前几天一个在自学C语言的小伙伴问了我个问题,C语言结构体储存所占空间为啥和自己预测的不一样。看一下下面这一段代码:
struct node{ int num; char ch; }a; printf("%d",sizeof(a));
在我们主动去申请内存的角度看来,申请一个上面的结构体,sizeof( int ) = 4; sizeof( char ) =1; sizeof( node ) 应该等于5才对,但是程序运行得出的却是8。
小伙伴对于这个结果很是不解。这其实是CC++ 储存规则中的内存对齐(字节对齐)原则。
一 什么是字节对齐
现代计算机中,内存空间按照字节划分,理论上可以从任何起始地址访问任意类型的变量。但实际中在访问特定类型变量时经常在特定的内存地址访问,这就需要各种类型数据按照一定的规则在空间上排列,而不是顺序一个接一个地存放,这就是对齐。
二 对齐的原因和作用
不同硬件平台对存储空间的处理上存在很大的不同。某些平台对特定类型的数据只能从特定地址开始存取,而不允许其在内存中任意存放。例如Motorola 68000 处理器不允许16位的字存放在奇地址,否则会触发异常,因此在这种架构下编程必须保证字节对齐。
但最常见的情况是,如果不按照平台要求对数据存放进行对齐,会带来存取效率上的损失。比如32位的Intel处理器通过总线访问(包括读和写)内存数据。每个总线周期从偶地址开始访问32位内存数据,内存数据以字节为单位存放。如果一个32位的数据没有存放在4字节整除的内存地址处,那么处理器就需要2个总线周期对其进行访问,显然访问效率下降很多。
因此,通过合理的内存对齐可以提高访问效率。为使CPU能够对数据进行快速访问,数据的起始地址应具有“对齐”特性。比如4字节数据的起始地址应位于4字节边界上,即起始地址能够被4整除。
单纯的文字说明还是没那么好理解,下面我将通过几程序来让我们更清楚的了解到什么是内存对齐。ps: int的内存大小会随着操作系统的位数发生变化
#include "stdio.h" struct node1 { char a;char b; }; struct node2 { short a;char b; }; struct node3 { int a;char b; };
struct node4 { long a;char b; }; struct node5 { double a;char b; }; int main() { node1 char_char; node2 short_char; node3 int_char; node4 long_char; node5 double_char; //程序输出: printf("%d ",sizeof(char_char)); // 2 printf("%d ",sizeof(short_char)); // 4 printf("%d ",sizeof(int_char)); // 8 printf("%d ",sizeof(long_char)); // 8 printf("%d ",sizeof(double_char)); // 16 return 0; }
从上面这段代码及其输出结果,我们能够较为清晰的看到每个结构体的所占空间大小,均为其占内存较大的单位变量大小的倍数。
然后考虑到如果我们需要在一个结构体内存很多个不同单位的变量时候是怎么存的呢?
#include "stdio.h" struct node{ char ch; char ch1; short st; char ch2; int it; char ch3; double db;char ch4; }nd; int main(){ //程序输出: printf("%d",sizeof(nd)); //32 return 0; }
这下又让人迷惑了,虽然确实是 较大内存的double类型的整数倍 3*8 但是具体怎么储存的呢,我们输出一下这个结构体每个子成员的地址。
printf("&ch=0x%X &ch1=0x%X &st=0x%X &ch2=0x%X ",&nd.ch,&nd.ch1,&nd.st,&nd.ch2); printf("&it=0x%X &ch3=0x%X &db=0x%X &ch4=0x%X ",&nd.it,&nd.ch3,&nd.db,&nd.ch4);

这样有点抽象,不妨画个图:

可以很明显看到,图表中的所有地址就是整个结构体占用的所有空间。 内存申请空间以double对齐。交换一下结构体的声明顺序:
struct node{ char ch; char ch1; int it; char ch3; short st; char ch2; char ch4; double db; }nd;


这下算比较清晰了,int类型以四个字节进行对齐,short类型以两个字节进行对齐,char类型在对齐规则下进行单字节填充。
所以可以看到在定义结构体的时候进行适当的元素顺序调整可以有效的节省内存空间。
包含字符串的结构体也是如此:
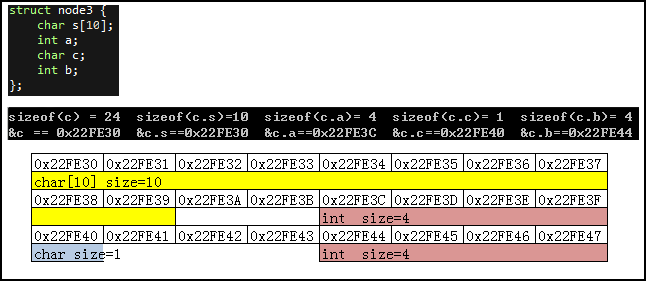

当然我们也可以通过 #pragma pack(n) 来改变这个内存对齐的方式:
#include "stdio.h" #pragma pack(1)//设定为 1 字节对齐 double a; struct node{ char ch; char ch1; int it; char ch3; short st; char ch2; char ch4; double db; }nd; int main(){ printf("%d ",sizeof(nd)); printf("&ch=0x%X &ch1=0x%X &st=0x%X &ch2=0x%X ",&nd.ch,&nd.ch1,&nd.st,&nd.ch2); printf("&it=0x%X &ch3=0x%X &db=0x%X &ch4=0x%X ",&nd.it,&nd.ch3,&nd.db,&nd.ch4); return 0; }
内存对齐调整前

内存对齐调整后


调整内存就会出现前面文本所说处理器访问效率变低的问题。