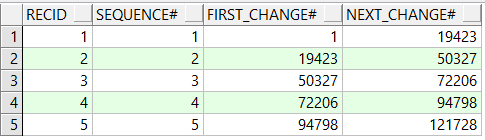
数据块有SCN,日志有SCN,假设块是新的,日志是旧的,那么在跑日志的时候,发现日志的SCN会比块的SCN旧,日志会略过块,空跑。
所以对于实例恢复时,跑日志是可以多,但不能少。

Oracle有一个参数,fast_start_mttr_target
参考博文:https://blog.csdn.net/qq_36249352/article/details/80704548