1.用 Embedding 编码的方式实现4pre1
这次将词汇量扩充到 26 个(即字母从 a 到 z)。如图 1.2.22 所示,首先建立一个映射表,把字母用数字表示为 0 到 25;然后建立两个空列表,一个用于存放训练用的输入特征 x_train,另一个用于存放训练用的标签 y_train;接下来用 for 循环从数字列表中把连续 4 个数作为输入特征添加到 x_train 中,第 5 个数作为标签添加到 y_train 中,这就构建了训练用的输入特征 x_train 和标签y_train。

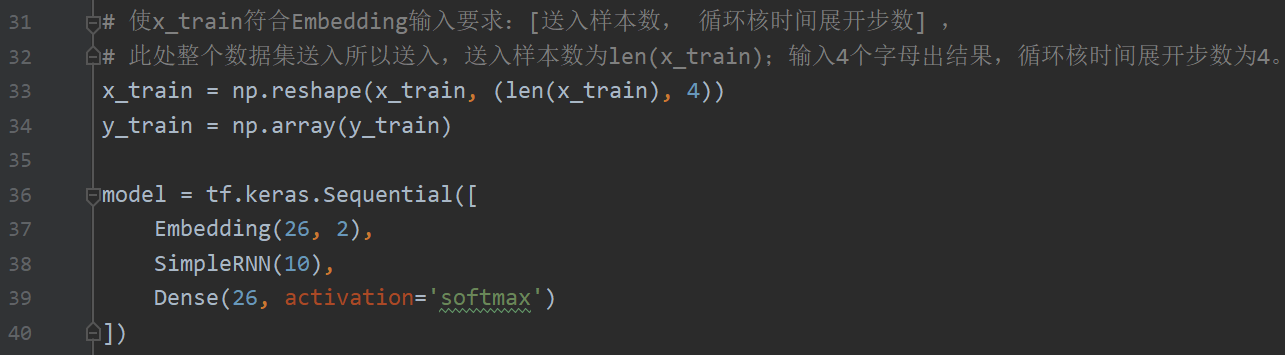
把输入特征变成 Embedding 层期待的形状才能输入网络;
在sequntial 搭建网络时,相比于 one_hot 形式增加了一层 Embedding 层,先对输入数据进行编码,这里的 26 表示词汇量是 26,这里的 2 表示每个单词用 2 个数值编码,这一层会生成一个 26 行 2 列的可训练参数矩阵,实现编码可训练。
随后设定具有十个记忆体的循环层和一个全连接层(输出会是 26 个字母之一,所以这里是 26);
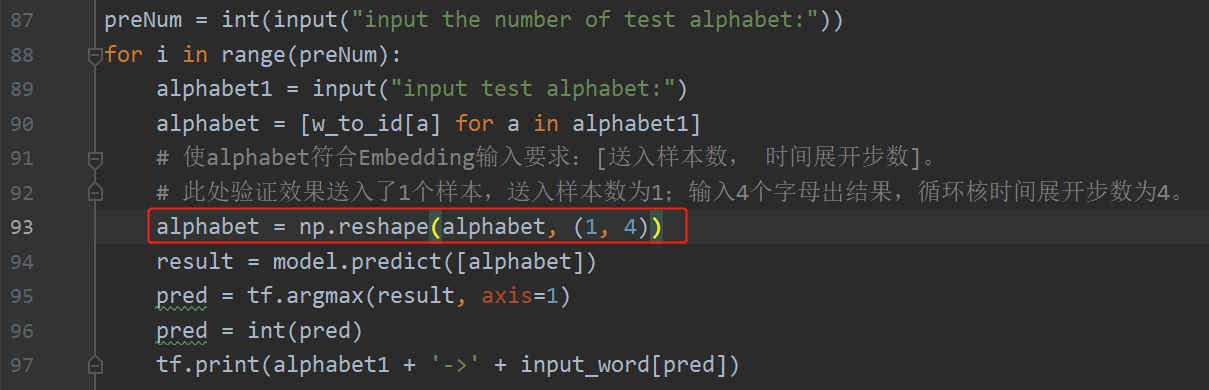
同样使用了 for 循环先输入要执行几次检测,随后等待连续输入四个字母,待输入结束后把它们转换为 Embedding 层希望的形状,然后输入网络进行预测,选出预测结果最大的一个。
2.代码实现
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Dense, SimpleRNN, Embedding
import matplotlib.pyplot as plt
import os
input_word = "abcdefghijklmnopqrstuvwxyz"
w_to_id = {'a': 0, 'b': 1, 'c': 2, 'd': 3, 'e': 4,
'f': 5, 'g': 6, 'h': 7, 'i': 8, 'j': 9,
'k': 10, 'l': 11, 'm': 12, 'n': 13, 'o': 14,
'p': 15, 'q': 16, 'r': 17, 's': 18, 't': 19,
'u': 20, 'v': 21, 'w': 22, 'x': 23, 'y': 24, 'z': 25} # 单词映射到数值id的词典
training_set_scaled = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10,
11, 12, 13, 14, 15, 16, 17, 18, 19, 20,
21, 22, 23, 24, 25]
x_train = []
y_train = []
for i in range(4, 26):
x_train.append(training_set_scaled[i - 4:i])
y_train.append(training_set_scaled[i])
np.random.seed(7)
np.random.shuffle(x_train)
np.random.seed(7)
np.random.shuffle(y_train)
tf.random.set_seed(7)
# 使x_train符合Embedding输入要求:[送入样本数, 循环核时间展开步数] ,
# 此处整个数据集送入所以送入,送入样本数为len(x_train);输入4个字母出结果,循环核时间展开步数为4。
x_train = np.reshape(x_train, (len(x_train), 4))
y_train = np.array(y_train)
model = tf.keras.Sequential([
Embedding(26, 2),
SimpleRNN(10),
Dense(26, activation='softmax')
])
model.compile(optimizer=tf.keras.optimizers.Adam(0.01),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
checkpoint_save_path = "./checkpoint/rnn_embedding_4pre1.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True,
monitor='loss') # 由于fit没有给出测试集,不计算测试集准确率,根据loss,保存最优模型
history = model.fit(x_train, y_train, batch_size=32, epochs=100, callbacks=[cp_callback])
model.summary()
file = open('./weights.txt', 'w') # 参数提取
for v in model.trainable_variables:
file.write(str(v.name) + '
')
file.write(str(v.shape) + '
')
file.write(str(v.numpy()) + '
')
file.close()
############################################### show ###############################################
# 显示训练集和验证集的acc和loss曲线
acc = history.history['sparse_categorical_accuracy']
loss = history.history['loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.title('Training Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.title('Training Loss')
plt.legend()
plt.show()
################# predict ##################
preNum = int(input("input the number of test alphabet:"))
for i in range(preNum):
alphabet1 = input("input test alphabet:")
alphabet = [w_to_id[a] for a in alphabet1]
# 使alphabet符合Embedding输入要求:[送入样本数, 时间展开步数]。
# 此处验证效果送入了1个样本,送入样本数为1;输入4个字母出结果,循环核时间展开步数为4。
alphabet = np.reshape(alphabet, (1, 4))
result = model.predict([alphabet])
pred = tf.argmax(result, axis=1)
pred = int(pred)
tf.print(alphabet1 + '->' + input_word[pred])
输出结果:

