主要讲了3个新知识点:
1、双端队列BFS:应用于既有代价为1的变换、又有代价为0的变换时找最优解的广搜。
广度优先搜索是按照层次优先的顺序进行搜索,即只有搜索完当前一层的所有节点后才会去更深的一层搜索。利用这个特性,广搜可以解一些最优化问题,按照搜索思想,第一次搜索到合理的答案时答案的层次即为最小,故为最优。由于广搜不会向上搜索,故用广搜解最优化问题时应注意:只有深层次的节点全部只能由同级节点或浅层次节点扩展而来时,即深层次节点不能产生浅层次节点时才能用广搜策略解最优化问题。
由此可见,对于代价为0的转换会生成同级节点,应该在搜索深层次节点之前搜索、对于代价为1的转换会生成更深的节点,应在所有将会产生的同级节点全部搜索完后再搜索,而同级节点只会由同级节点和浅层次节点产生,并且浅层次节点已经搜索完毕。显然我们可以用数组模拟双端队列来实现这个策略。产生同级节点时就把他插到队头,产生更深的节点时就把他插到队尾,每次搜索时从队头取出一个元素进行处理,当取到答案时既得到最优解(为什么?因为显然在数组的队头下标之前的元素都不会比这个队头元素差)。
打代码时要注意用数组模拟的双端队列的队头一开始应开在数组中间位置。
扩展:对于变换代价为非负的搜索都可以用堆来做,从堆头取出答案时就得到最优解(为什么用堆?因为代价为正,不为1,所以不一定每次扩展节点时都正好扩展下一层的节点,这时用普通队列的话有可能在还没有把同级节点都搜完的情况下就搜索到了更深层次的节点。用堆保证每次搜索的节点都是当前深度最浅的节点,因为代价为正,故不会由深节点产生浅节点)。
2、HASH判重:
广搜比普通深搜快的主要原因之一就是重复的情况大部分被很好地避免了。当问题的状态很复杂、不方便直接存下来留以判重时可用HASH的思想,将复杂的东西通过HASH函数化为有时甚至可以作为下标的哈希值,来避免大量重复的情况。(map表示不服)
3、双向宽度优先搜索:
广搜的过程形象地看就是一个对图进行的一个层次优先遍历。形象理解一下,广搜找解的过程就是让由已经搜到的点形象组成的“三角形”(当然也可看成其他形状啦,看个人喜好(滑稽))不断在底部增长增高,终于使三角形覆盖到答案节点的过程。
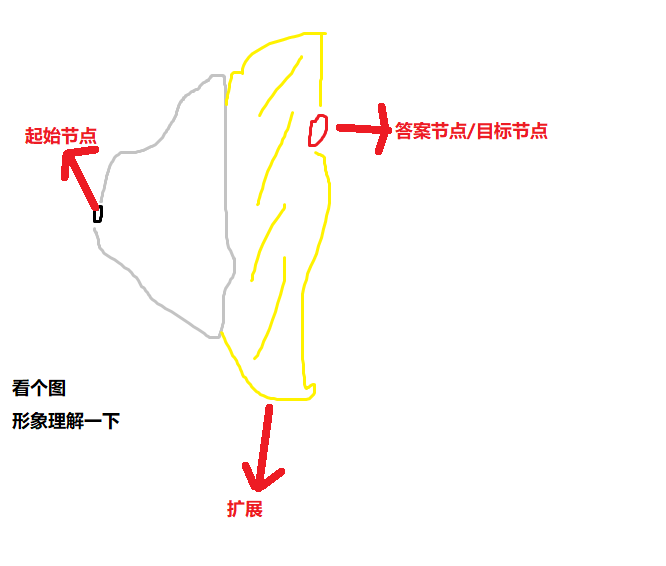
而这个三角形的面积就决定了广搜的复杂度。由几何学发现因为深度一样,所以若从起始节点和答案节点分别引出三角形,当他们顶点对的底边相交时底边上的高的和是等于深度的,而此时两图形的面积确比一开始的情况小很多,即复杂度低很多,所以用双向宽度搜索的办法有时也可以有效降低广搜的复杂度。(仿佛看见了十向宽度搜索的影子)

对于n向宽度搜索,只要建n个队列、做n个相应的判重工作,搜到一个节点时看看是否与从目标节点引出的“三角形”重叠(即已经从目标节点来搜过了)。每次从当前代扩展节点数(队列长度)最小的那个队列取出队头进行扩展(为了更加降低复杂度)并将新节点放到那个队列的队尾。其他部分按照普通广搜做就好啦。
最后再提醒一下:练习不能少呢,一些题目中独特的搜索顺序或一些奇异的状态也是让人眼前一亮啊。