前言
嘿,各位小伙伴晚上好呀,今天又给大家带来干货内容啦,今天带来的是,如何自动登录抽屉,并且点赞
原计划打算,是不打算使用selenium的,但是因为要涉及点赞,所以免不了登录,但是我又被啪啪打脸了,抽屉的登录是真tm难,各种参数把我干懵逼了,最终,还是捡起了selenium,难逃真香定律呐
好了,废话补多少,撸起袖子就是干
准本工作
万年不变的套装...
Chromedriver:浏览器驱动,可以理解为一个没有界面的chrome浏览器
Selenium:用于模拟人对浏览器进行点击、输出、拖拽等操作,就相当于是个人在使用浏览器,也常常用来应付反爬虫措施
抽屉的点赞机制
假装我们都知道,要想点赞,需要要知道是谁点的,登录以后需要等保存状态,一般有cookie,seeeion,token三种形式,抽屉的怎么玩的呢,我们来图解一下

So,我们能看出来,只要登录之后,拿到了cookie,以后就不用 selenium 啦,所以,我这里将登录拿cooki和点赞分开写
开始干活
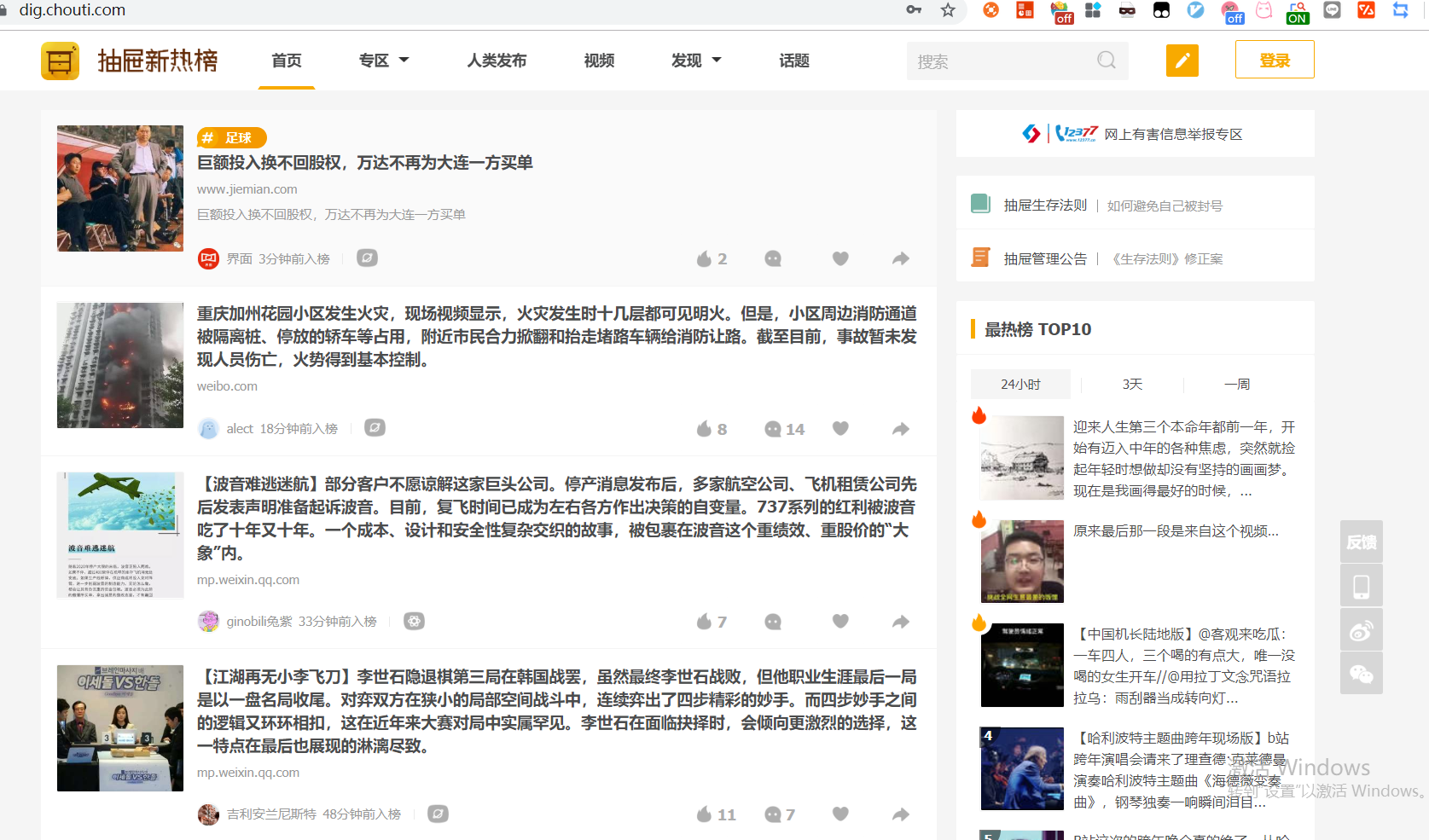
抽屉url:https://dig.chouti.com/
一个不正经的资讯社区,大概长这个样子,内容还挺不错
开始登录
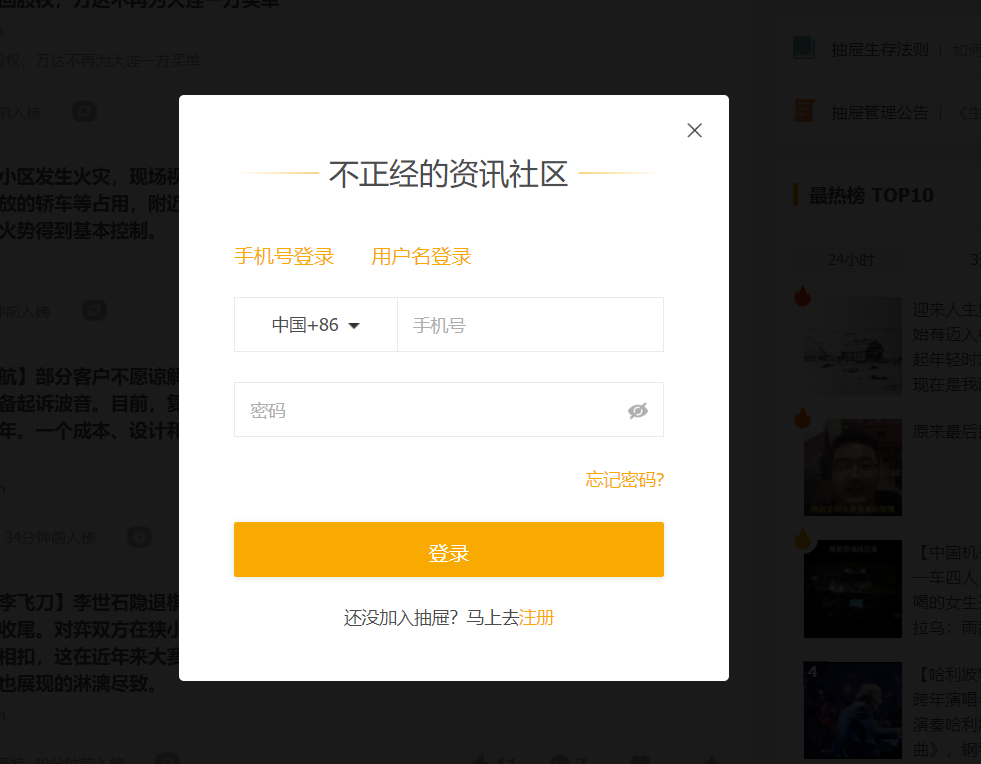
点击右上角登录,弹出登录模态对话框,下一步,用selenium盘它了,直接上代码


import time from selenium import webdriver from selenium.webdriver.support.wait import WebDriverWait # 抽屉账号密码 PHONE = "18903916120" PWD = "tian1936" # 抽屉url url = 'https://dig.chouti.com/' # 初始化 def init(): # 定义为全局变量,方便其他模块使用 global browser, wait # 实例化一个chrome浏览器 browser = webdriver.Chrome(r"G:installPagechromedriver_win32 _78.0.3904.70chromedriver.exe") # 最大化窗口 browser.maximize_window() time.sleep(2) # 设置等待超时 wait = WebDriverWait(browser, 20) # 登录 def login(): # 打开登录页面 browser.get(url) # # 获取用户名输入框 browser.find_element_by_id("login_btn").click() # browser.find_element_by_class_name("input login-phone").send_keys(PHONE) # browser.find_element_by_class_name("input pwd-input pwd-input-active pwd-password-input").send_keys(PHONE) # 输入账号密码 browser.find_element_by_name("phone").send_keys(PHONE) browser.find_element_by_name("password").send_keys(PWD) # 点击登录 time.sleep(2) click_login_btn_js = 'document.getElementsByClassName("btn-large")[0].click()' browser.execute_script(click_login_btn_js) time.sleep(15) # 获取cookie get_cookies_js = "return document.cookie" cookie = browser.execute_script(get_cookies_js) print(cookie) with open("cookie.txt", "w", encoding="utf-8") as f: f.write(cookie) # page_source = browser.page_source # with open("page.html","w",encoding="utf-8") as f: # f.write(page_source) if __name__ == '__main__': init() login()
注意事项:因为此登录是模态对话框,所以用selenium是不能点击登录按钮的,需要执行js代码
如图所示

Cookie是怎么玩的呢,我他把写在了本地,但是测试发现selenium获取cookie不全,所以我们依然使用js获取
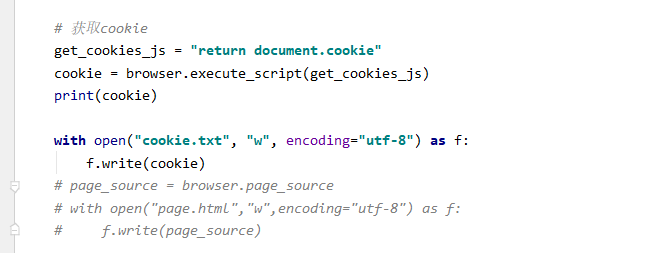
注意事项:抽屉如果登录多了,可能会让输入滑块验证码之类的,本文这部分并未有进行处理
自动登录示例效果图
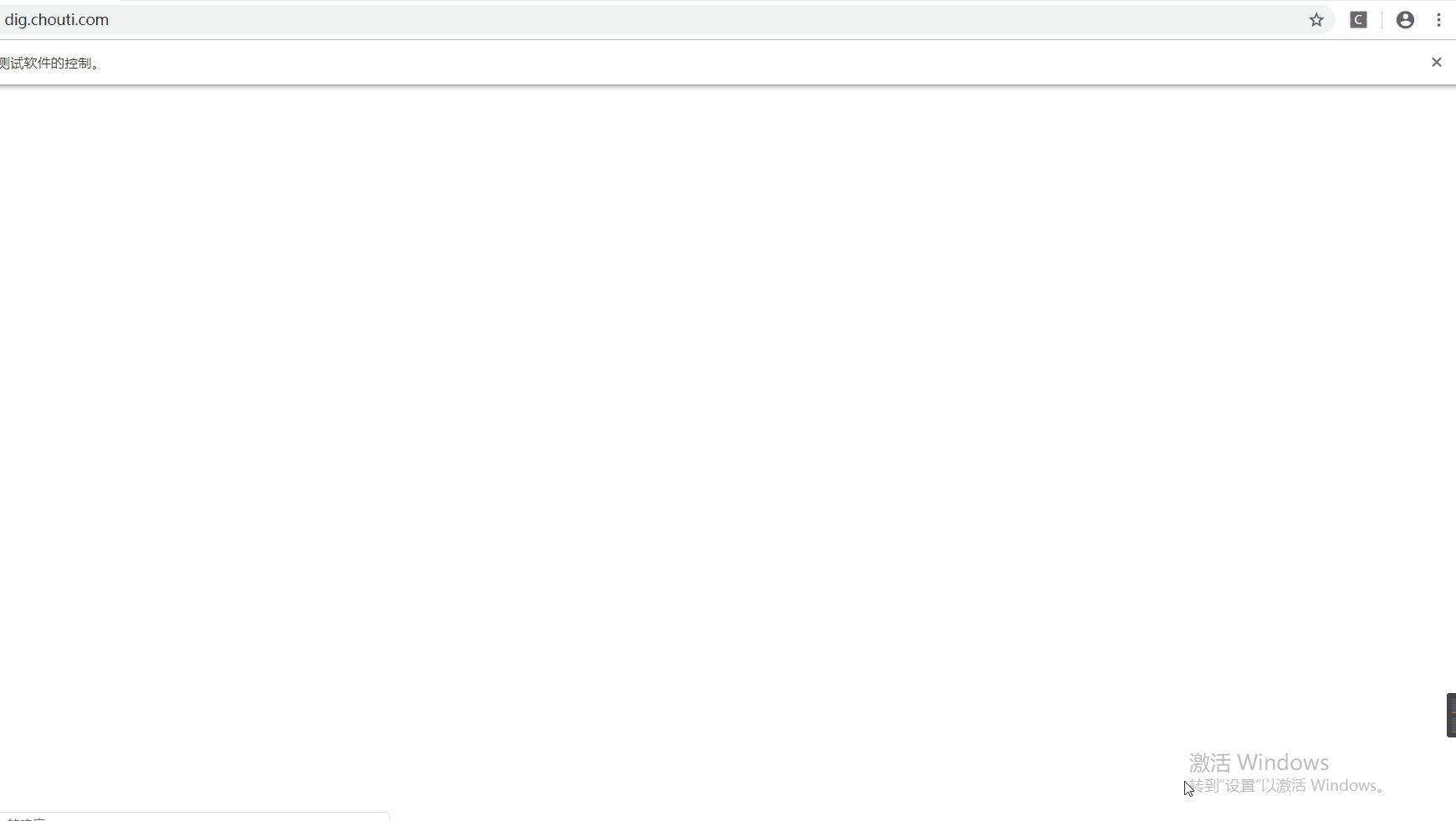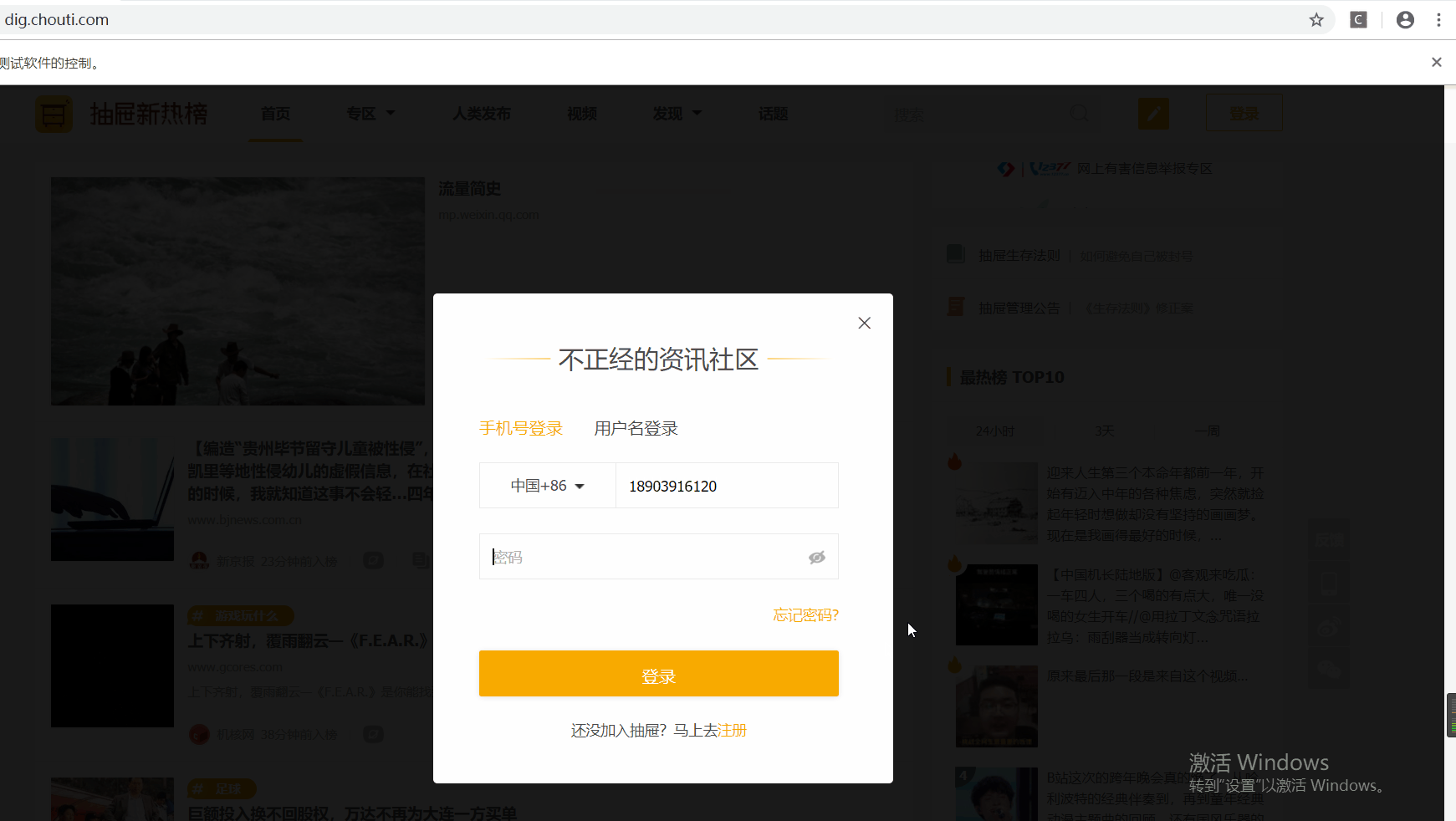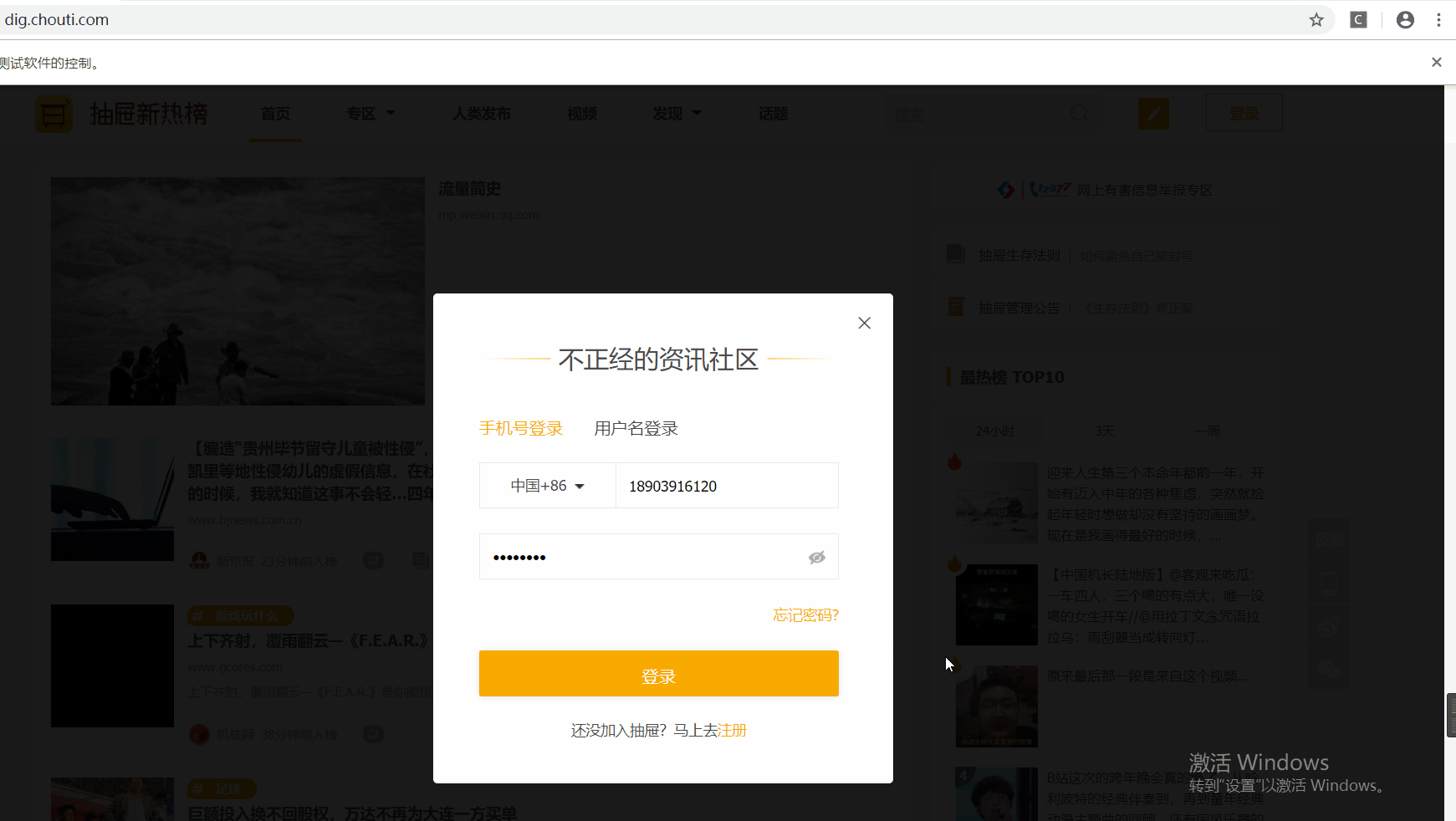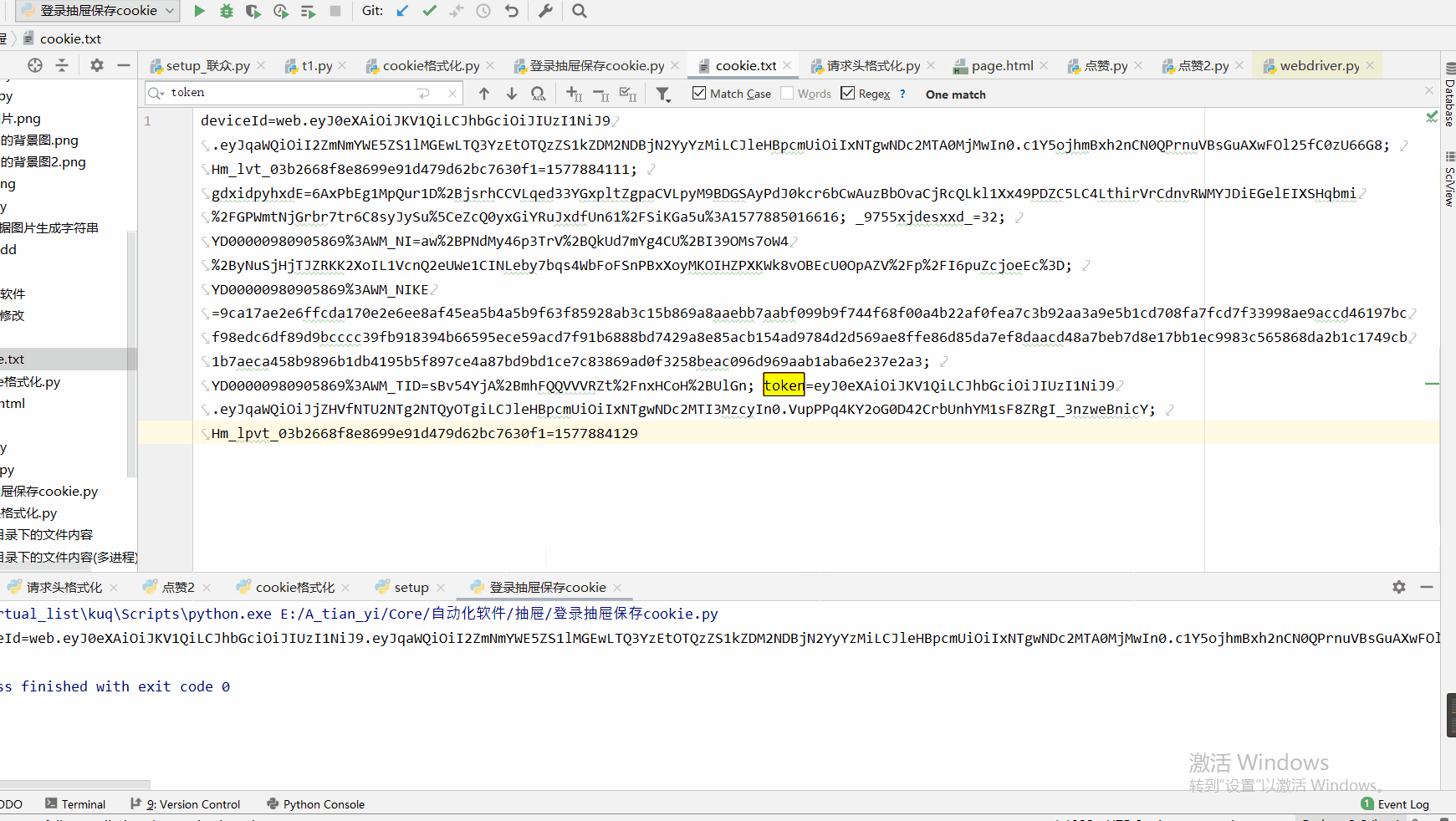
开始自动点赞
上面我们已经成功的拿到登录返回的cookie了,所以,下面我们就好办多了
我们先看一下,点赞请求的是那个接口
我们清空NetWork日志,点击第一个文章的赞按钮
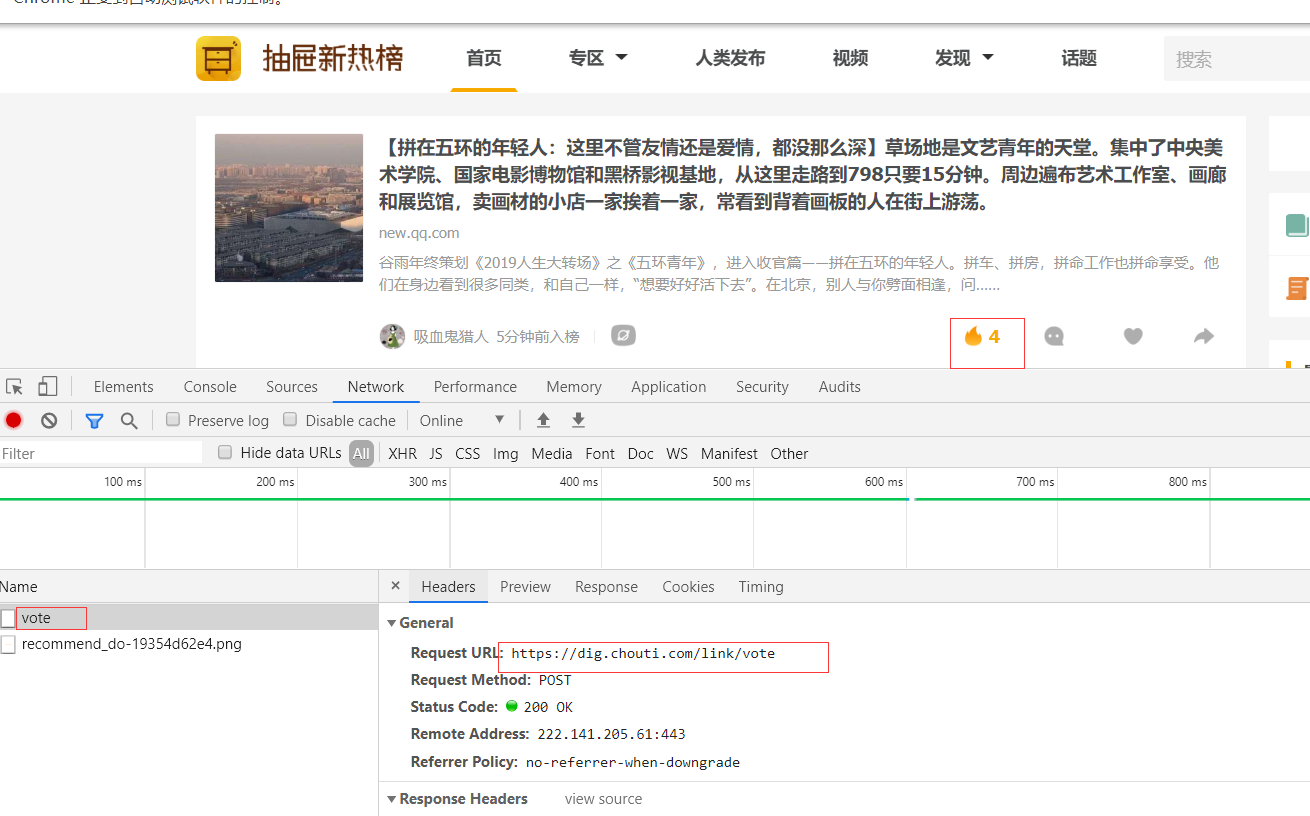
我们可以看到,这个接口发的是post请求,但是发送的是什么数据呢,我们下滑看看

2921....,我tm...,这个是什么玩意呢,马上揭晓!!!
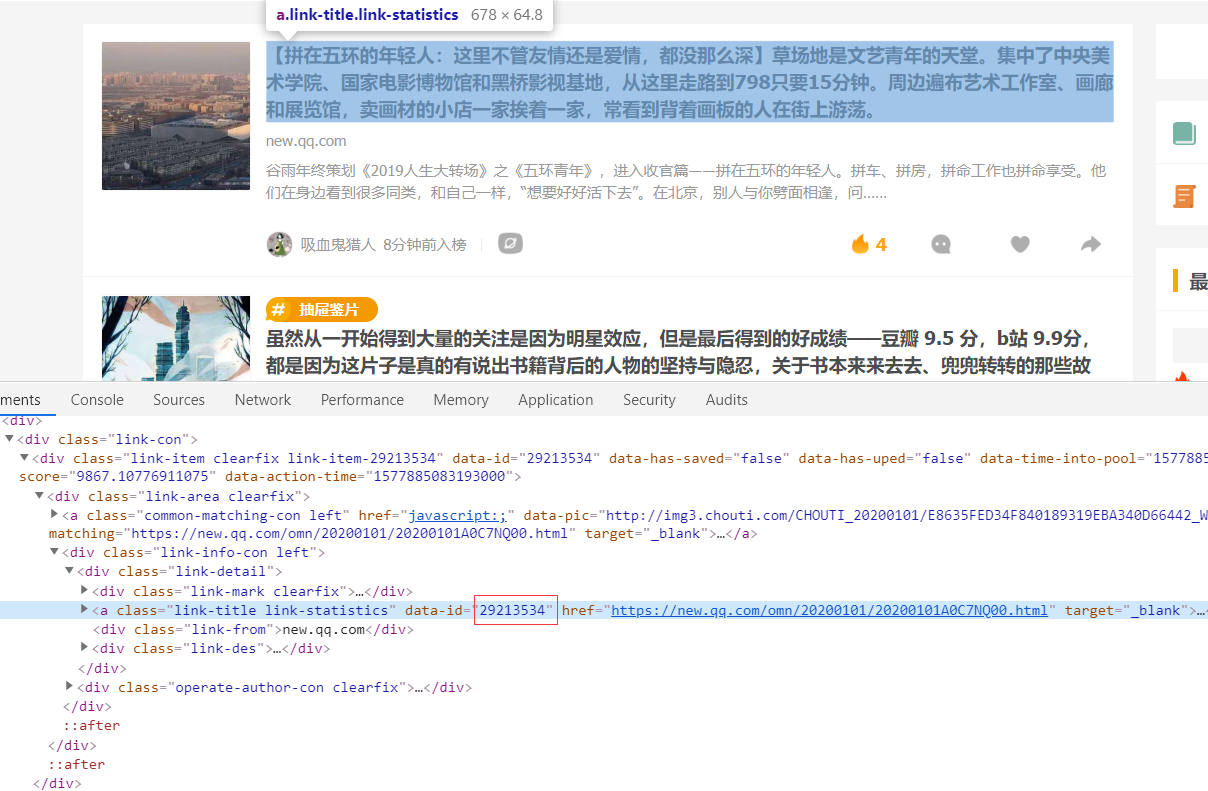
看出来吧,其实post的那一串数字,是文章ID,所以,我们只需要把这个ID都获取到,就可以点赞啦
Over,look code
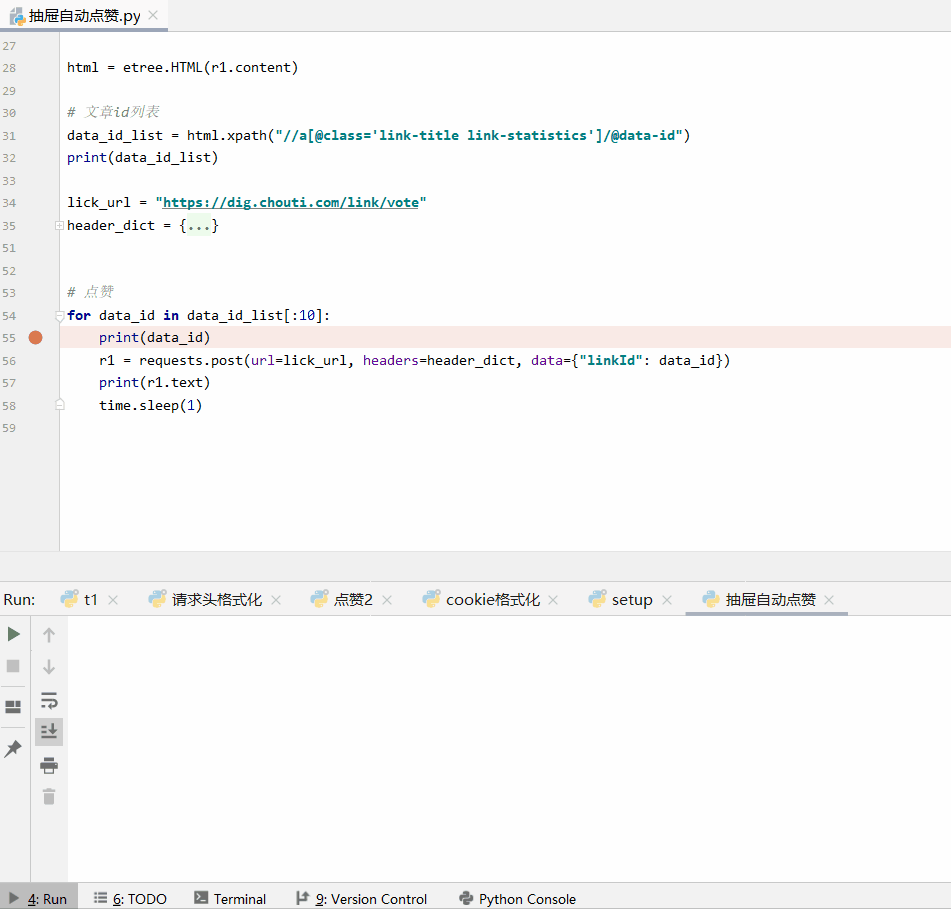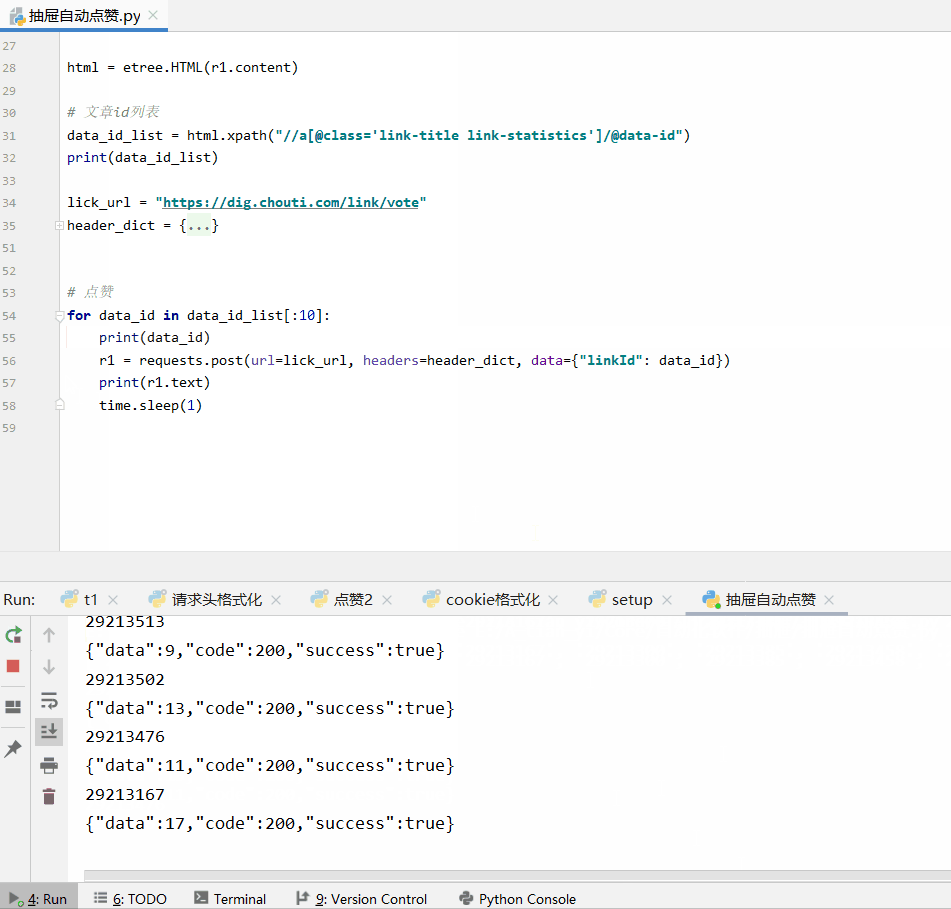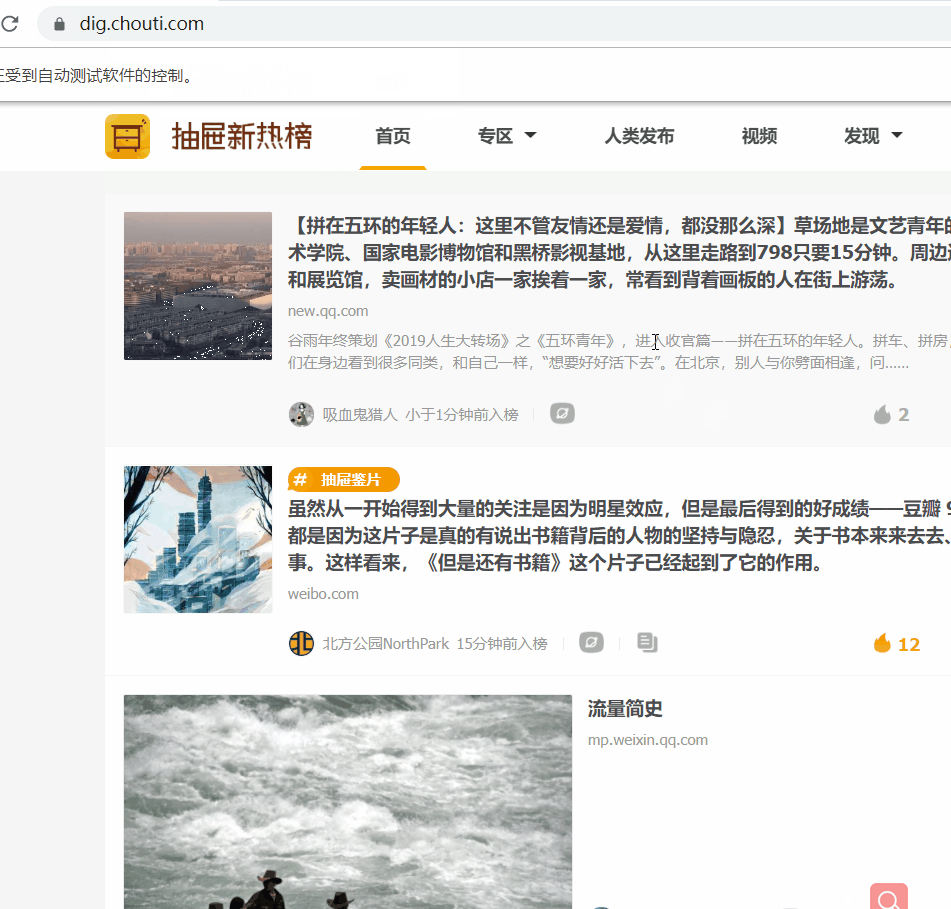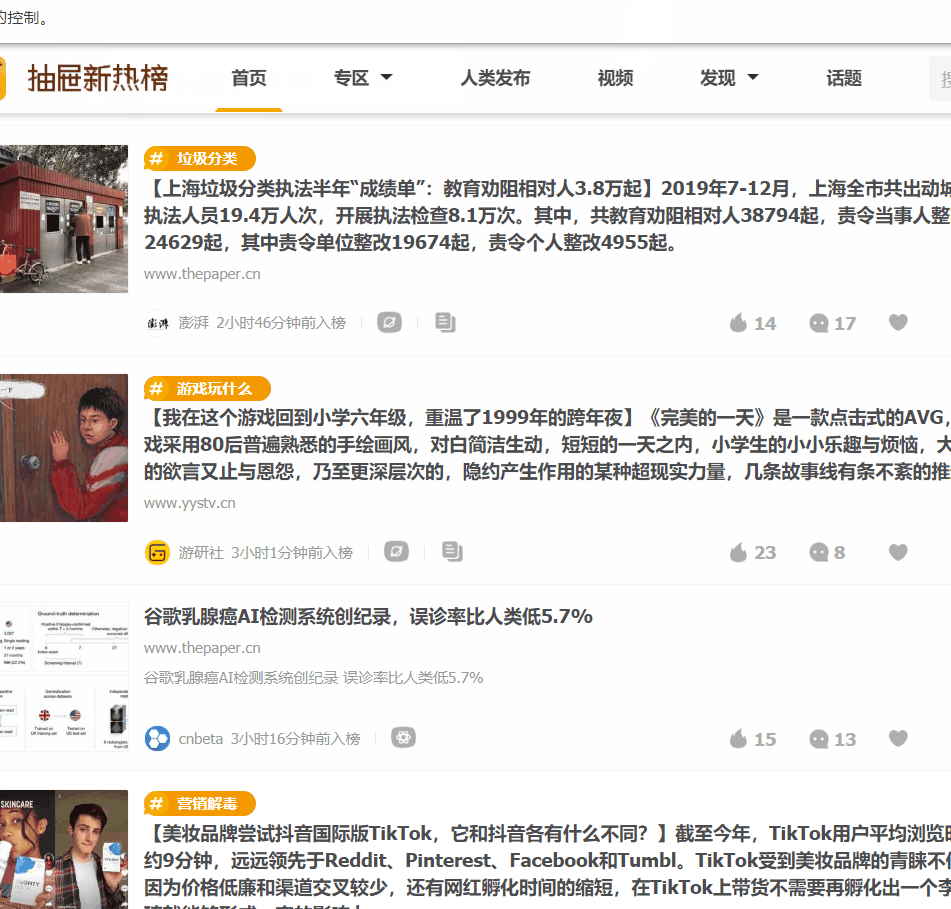
import time from lxml import etree import requests with open("cookie.txt", "r", encoding="utf-8") as f: cookie = f.read() base_url = "https://dig.chouti.com/" header_dict = { "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3", "Accept-Encoding": "gzip, deflate, br", "Accept-Language": "zh-CN,zh;q=0.9", "Cache-Control": "max-age=0", "Connection": "keep-alive", "Host": "dig.chouti.com", "Referer": "https://dig.chouti.com/?showLogin=true", "Sec-Fetch-Mode": "navigate", "Sec-Fetch-Site": "same-origin", "Sec-Fetch-User": "?1", "Upgrade-Insecure-Requests": "1", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36" } r1 = requests.get(url=base_url, headers=header_dict) r1.encoding = r1.apparent_encoding html = etree.HTML(r1.content) # 文章id列表 data_id_list = html.xpath("//a[@class='link-title link-statistics']/@data-id") print(data_id_list) lick_url = "https://dig.chouti.com/link/vote" header_dict = { "Accept": "application/json, text/javascript, */*; q=0.01", "Accept-Encoding": "gzip, deflate, br", "Accept-Language": "zh-CN,zh;q=0.9", "Connection": "keep-alive", "Content-Length": "15", "Content-Type": "application/x-www-form-urlencoded; charset=UTF-8", "Cookie": f"{cookie}", "Host": "dig.chouti.com", "Origin": "https://dig.chouti.com", "Referer": "https://dig.chouti.com/", "Sec-Fetch-Mode": "cors", "Sec-Fetch-Site": "same-origin", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36", "X-Requested-With": "XMLHttpRequest" } # 点赞 for data_id in data_id_list[:10]: print(data_id) r1 = requests.post(url=lick_url, headers=header_dict, data={"linkId": data_id}) print(r1.text) time.sleep(1)
注:这里只是测试了前10个文章
效果图