本文基于ES8.x的内容编写
1、索引 Index
ES中的索引和关系型数据库中的表,不同的是ES中的索引时基于Json格式的.
1.1、通过Elasticsearch-head创建索引
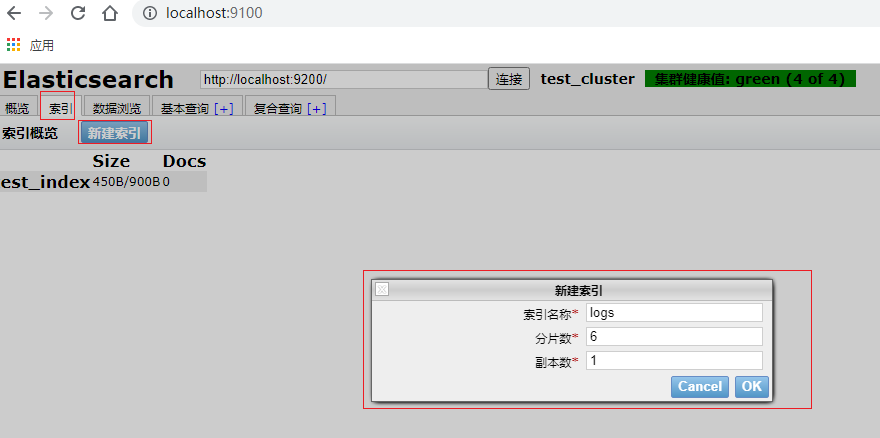
1.2、通过kibana来操作索引
首先进入kibana Dev Tools界面
1.2.1、创建索引,输入如下代码:
PUT /test_es_index
1.2.2 删除索引
DELETE /test_es_index?pretty
1.2.3 查询全部的索引信息
GET _cat/indices?v
输出如下:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size green open logs RW5m46LNR5uxkoUa5QYRdQ 6 1 2 0 20.2kb 10.1kb green open test_index gsUoL4DBQJup5T0VBTQopA 2 1 0 0 900b 450b
1.2.4 查看指定索引的信息
GET /logs/_search
输出如下:
{ "took": 4, //花费的时间 "timed_out": false, "_shards": { "total": 6,//总分片数 "successful": 6, //成功执行的分片数 "skipped": 0,//跳过的分片数 "failed": 0 //执行失败的分片数 }, "hits": { "total": { "value": 2, "relation": "eq" }, "max_score": 1, "hits": [ { "_index": "logs", "_id": "2", "_score": 1, "_source": { "level1": "error", "content": "系统异常" } }, { "_index": "logs", "_id": "1", "_score": 1, "_source": { "level": "error", "content": "系统异常" } } ] } }
1.2.5 开启或关闭索引 官方文档
POST /logs/_open
POST /logs/_close
执行之后,执行任何和当前索引相关的操作,都会有以下输出:
{ "error": { "root_cause": [ { "type": "index_closed_exception", "reason": "closed", "index_uuid": "KBOeLo04TBSJBKG6G5bMyw", "index": "logs" } ], "type": "index_closed_exception", "reason": "closed", "index_uuid": "KBOeLo04TBSJBKG6G5bMyw", "index": "logs" }, "status": 400 }
1.2.6 索引配置
(1)、number_of_shards 主分片数
(2)、number_of_replicas 副本分片数
(3)、number_of_routing_shards 路由相关的配置 具体参考文档1,文档2
(4)、codec 压缩相关
默认值使用LZ4压缩来压缩存储的数据,但这可以设置为best_压缩,它使用DEFLATE来获得更高的压缩比,但代价是存储字段的性能较慢。如果要更新压缩类型,则将在合并段后应用新的压缩类型。可以使用强制合并强制进行段合并。
(5)、soft_deletes.retention_lease.period
设置分片的历史记录保留时间,确保在合并 Lucene 索引期间保留软删除,默认为12h。
(6)、load_fixed_bitset_filters_eagerly
定义是否为嵌套查询预加载缓存过滤器。可能的值为true(默认)和false。Elasticsearch 会在分片生命周期的各个时间点自动对分片的内容进行完整性检查。
(7)、check_on_startup
仅限专家用户。此设置允许在分片启动时进行一些非常昂贵的处理,并且只有在诊断集群中的问题时才有用。如果您确实使用了它,您应该只临时使用,并在不再需要时将其删除。
此设置包含三个值:
false:打开碎片时不要执行额外的损坏检查。这是默认和推荐的行为。
checksum:验证分片中每个文件的校验和是否与其内容匹配。这将检测从磁盘读取的数据与Elasticsearch最初写入的数据不同的情况,例如由于未检测到的磁盘损坏或其他硬件故障。这些检查需要从磁盘读取整个碎片,这需要大量的时间和IO带宽,并且可能会从文件系统缓存中逐出重要数据,从而影响集群性能。
true:执行与校验和相同的检查,还检查碎片中的逻辑不一致,例如,可能是由于RAM故障或其他硬件故障导致的数据写入时损坏。这些检查需要从磁盘读取整个碎片,这需要大量的时间和IO带宽,然后对碎片的内容执行各种检查,这需要大量的时间、CPU和内存。
1.2.7 动态索引配置 具体参考官方文档
| 标题 | |
|---|---|
index.number_of_replicas |
每个主分片具有的副本数,默认为 1 |
| index.auto_expand_replicas | 根据集群中的数据节点数量自动扩展副本数量,默认为false |
| index.search.idle.after | 分片在被视为搜索空闲之前无法接收搜索或获取请求的时间。(默认为30s) |
| index.refresh_interval | 执行刷新操作的频率;默认为1s. 可以设置-1为禁用刷新 |
| index.max_result_window | from + size搜索此索引 的最大值,from表示起始数据的序号,size表示数据数。默认为 10000,太小可能导致Result window is too large |
| index.max_inner_result_window | 限制返回 结果中的 结果集,默认为100 |
| index.max_rescore_window | docvalue_fields查询中允许 的最大数量 |
| index.max_docvalue_fields_search | script_fields查询中允许 的最大数量,默认为32 |
| index.max_script_fields | script_fields查询中允许 的最大数量,默认为32 |
| index.max_ngram_diff | NGram令牌生成器中的max_gram和min_gram之差必须小于或等于max_script_fields |
| index.max_shingle_diff | shingle令牌过滤器的 max_shingle_size 和 min_shingle_size 之间的最大允许差异,默认为 3 |
| index.max_refresh_listeners | 索引的每个分片上可用的最大刷新侦听器数 |
| index.analyze.max_token_count | 可使用 _analyze API 生成的最大令牌数,默认为10000 |
| index.highlight.max_analyzed_offset | 将为突出显示请求分析的最大字符数 |
| index.max_terms_count | Terms查询中可以使用的最大术语数,默认为65536 |
| index.max_regex_length | 可以在 Regexp Query 中使用的 regex 的最大长度,默认为1000 |
| index.query.default_field | 匹配一个或多个字段的通配符模式 |
| index.routing.allocation.enable | 控制此索引的分片分配:all(所有分片)、primaries(主分片)、new_primaries(新创建的主分片)、none(不允许) |
| index.routing.rebalance.enable | 为此索引启用分片重新平衡:all、primaries、replicas(副分片)、none |
| index.gc_deletes | 文档删除后的保留时间,默认 60S |
| index.default_pipeline | 索引 的默认摄取节点管道 |
| index.final_pipeline | 最终管道 |
| index.mapping.dimension_fields.limit | 索引的最大时间序列维度数(仅供 Elastic 内部使用) |
| index.hidden | 指示默认情况下是否应隐藏索引,默认不隐藏 |
2、文档 Document
ES中的文档和关系型数据库中的表的数据行类似,是ES中的最小存储单元,下面,,输入以下命令
2.1 通过kibana来操作文档
首先进入kibana Dev Tools界面
2.1.1 创建一条文档
PUT logs/_doc/1 { "level":"error", "content":"系统异常" }
执行以上命令,结果如下:
{ "_index": "logs", //索引的名称 "_id": "1", //文档id "_version": 1, //版本 "result": "created", //执行结果 "_shards": { "total": 2, "successful": 2, "failed": 0 }, "_seq_no": 0, "_primary_term": 1 }
2.1.2 删除一条数据
DELETE logs/_doc/2
执行以上命令,结果如下:
{ "_index": "logs",//索引名称 "_id": "2", //文档id "_version": 2, //版本 es删除修改走的是软删除和版本修改 "result": "deleted", //执行结果 "_shards": { "total": 2, "successful": 2, "failed": 0 }, "_seq_no": 1, "_primary_term": 1 }
2.1.2 全量修改
PUT logs/_doc/1 { "level":"error1", "content":"系统错误" }
注:PUT指令可以用作添加,也可以用作修改,但是修改时,之前的文档内容必须先查出来,然后进行修改,如果少了字段,PUT指令会做覆盖操作.
2.1.3 部分修改
PUT logs/_doc/1 { "level":"error1", "content":"系统错误" }
执行以上命令,结果如下:
{ "_index": "logs", "_id": "1", "_version": 7, "result": "updated", //执行结果 "_shards": { "total": 2, "successful": 2, "failed": 0 }, "_seq_no": 8, "_primary_term": 1 }