最近由于要涉及一些安全运维的工作,最近在研究Elasticsearch,为ELK做相关的准备。于是把自己学习的一些随笔分享给大家,进行学习,在部署常用插件的时候由于是5.0版本的Elasticsearch踩了非常多的坑,写给大家避免大家再踩坑。
- Elasticsearch启动,5.0版本核心插件的安装。
Elasticsearch的启动十分简单,只需要平时在Linux下运行即可:
cd elasticsearch/bin ./elasticsearch &
Elasticsearch有两个王牌的工具,一般大家都会用到。一个是head,一个是bigdesk。不过不幸的是目前最新的Elastic 5.x 系列,这两个工具都不能像之前一样插件化集成,但仍可以使用,需要一些特殊的方法。
对于head工具,我们可以使用npm命令来来启动,并且由于Elasticsearch在5.0版本有严格的跨域限制,所以我们也需要修改Elasticsearch的跨域策略来允许head工具管理Elasticsearch。
配置Elasticsearch文件下config文件夹下elasticsearch.yml文件,在配置末尾添加以下内容:
http.cors.enabled: true http.cors.allow-origin: "*"
同时head工具使用npm进行启动,无法进行插件化,具体方法如下:
git clone git://github.com/mobz/elasticsearch-head.git cd elasticsearch-head npm install npm run start
对于bigdesk由于也无法插件化集成,所以需要使用python来发布。
git clone https://github.com/hlstudio/bigdesk cd bigdesk/_site/ python -m SimpleHTTPServer
- Elasticsearch核心术语理解:
这块是困扰我比较久的地方,查阅了很多资料,如果术语不能理解那么我们无法正确且合理的维护Elasticsearch集群,我是通过Head插件来进行学习和理解的。

Node:我们可以理解为一台服务器和一个虚拟机,是集群的最小分配部分,一个Elasticsearch服务器可以为一个Node。同网段的Node可以通过head来发现并进行管理。
Index:相当于一个索引,通常对应关系型数据库中的Database,我们将一大类通常分成一个Index。我们在使用head去创建Index的时候,我发现又存在两个关键名词需要理解。
shards:为了提高查询效率,一个Index要被切成多份,分别存储在多个Node上,同时为了保证高可用,配置Index时候还需要配置replica。举个例子,对于一个Index可能有5个shards,然而万一这五个shards丢了怎么办,最朴素的思想是我把这5个shards再复制一份再分别保存到其他节点上。于是在Elasticsearch集群中我们经常看到这张图,我从网上找了一个生产环境的集群来理解。
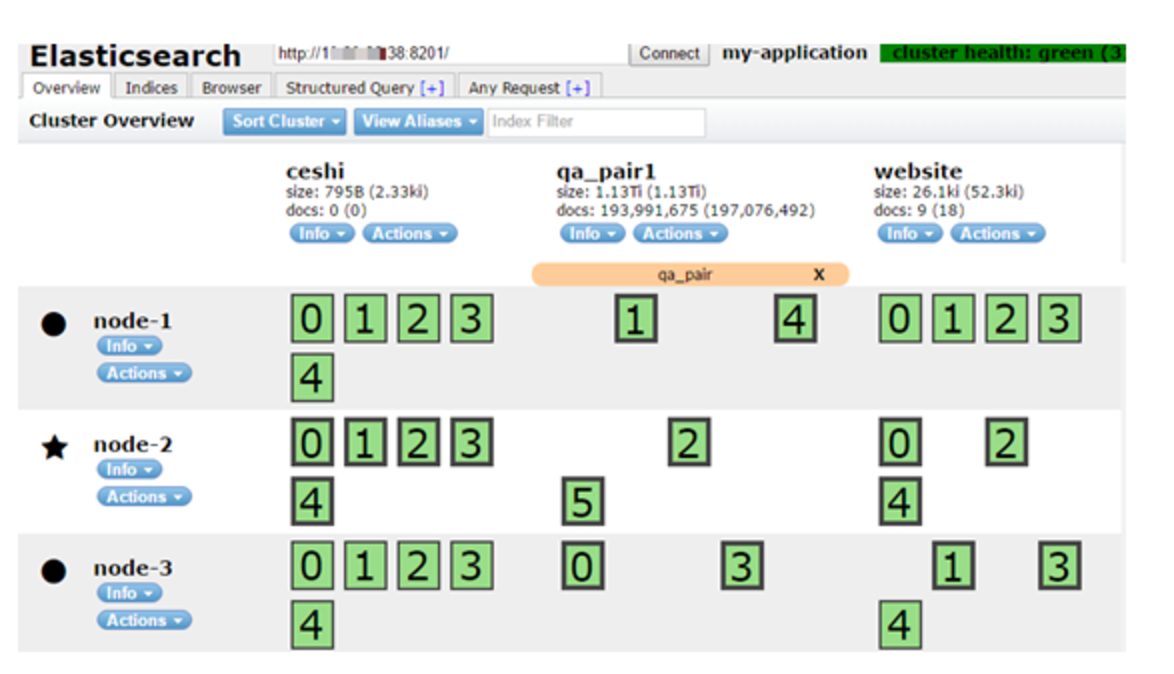
其中加粗的是分片是主分片,未加粗的分片是replica。作为备份。
后续准备总结一下Elasticsearch常见的API,以及调用关系。