统计翻译模型核心就是基于短语的翻译(短语与短语的对应)。
上一讲中词到词的对应就是为了短语对应做铺垫。


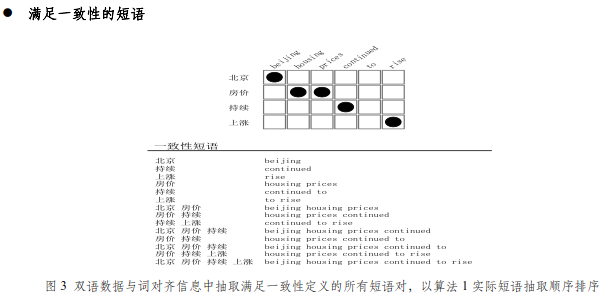
一致性短语需要满足三个条件:
条件1:如果“北京 房价”对应的英文短语中包含“北京”、“房价”分别对应的英文单词(原因是在词对齐的时候,可以发现有很多轮空的.)
条件2:





以目标语言为基础,不同目标长度做标准:滑动窗口的大小先从1开始到2,3........
先以目标长度(英文拆分成一个个单词)为1开始遍历:housing对应房价,但是房价对应housing prices。此时,发现prices不在目标英文中,将prices标记上蓝色表示异常。
“prices”对应的是房价,房价对应的是“housing prices”,此时“housing“”又不在目标英文中,将”housing”标记为蓝色表示异常。
接着以目标长度为2进行遍历,“beijing housing”对应的是“北京 房价”,再找“北京 房价”对应的却是“beijing housing prices”,将异常点prices标记为蓝色
“housing prices”成功双向对应“房价”,没有异常点
“prices continued”对应“房价 持续”,而“房价 持续”对应的是“housing prices continued”,将异常点housing标记为蓝色
以此类推。窗口加大一个单词的条件,窗口遍历到了最后一个单词。
遍历结束的条件:窗口大小达到了句子的长度。
在此过程中,利用上一讲的翻译表从词对词来生成短语到短语。因此本操作最后得到的是候选短语。