Task5——卷积神经网络基础;leNet;卷积神经网络进阶

10.1 卷积神经网络(CNN)基础
卷积神经网络是一种用来处理局部和整体相关性的计算网络结构,被应用在图像识别、自然语言处理甚至是语音识别领域,因为图像数据具有显著的局部与整体关系,其在图像识别领域的应用获得了巨大的成功。
10.1.1 卷积神经网络的组成层
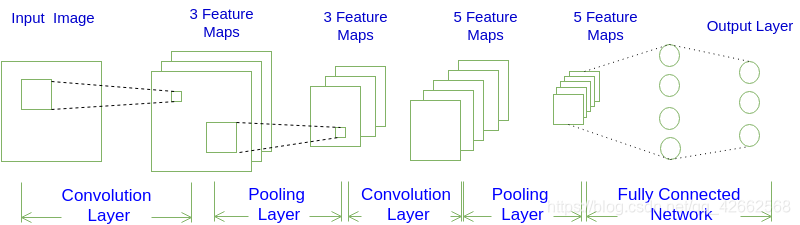
图10.1 卷积神经网络示意图
以图像分类任务为例,在表10.1所示卷积神经网络中,一般包含5种类型的网络层次结构:
表10.1 卷积神经网络的组成
| CNN层次结构 | 输出尺寸 | 作用 |
|---|---|---|
| 输入层 | 卷积网络的原始输入,可以是原始或预处理后的像素矩阵 | |
| 卷积层 | 参数共享、局部连接,利用平移不变性从全局特征图提取局部特征 | |
| 激活层 | 将卷积层的输出结果进行非线性映射 | |
| 池化层 | 进一步筛选特征,可以有效减少后续网络层次所需的参数量 | |
| 全连接层 | 将多维特征展平为2维特征,通常低维度特征对应任务的学习目标(类别或回归值) |
对应原始图像或经过预处理的像素值矩阵,3对应RGB图像的通道;表示卷积层中卷积核(滤波器)的个数; 为池化后特征图的尺度,在全局池化中尺度对应;是将多维特征压缩到1维之后的大小,对应的则是图像类别个数。
10.1.1.1 输入层
输入层(Input Layer)通常是输入卷积神经网络的原始数据或经过预处理的数据,可以是图像识别领域中原始三维的多彩图像,也可以是音频识别领域中经过傅利叶变换的二维波形数据,甚至是自然语言处理中一维表示的句子向量。以图像分类任务为例,输入层输入的图像一般包含RGB三个通道,是一个由长宽分别为和组成的3维像素值矩阵,卷积网络会将输入层的数据传递到一系列卷积、池化等操作进行特征提取和转化,最终由全连接层对特征进行汇总和结果输出。根据计算能力、存储大小和模型结构的不同,卷积神经网络每次可以批量处理的图像个数不尽相同,若指定输入层接收到的图像个数为,则输入层的输出数据为。
10.1.1.2 卷积层
卷积层(Convolution Layer)通常用作对输入层输入数据进行特征提取,通过卷积核矩阵对原始数据中隐含关联性的一种抽象。卷积操作原理上其实是对两张像素矩阵进行点乘求和的数学操作,其中一个矩阵为输入的数据矩阵,另一个矩阵则为卷积核(滤波器或特征矩阵),求得的结果表示为原始图像中提取的特定局部特征。图5.1表示卷积操作过程中的不同填充策略,上半部分采用零填充,下半部分采用有效卷积(舍弃不能完整运算的边缘部分)。
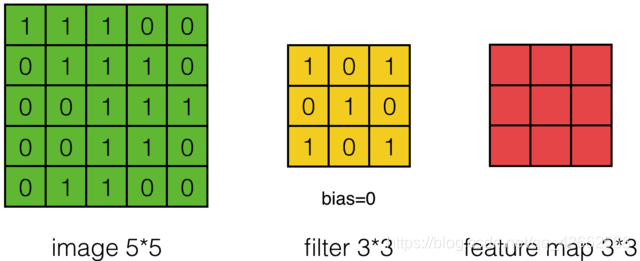
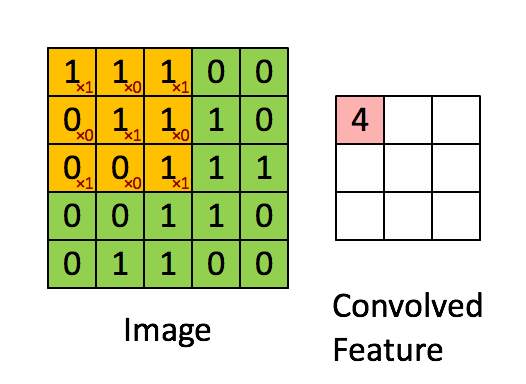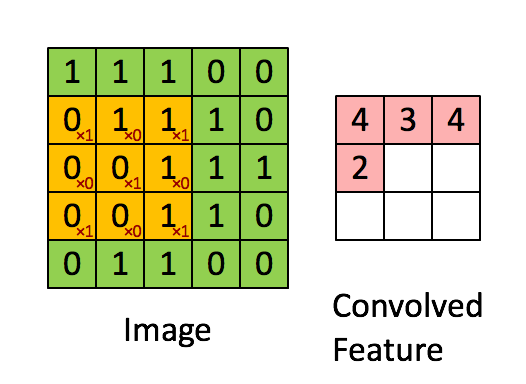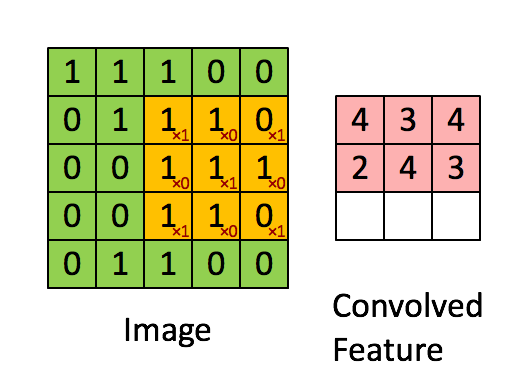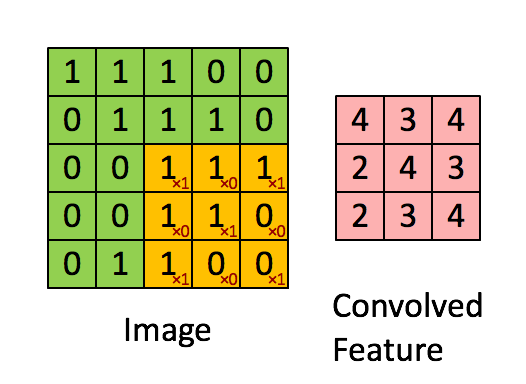
图10.2 卷积操作示意图
10.1.1.3 激活层
激活层(Activation Layer)负责对卷积层抽取的特征进行激活,由于卷积操作是由输入矩阵与卷积核矩阵进行相差的线性变化关系,需要激活层对其进行非线性的映射。激活层主要由激活函数组成,即在卷积层输出结果的基础上嵌套一个非线性函数,让输出的特征图具有非线性关系。卷积网络中通常采用ReLU来充当激活函数(还包括tanh和sigmoid等)ReLU的函数形式如公式(10-1)所示,能够限制小于0的值为0,同时大于等于0的值保持不变。
10.1.1.4 池化层
池化层又称为降采样层(Downsampling Layer),作用是对感受域内的特征进行筛选,提取区域内最具代表性的特征,能够有效地降低输出特征尺度,进而减少模型所需要的参数量。按操作类型通常分为最大池化(Max Pooling)、平均池化(Average Pooling)和求和池化(Sum Pooling),它们分别提取感受域内最大、平均与总和的特征值作为输出,最常用的是最大池化。
10.1.1.5 全连接层
全连接层(Full Connected Layer)负责对卷积神经网络学习提取到的特征进行汇总,将多维的特征输入映射为二维的特征输出,高维表示样本批次,低位常常对应任务目标。
10.1.2 填充和步幅
10.1.2.1 步幅 (Stride)
卷积核步长 (Stride) :定义了卷积核在卷积过程中的步长,常见设置为1,表示滑窗距离为1,可以覆盖所有相邻位置特征的组合;当设置为更大值时相当于对特征组合降采样 。
在互相关运算中,卷积核在输入数组上滑动,每次滑动的行数与列数即是步幅(stride)。此前我们使用的步幅都是1,图10.3展示了在高上步幅为3、在宽上步幅为2的二维互相关运算。
图10.3 高和宽上步幅分别为3和2的二维互相关运算
一般来说,当高上步幅为,宽上步幅为时,输出形状为:
如果,,那么输出形状将简化为。更进一步,如果输入的高和宽能分别被高和宽上的步幅整除,那么输出形状将是。
当时,我们称填充为;当时,我们称步幅为。
10.1.2.2 填充(Padding)
假设有一个5×5 的特征图(共25 个方块)。其中只有9 个方块可以作为中心放入一个3×3 的窗口,这9 个方块形成一个3×3 的网格(见图10.4)。因此,输出特征图的尺寸是3×3。它比输入尺寸小了一点,在本例中沿着每个维度都正好缩小了2 个方块。
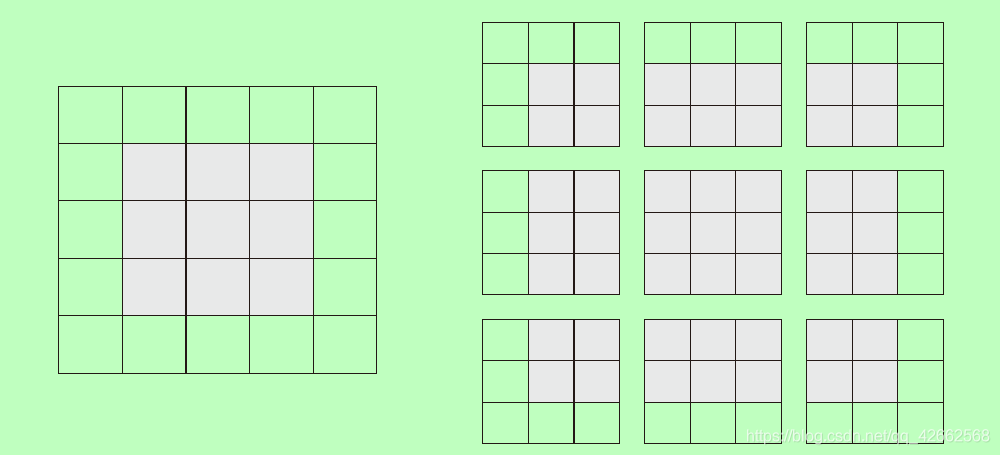
图10.4 在5×5 的输入特征图中,可以提取3×3 图块的有效位置
如果你希望输出特征图的空间维度与输入相同,那么可以使用填充(padding)。填充是在输入特征图的每一边添加适当数目的行和列,使得每个输入方块都能作为卷积窗口的中心。对于3×3 的窗口,在左右各添加一列,在上下各添加一行。对于5×5 的窗口,各添加两行和两列(见图10.5)。
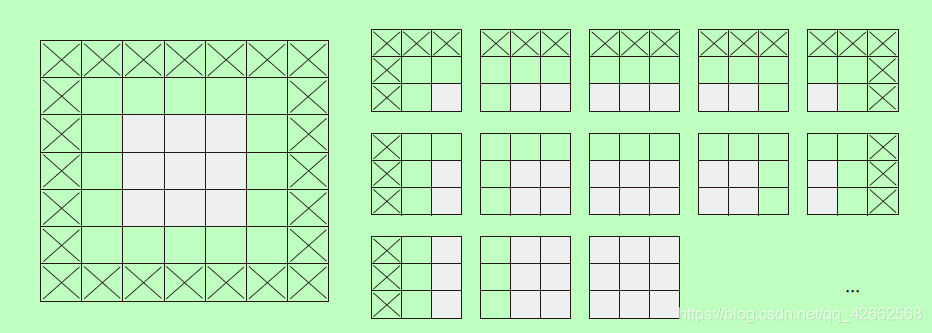
图10.5 对5×5 的输入进行填充,以便能够提取出25 个3×3 的图块
10.1.3 最大池化运算
在卷积神经网络示例中,你可能注意到,在每个MaxPooling2D 层之后,特征图的尺寸都会减半。例如,在第一个MaxPooling2D 层之前,特征图的尺寸是26×26,但最大池化运算将其减半为13×13。这就是最大池化的作用:对特征图进行下采样,与步进卷积类似。
最大池化是从输入特征图中提取窗口,并输出每个通道的最大值。它的概念与卷积类似,但是最大池化使用硬编码的max 张量运算对局部图块进行变换,而不是使用学到的线性变换(卷积核)。最大池化与卷积的最大不同之处在于,最大池化通常使用2×2 的窗口和步幅2,其目的是将特征图下采样2 倍。与此相对的是,卷积通常使用3×3 窗口和步幅1。
简而言之,使用下采样的原因,一是减少需要处理的特征图的元素个数,二是通过让连续卷积层的观察窗口越来越大(即窗口覆盖原始输入的比例越来越大),从而引入空间过滤器的层级结构。
注意,最大池化不是实现这种下采样的唯一方法。你已经知道,还可以在前一个卷积层中使用步幅来实现。此外,你还可以使用平均池化来代替最大池化,其方法是将每个局部输入图块变换为取该图块各通道的平均值,而不是最大值。但最大池化的效果往往比这些替代方法更好。简而言之,原因在于特征中往往编码了某种模式或概念在特征图的不同位置是否存在(因此得名特征图),而观察不同特征的最大值而不是平均值能够给出更多的信息。因此,最合理的子采样策略是首先生成密集的特征图(通过无步进的卷积),然后观察特征每个小图块上的最大激活,而不是查看输入的稀疏窗口(通过步进卷积)或对输入图块取平均,因为后两种方法可能导致错过或淡化特征是否存在的信息。
10.1.4 多输入通道和多输出通道
之前的输入和输出都是二维数组,但真实数据的维度经常更高。例如,彩色图像在高和宽2个维度外还有RGB(红、绿、蓝)3个颜色通道。假设彩色图像的高和宽分别是和(像素),那么它可以表示为一个的多维数组,我们将大小为3的这一维称为通道(channel)维。
10.1.4.1 多输入通道
卷积层的输入可以包含多个通道,图4展示了一个含2个输入通道的二维互相关计算的例子。
图10.6 含2个输入通道的互相关计算
假设输入数据的通道数为,卷积核形状为,我们为每个输入通道各分配一个形状为的核数组,将个互相关运算的二维输出按通道相加,得到一个二维数组作为输出。我们把个核数组在通道维上连结,即得到一个形状为的卷积核。
10.1.4.2 多输出通道
卷积层的输出也可以包含多个通道,设卷积核输入通道数和输出通道数分别为和,高和宽分别为和。如果希望得到含多个通道的输出,我们可以为每个输出通道分别创建形状为的核数组,将它们在输出通道维上连结,卷积核的形状即。
对于输出通道的卷积核,我们提供这样一种理解,一个的核数组可以提取某种局部特征,但是输入可能具有相当丰富的特征,我们需要有多个这样的的核数组,不同的核数组提取的是不同的特征。
10.1.5 卷积层的简洁实现
import torch
import torch.nn as nn
X = torch.rand(1, 3, 224, 224) #(批量,通道数,高度,宽度)
print(X.shape)
conv2d = nn.Conv2d(in_channels=3,
out_channels=96,
kernel_size=11,
stride=4,
padding=0)
Y = conv2d(X)
print('Y.shape: ', Y.shape)
print('weight.shape: ', conv2d.weight.shape)
print('bias.shape: ', conv2d.bias.shape)
输出:
torch.Size([1, 3, 224, 224])
Y.shape: torch.Size([1, 96, 54, 54])
weight.shape: torch.Size([96, 3, 11, 11])
bias.shape: torch.Size([96])
10.1.6 池化层的简洁实现
X = torch.arange(32, dtype=torch.float32).view(1, 2, 4, 4) #(批量,通道,高度,宽度)
pool2d = nn.MaxPool2d(kernel_size=3, padding=1, stride=(2, 1))
Y = pool2d(X)
print(X)
print(Y)
输出:
tensor([[[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.]],
[[16., 17., 18., 19.],
[20., 21., 22., 23.],
[24., 25., 26., 27.],
[28., 29., 30., 31.]]]])
tensor([[[[ 5., 6., 7., 7.],
[13., 14., 15., 15.]],
[[21., 22., 23., 23.],
[29., 30., 31., 31.]]]])
10.2 LeNet 模型
LeNet分为卷积层块和全连接层块两个部分。下面我们分别介绍这两个模块。
卷积层块里的基本单位是卷积层后接平均池化层:卷积层用来识别图像里的空间模式,如线条和物体局部,之后的平均池化层则用来降低卷积层对位置的敏感性。
卷积层块由两个这样的基本单位重复堆叠构成。在卷积层块中,每个卷积层都使用的窗口,并在输出上使用sigmoid激活函数。第一个卷积层输出通道数为6,第二个卷积层输出通道数则增加到16。
全连接层块含3个全连接层。它们的输出个数分别是120、84和10,其中10为输出的类别个数。
下面我们通过Sequential类来实现LeNet模型。
#import
import sys
sys.path.append("/home/kesci/input")
import d2lzh1981 as d2l
import torch
import torch.nn as nn
import torch.optim as optim
import time
#net
class Flatten(torch.nn.Module): #展平操作
def forward(self, x):
return x.view(x.shape[0], -1)
class Reshape(torch.nn.Module): #将图像大小重定型
def forward(self, x):
return x.view(-1, 1, 28, 28) #(B x C x H x W)
net = torch.nn.Sequential( #Lelet
Reshape(),
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5,
padding=2), #b*1*28*28 =>b*6*28*28
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), #b*6*28*28 =>b*6*14*14
nn.Conv2d(in_channels=6, out_channels=16,
kernel_size=5), #b*6*14*14 =>b*16*10*10
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), #b*16*10*10 => b*16*5*5
Flatten(), #b*16*5*5 => b*400
nn.Linear(in_features=16 * 5 * 5, out_features=120),
nn.Sigmoid(),
nn.Linear(120, 84),
nn.Sigmoid(),
nn.Linear(84, 10))
#print
X = torch.randn(size=(1,1,28,28), dtype = torch.float32)
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape: ',X.shape)
Reshape output shape: torch.Size([1, 1, 28, 28])
Conv2d output shape: torch.Size([1, 6, 28, 28])
Sigmoid output shape: torch.Size([1, 6, 28, 28])
AvgPool2d output shape: torch.Size([1, 6, 14, 14])
Conv2d output shape: torch.Size([1, 16, 10, 10])
Sigmoid output shape: torch.Size([1, 16, 10, 10])
AvgPool2d output shape: torch.Size([1, 16, 5, 5])
Flatten output shape: torch.Size([1, 400])
Linear output shape: torch.Size([1, 120])
Sigmoid output shape: torch.Size([1, 120])
Linear output shape: torch.Size([1, 84])
Sigmoid output shape: torch.Size([1, 84])
Linear output shape: torch.Size([1, 10])
卷积神经网络就是含卷积层的网络。 LeNet交替使用卷积层和最大池化层后接全连接层来进行图像分类。
10.3 AlexNet
首次证明了学习到的特征可以超越⼿⼯设计的特征,从而⼀举打破计算机视觉研究的前状。
特征:
- 8层变换,其中有5层卷积和2层全连接隐藏层,以及1个全连接输出层。
- 将sigmoid激活函数改成了更加简单的ReLU激活函数。
- 用Dropout来控制全连接层的模型复杂度。
- 引入数据增强,如翻转、裁剪和颜色变化,从而进一步扩大数据集来缓解过拟合。
import time
import torch
from torch import nn, optim
import torchvision
import numpy as np
import sys
sys.path.append("/home/kesci/input/")
import d2lzh1981 as d2l
import os
import torch.nn.functional as F
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(
1, 96, 11,
4), # in_channels, out_channels, kernel_size, stride, padding
nn.ReLU(),
nn.MaxPool2d(3, 2), # kernel_size, stride
# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数
nn.Conv2d(96, 256, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(3, 2),
# 连续3个卷积层,且使用更小的卷积窗口。除了最后的卷积层外,进一步增大了输出通道数。
# 前两个卷积层后不使用池化层来减小输入的高和宽
nn.Conv2d(256, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 256, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(3, 2))
# 这里全连接层的输出个数比LeNet中的大数倍。使用丢弃层来缓解过拟合
self.fc = nn.Sequential(
nn.Linear(256 * 5 * 5, 4096),
nn.ReLU(),
nn.Dropout(0.5),
#由于使用CPU镜像,精简网络,若为GPU镜像可添加该层
#nn.Linear(4096, 4096),
#nn.ReLU(),
#nn.Dropout(0.5),
# 输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000
nn.Linear(4096, 10),
)
def forward(self, img):
feature = self.conv(img)
output = self.fc(feature.view(img.shape[0], -1))
return output
net = AlexNet()
print(net)
AlexNet(
(conv): Sequential(
(0): Conv2d(1, 96, kernel_size=(11, 11), stride=(4, 4))
(1): ReLU()
(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(96, 256, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(4): ReLU()
(5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Conv2d(256, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU()
(8): Conv2d(384, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): ReLU()
(10): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU()
(12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc): Sequential(
(0): Linear(in_features=6400, out_features=4096, bias=True)
(1): ReLU()
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=10, bias=True)
)
)
10.4 使用重复元素的网络(VGG)
VGG:通过重复使⽤简单的基础块来构建深度模型。
Block:数个相同的填充为1、窗口形状为的卷积层,接上一个步幅为2、窗口形状为的最大池化层。
卷积层保持输入的高和宽不变,而池化层则对其减半。
def vgg_block(num_convs, in_channels, out_channels): #卷积层个数,输入通道数,输出通道数
blk = []
for i in range(num_convs):
if i == 0:
blk.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
else:
blk.append(nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1))
blk.append(nn.ReLU())
blk.append(nn.MaxPool2d(kernel_size=2, stride=2)) # 这里会使宽高减半
return nn.Sequential(*blk)
conv_arch = ((1, 1, 64), (1, 64, 128), (2, 128, 256), (2, 256, 512), (2, 512, 512))
# 经过5个vgg_block, 宽高会减半5次, 变成 224/32 = 7
fc_features = 512 * 7 * 7 # c * w * h
fc_hidden_units = 4096 # 任意
def vgg(conv_arch, fc_features, fc_hidden_units=4096):
net = nn.Sequential()
# 卷积层部分
for i, (num_convs, in_channels, out_channels) in enumerate(conv_arch):
# 每经过一个vgg_block都会使宽高减半
net.add_module("vgg_block_" + str(i + 1),
vgg_block(num_convs, in_channels, out_channels))
# 全连接层部分
net.add_module(
"fc",
nn.Sequential(d2l.FlattenLayer(),
nn.Linear(fc_features, fc_hidden_units), nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, fc_hidden_units), nn.ReLU(),
nn.Dropout(0.5), nn.Linear(fc_hidden_units, 10)))
return net
net = vgg(conv_arch, fc_features, fc_hidden_units)
X = torch.rand(1, 1, 224, 224)
# named_children获取一级子模块及其名字(named_modules会返回所有子模块,包括子模块的子模块)
for name, blk in net.named_children():
X = blk(X)
print(name, 'output shape: ', X.shape)
vgg_block_1 output shape: torch.Size([1, 64, 112, 112])
vgg_block_2 output shape: torch.Size([1, 128, 56, 56])
vgg_block_3 output shape: torch.Size([1, 256, 28, 28])
vgg_block_4 output shape: torch.Size([1, 512, 14, 14])
vgg_block_5 output shape: torch.Size([1, 512, 7, 7])
fc output shape: torch.Size([1, 10])
ratio = 8
small_conv_arch = [(1, 1, 64 // ratio), (1, 64 // ratio, 128 // ratio),
(2, 128 // ratio, 256 // ratio),
(2, 256 // ratio, 512 // ratio),
(2, 512 // ratio, 512 // ratio)]
net = vgg(small_conv_arch, fc_features // ratio, fc_hidden_units // ratio)
print(net)
Sequential(
(vgg_block_1): Sequential(
(0): Conv2d(1, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(vgg_block_2): Sequential(
(0): Conv2d(8, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(vgg_block_3): Sequential(
(0): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(vgg_block_4): Sequential(
(0): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(vgg_block_5): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc): Sequential(
(0): FlattenLayer()
(1): Linear(in_features=3136, out_features=512, bias=True)
(2): ReLU()
(3): Dropout(p=0.5, inplace=False)
(4): Linear(in_features=512, out_features=512, bias=True)
(5): ReLU()
(6): Dropout(p=0.5, inplace=False)
(7): Linear(in_features=512, out_features=10, bias=True)
)
)
10.5 ⽹络中的⽹络(NiN)
LeNet、AlexNet和VGG:先以由卷积层构成的模块充分抽取 空间特征,再以由全连接层构成的模块来输出分类结果。
NiN:串联多个由卷积层和“全连接”层构成的小⽹络来构建⼀个深层⽹络。
⽤了输出通道数等于标签类别数的NiN块,然后使⽤全局平均池化层对每个通道中所有元素求平均并直接⽤于分类。
1×1卷积核作用
1.放缩通道数:通过控制卷积核的数量达到通道数的放缩。
2.增加非线性。1×1卷积核的卷积过程相当于全连接层的计算过程,并且还加入了非线性激活函数,从而可以增加网络的非线性。
3.计算参数少
10.6 GoogLeNet
- 由Inception基础块组成。
- Inception块相当于⼀个有4条线路的⼦⽹络。它通过不同窗口形状的卷积层和最⼤池化层来并⾏抽取信息,并使⽤1×1卷积层减少通道数从而降低模型复杂度。
- 可以⾃定义的超参数是每个层的输出通道数,我们以此来控制模型复杂度。
完整模型结构
class Inception(nn.Module):
# c1 - c4为每条线路里的层的输出通道数
def __init__(self, in_c, c1, c2, c3, c4):
super(Inception, self).__init__()
# 线路1,单1 x 1卷积层
self.p1_1 = nn.Conv2d(in_c, c1, kernel_size=1)
# 线路2,1 x 1卷积层后接3 x 3卷积层
self.p2_1 = nn.Conv2d(in_c, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
# 线路3,1 x 1卷积层后接5 x 5卷积层
self.p3_1 = nn.Conv2d(in_c, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
# 线路4,3 x 3最大池化层后接1 x 1卷积层
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_c, c4, kernel_size=1)
def forward(self, x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
return torch.cat((p1, p2, p3, p4), dim=1) # 在通道维上连结输出
参考内容
[1] 卷积神经网络研究综述[J]. 计算机学报, 2017, 40(6):1229-1251.
[2] DeepLearning 500问.
[3] Jack Cui的博客.
[4] (Keras) Deep Learning with Python (中英文).