FCOS: Fully Convolutional One-Stage Object Detection
特点:全卷积,单阶段,类似于语义分割的逐像素预测
优点:无anchor box, 无proposal。设计复杂度大大降低。
避免了训练时计算IOU,更重要的是避免了所有与anchor box相关的超参(检测器性能对这些超参很敏感)
结果:仅仅做了NMS后处理,FCOS with ResNeXt-64x4d-101 achieves 44.7% in AP with single-model and single-scale testing。
用来做区域建议,性能也超过RPN很多。
1.特征图上锚点到输入image空间的映射

2.回归目标
回归像素点到目标框 左上、右下 两点的距离。

3.整体架构

4.LOSS
训练时如何确定正样本点 ?:
如果映射回去的点,在某个bbox内 本身特征图上对应的类别(此目标属于此特征图的预测范围)也属于此box类别即为正样本点。否则认为其为负样本,属于背景类。
如果正样本则 c* = 1,此时l(c) = 1;否则c =0,此时l(c*) = 0,即负样本不参与位置损失,只有类别损失.
显然这里是N_positons = 特征图的像素数目
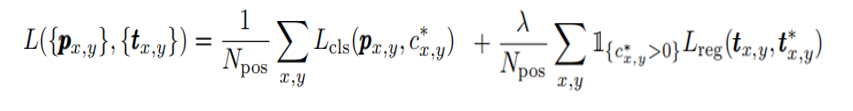
5.中心度(中心度关注的是采样点本身,同样一个目标虽然可以由多个采样点回归得到,但是不同的点应该有不同的得分,我们希望目标是由目标中心点回归得到)
作者发现性能与两阶段还有差距,发现主要问题是由于一些IOU低,但是置信得分高的离目标中心较远的预测导致了精确率的降低。
IOU低但是置信得分高,nms前置信度抑制不掉,到了IOU那里比如设置0.5,由于A.B和C的IOU都很小,依然抑制不掉。导致出现AB这种FP出现,降低了。
因此作者加了一个分支来回归centerness,预测时将 centerness与置信度score相乘 得到最终的置信度得分。
开平方根可以减缓中心度的衰减。

6.多尺度预测(训练时的策略会被模型学习到测试里)

因此,大步长范围的特征图相比于小步长范围的更可能会有标签模糊情况。如果这种策略的划分后,依然有标签模糊,我们直接选择那个box area小的标签作为其标签。