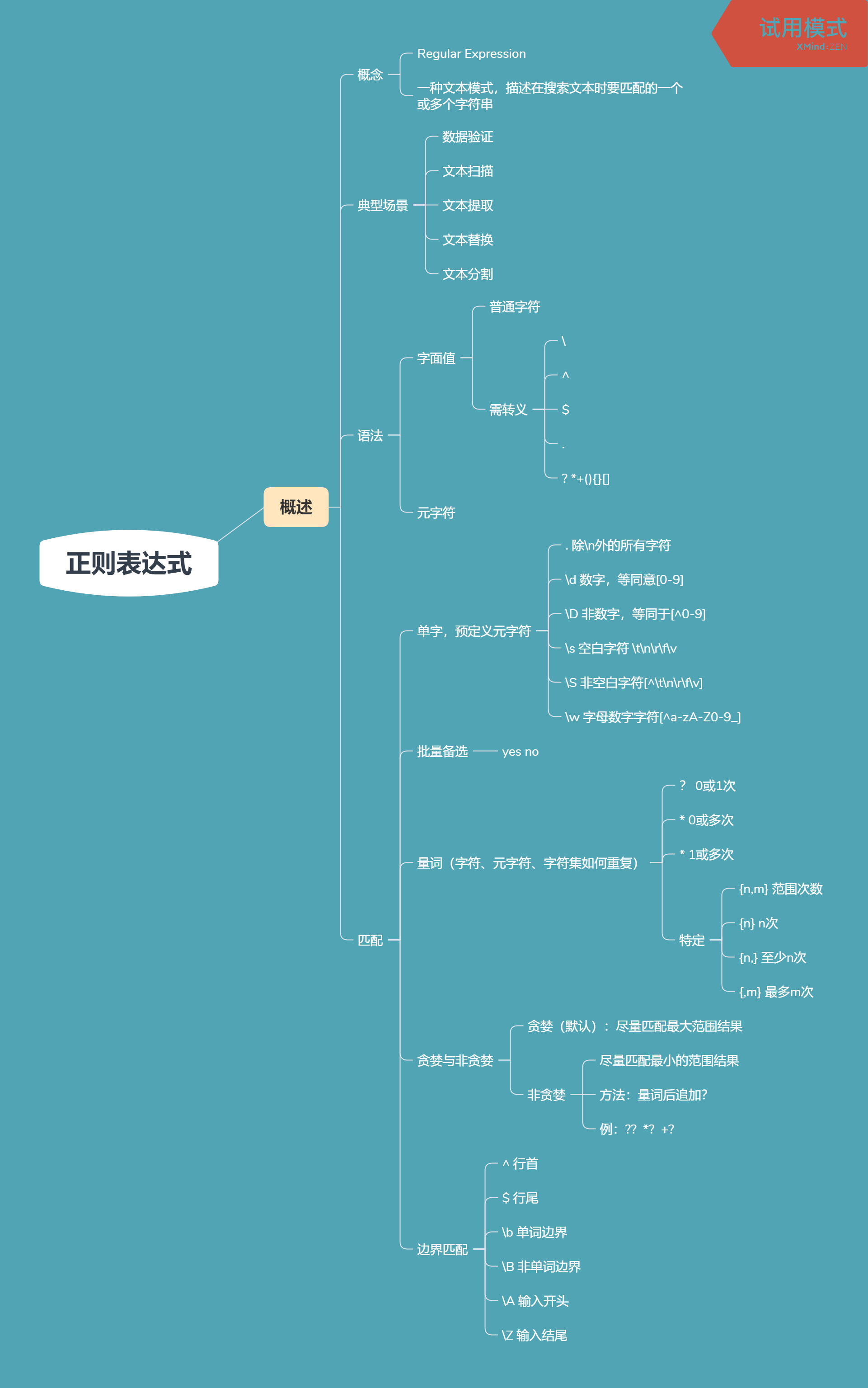
------------恢复内容开始------------
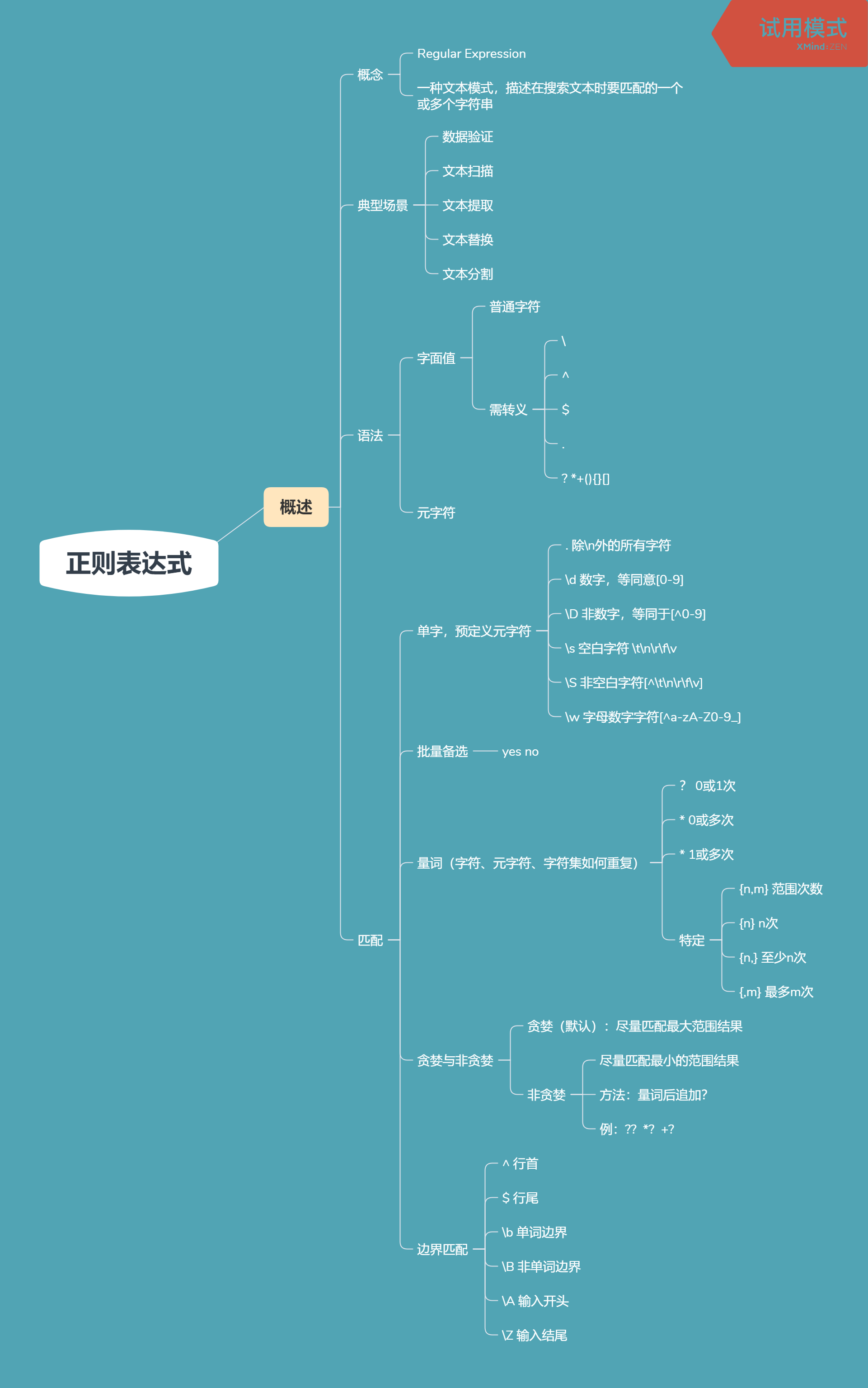
import re
text = "Tom is 8 years old. Mike is 25 years old."
pattern = re.compile('d+') #模式字符串编译
pattern.findall(text)
Out[5]: ['8', '25']
text
Out[6]: 'Tom is 8 years old. Mike is 25 years old.'
re.findall('d+',text)
Out[7]: ['8', '25']
import re
s = "\author:Tom"
pattern = re.compile('\author')
pattern.findall(s)
Out[5]: []
pattern = re.compile('\\author')
pattern.findall(s)
import re text = 'Tom is 8 years old. Mike is 35 years old. Peter is 68 years old.' pattern = re.compile(r'd+') pattern.findall(text) Out[5]: ['8', '35', '68'] p_name = re.compile(r'[A-Z]w+')#匹配模式 p_name.findall(text) Out[7]: ['Tom', 'Mike', 'Peter']

Python正则模块之MatchObject
In[2]: import re
In[3]: text = 'Tom is 8 years old. Jarry is 23 years old.'
In[4]: pattern = re.compile(r'd+') #编译一个模式
In[5]: pattern.findall(text)#找到所有匹配项
Out[5]: ['8', '23']
In[6]: pattern = re.compile(r'(d+).*?()')#编译模式把第一个d+放入一个分组里
In[7]: pattern = re.compile(r'(d+).*?(d+)')#编译模式把第一个d+放入一个分组里,?避免贪婪模式匹配
In[8]: m = pattern.search(text) #搜索
In[9]: m
Out[9]: <re.Match object; span=(7, 31), match='8 years old. Jarry is 23'>
In[10]: m.group()
Out[10]: '8 years old. Jarry is 23'
In[11]: m.group(0)#写0表示整体,用括号进行编组,不管写不写0默认返回整体
Out[11]: '8 years old. Jarry is 23'
In[12]: m.group(1)#模式匹配第一个匹配的值
Out[12]: '8'
In[13]: m.group(2)#第二个匹配的值
Out[13]: '23'
In[14]: m.start(1) #第一个分组数字8的文本对应下标
Out[14]: 7
In[15]: m.end(1)#第一个文本8在哪个位置终止
Out[15]: 8
In[16]: m.start(2)#看第二个分组所对应的值23
Out[16]: 29
In[17]: m.end(2)
Out[17]: 31
In[18]: m.group()
Out[18]: '8 years old. Jarry is 23'
In[19]: m.groups()#返回匹配单个结果
Out[19]: ('8', '23')
In[20]: m.groupdict()
Out[20]: {}

In[2]: import re
In[3]: pattern = re.compile(r'(w+) (w+)')
In[4]: text = "Beautiful is better than ugly."
In[5]: pattern.findall(text)#两两匹配
Out[5]:[('Beautiful', 'is'), ('better', 'than')]
Group编组
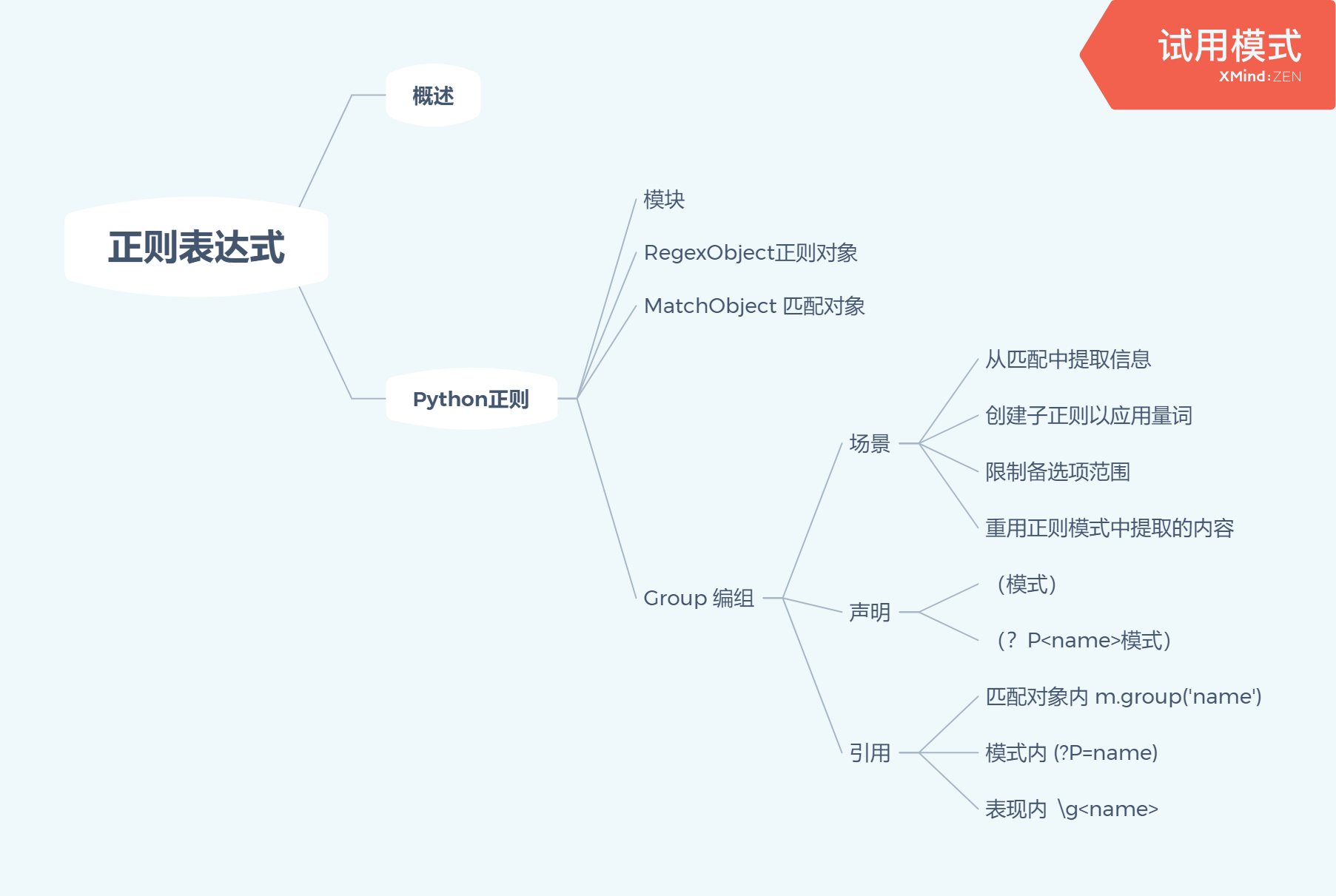
创建子正则以应用量词
In[2]: import re In[3]: re.search(r'ab+c','ababc')#把b当成一次或多次 Out[3]: <re.Match object; span=(2, 5), match='abc'> In[4]: re.search(r'(ab)+c','ababc') Out[4]: <re.Match object; span=(0, 5), match='ababc'>
限制备选项范围
In[5]: re.search(r'Center|re','Center')#匹配一个叫Center的单词 Out[5]: <re.Match object; span=(0, 6), match='Center'> In[6]: re.search(r'Center|re','Centre') Out[6]: <re.Match object; span=(4, 6), match='re'> In[7]: re.search(r'Cent(er|re)','Centre') Out[7]: <re.Match object; span=(0, 6), match='Centre'>
重用正则模式中提取的内容
In[8]: re.search(r'(w+) 1','hello world')#当前位置重现第一个编组 In[9]: re.search(r'(w+) 1','hello hello world') Out[9]: <_sre.SRE_Match object; span=(0, 11), match='hello hello'>
引用
In[2]: import re
In[3]: text = "Tom:98"
In[4]: pattern = re.compile(r'(w+):(d+)')#w若干个字母字符,d若干个数字
In[5]: m = pattern.search(text)
In[6]: m.group()
Out[6]: 'Tom:98'
In[7]: m.groups()
Out[7]: ('Tom', '98')
In[8]: m.group(1)#第一个分组匹配啥
Out[8]: 'Tom'
In[11]: pattern = re.compile(r'(?P<name>w+):(?P<score>d+)')
In[9]: m = pattern.search(text)
In[10]: m.group()
Out[10]: 'Tom:98'
In[11]: m.group(1)
Out[11]: 'Tom'
In[12]: m.group('name')
Out[12]: 'Tom'
In[13]: m.group('score')
Out[13]: '98'
综合应用
切割
>>> import re#导入模块
>>> text = 'Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex'#声明文本
>>> re.compile(r'
')#想按
切割内容
re.compile('\n')
>>> p = re.compile(r'
')#想按
切割内容
>>> p.split(text)
['Beautiful is better than ugly.', 'Explicit is better than implicit.', 'Simple is better than complex']
>>> re.split(r'
',text)#第二种方法
['Beautiful is better than ugly.', 'Explicit is better than implicit.', 'Simple is better than complex']
>>> re.split(r'W','Good morning')#小写w是字符A-Z大小写以及数字0-9包括下划线,大写W是反过来除了这些字符以外的,结果是以空格拆分
['Good', 'morning']
>>> re.split(r'-','Good-morning')
['Good', 'morning']
>>> re.split(r'(-)','Good-morning')#把-也放入切割里面
['Good', '-', 'morning']
>>> text #以 切割最大切割两个 'Beautiful is better than ugly. Explicit is better than implicit. Simple is better than complex' >>> re.split(r' ', text, 2)#前面切割两个,后面保留切割整体 ['Beautiful is better than ugly.', 'Explicit is better than implicit.', 'Simple is better than complex'] >>> re.split(r' ', text, 1) ['Beautiful is better than ugly.', 'Explicit is better than implicit. Simple is better than complex']
替换
>>> ords = 'ORD000
ORD001
ORD003'
>>> re.sub(r'd+', '-', ords)#d是找数字,d+一次或多次的数字,想替换成-,ords变量里替换
'ORD-
ORD-
ORD-'
>>> text = 'Beautiful is *better* than ugly'
>>> re.sub(r'*(.*?)*','<strong></strong>', text)#把*号替换
'Beautiful is <strong></strong> than ugly'
>>> re.sub(r'*(.*?)*','<strong>g<1></strong>', text)#定义分组引用保留原有的
'Beautiful is <strong>better</strong> than ugly'
>>> re.sub(r'*(?P<html>.*?)*','<strong>g<1></strong>', text)
'Beautiful is <strong>better</strong> than ugly'
>>> ords
'ORD000
ORD001
ORD003'
>>> re.sub(r'([A-Z]+)(d+)','g<2>-g<1>',ords) #A-Z重复若干次,数字d+出现若干次,想换成先是数字-再加原来字母
'000-ORD
001-ORD
003-ORD'
>>> re.subn(r'([A-Z]+)(d+)','g<2>-g<1>',ords) #告诉结果后面总共替换几次
('000-ORD
001-ORD
003-ORD', 3)
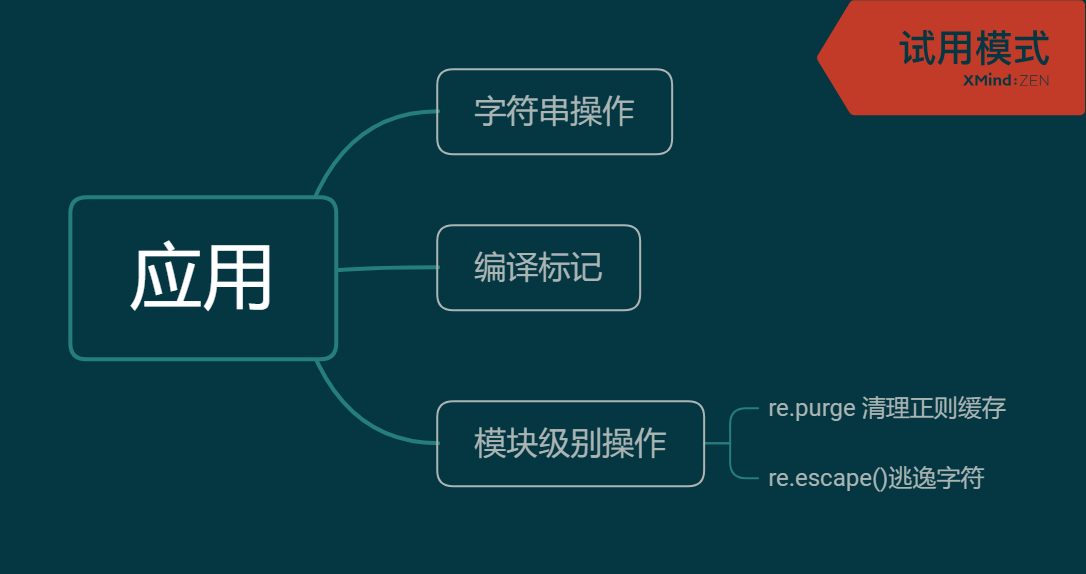
In[2]: import re In[3]: text = 'Python python PYTHON' In[5]: re.search(r'python',text) Out[5]: <re.Match object; span=(7, 13), match='python'> In[6]: re.findall(r'python',text)#找内容 Out[6]: ['python'] In[7]: re.findall(r'python',text,re.I)#找所有 Out[7]: ['Python', 'python', 'PYTHON']
In[2]: import re In[3]: re.findall(r'^<html>',' <html>') Out[3]: [] In[4]: re.findall(r'^<html>',' <html>',re.M) Out[4]: ['<html>'] In[5]: re.findall(r'd(.)','1 e') Out[5]: [] In[6]: re.findall(r'd(.)','1 e',re.S) Out[6]: [' ']

------------恢复内容结束------------