Yolo+CRNN--->CTPN+CRNN--->SegLink+CRNN--->East+CRNN--->ABCnet(Bezier曲线文本检测+CRNN变体)
https://www.leiphone.com/news/202003/CwL9pKfavCd1v8uM.html
https://blog.csdn.net/francislucien2017/article/details/103299995 当前各组件的最佳选择
当前场景文字识别较为主流的两种方法
- Attention mechanism(代表:Show, Attend and Read; Transformer-based attention; 各种各样的 2D Attention) ------在解码前给文字区域赋予较高的权重,聚焦于文本信息,弱化无关背景信息
- Rectification mechanism(STN + CRNN / DenseNet + CTC)--------一开始就先修正曲形的文字得到水平规整的文字 再进行识别
基于语义分割的思想做文本检测:PSEnet,PANnet,DBnet
https://blog.csdn.net/u012483097/article/details/104671929
检测头问题:
1.由于文字的特殊性,导致通用的目标检测容易在文本中间识别文本行的子集
2. CTPN:适合水平方向的文本检测
3. SegLink适合水平和倾斜方向的文本检测。
4. East认为1和2这种先检测字符单元,再将检测到的单元合并成区域的做法无形降低检测效率。因此直接进行区域级的检测,适合于仿射透射等任意角度方向的文本区域检测。East是基于U-net的
5. ABCnet解决是弯曲文本检测性能差的问题,利用曲线拟合去找到文本区域,提取对应区域ROI。
文本检测的发展趋势:
0.识别头一致认可CRNN识别器
1.从检测水平文字到检测弯曲任意形状文本
2.从检测单元到聚合单元的检测方法到单阶段文本检测的变化
3.从需要字符单元级的标注训练到单词级的标注训练
4.真正的单阶段的检测+识别联合训练的端到端训练(Mask TextSpotter: An End to end trainable neural Network for spotting text with abitrary shapes)
工业上这种水平场景的文本检测,依然以CRNN为主,刷榜靠识别中引入attention
小任务:实现用CTPN+CRNN训练模型,用pytorch的C++前端部署。
当前ocr技术落地存在的问题
1.通用性不强,不能自定义,不同类型的样本需要不同的模型
2.需要大量的后处理来进行信息抽取,来文本结构化并以可用格式加载
3.仅在受限场景上表现较好:分辨率较高的含数字及英文的扫描文档
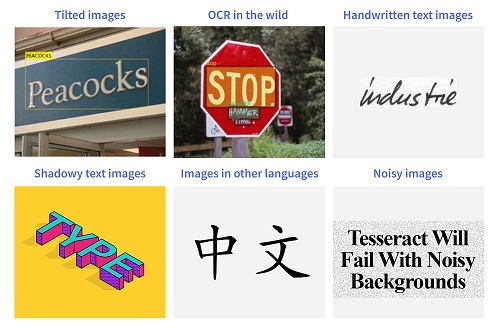
技术壁垒
1.倾斜文本
2.自然场景:未见过的字体等
3.手写字体,草书字体(完全粘连 没有字间距),字体大小
4.模糊/噪声图像:如8”和“ B”或“ A”和“ 4”
5.非英文(训练数据缺乏)