作业要求:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3159
前言:
据课上要求,需爬取数据并生成文章,故选择爬去实习僧的招聘数据进行分析。
获取数据:
分析实习僧的地址可知,实习僧的地址组成为“域名”/“类别”/“页数”,此次我们爬取互联网相关的职业,故爬取的地址为:https://www.shixiseng.com/it/
首先我们要获得所有列表页面的url:
#获取指定it页范围的url def getItUrl(url,start,end): urls=[] for i in range(start,end): urls.append("{}/{}".format(url,i)) return urls
其次通过获取的页面url获取详情页url:
#获取it页的url def getItListUrl(url): itList=[] res=requests.get(url) res.encoding='utf-8' soup=bs4.BeautifulSoup(res.text,'html.parser') alist=soup.select(".position-list .info1 a") for i in alist: itList.append(i['href']) return itList
再然后通过详情页的url获取详情数据,由于实习僧有反字体爬取,故爬取后的数据需进行数字转码处理:
#获取职位详情 def getDetail(url): position={} headers={ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36", } res=requests.get(url,headers=headers) res.encoding='utf-8' chText=res.text #数字解码 replace_dict = { '': '0', '': '1', '': '2', '': '3', '': '4', '': '5', '': '6', '': '7', '': '8', '': '9', } for key, value in replace_dict.items(): if key in chText: chText = chText.replace(key, value) soup = bs4.BeautifulSoup(chText, 'html.parser') try: position["jobName"]=soup.select(".new_job_name span")[0].text; position["jobDate"]=soup.select(".job_date span")[0].text; position["jobMoney"]=soup.select(".job_money")[0].text; position["jobPosition"]=soup.select(".job_position")[0].text; position["jobAcademic"]=soup.select(".job_academic")[0].text; position["jobWeek"]=soup.select(".job_week")[0].text; position["jobTime"]=soup.select(".job_time")[0].text; position["jobDetail"]=soup.select(".job_detail")[0].text.strip(); position["jobCity"]=soup.select(".com_position")[0].text; position["comName"]=soup.select(".com-name")[0].text; except IndexError: return {} comDetails=soup.select(".com-detail span"); try: position["comCity"]=comDetails[0].text; except IndexError: position["comCity"]="" try: position["comNum"]=comDetails[1].text[3:]; except IndexError: position["comNum"]="" try: position["comClass"]=comDetails[2].text[3:]; except IndexError: position["comClass"]="" #print(position) print("finish") return position
数据爬取完成后需将数据存入csv文件中:
df=pd.DataFrame(itList) df.to_csv("shixiceng.csv",encoding='utf-8')
将数据存储到Sqlite3中:
shixisengdf = pd.read_csv('news.csv') with sqlite3.connect('sqlitetest.sqlite') as db: shixisengdf.to_sql('data',con = db)
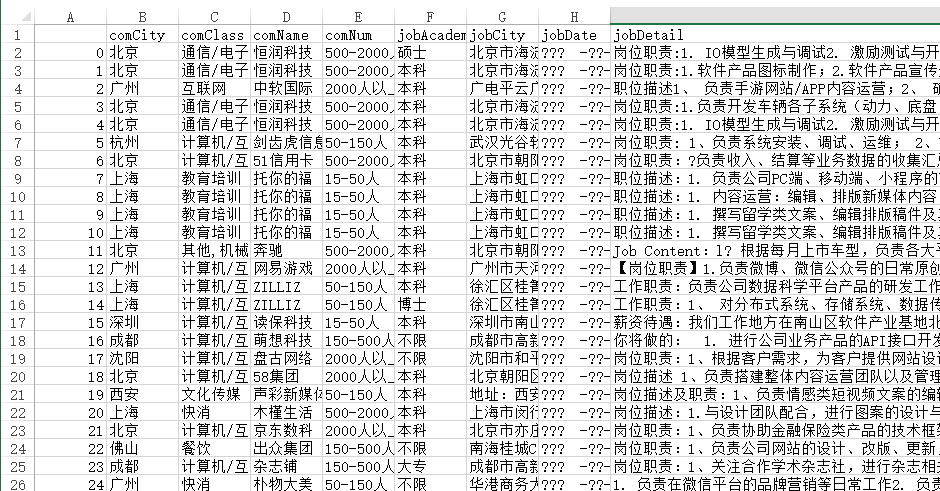
总共爬取了5000条数据,爬取后的数据展示:
数据可视化:
对数据进行词云处理,发现本科学历,学习能力强,责任心强是公司的第一选择。

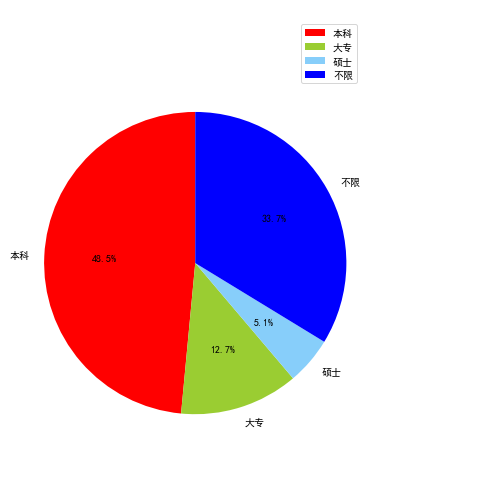
对最低学历进行分组,发现本科占率高达70%,而大专只有7.5%,由此可见,互联网行业对于学历的要求还是偏高的。
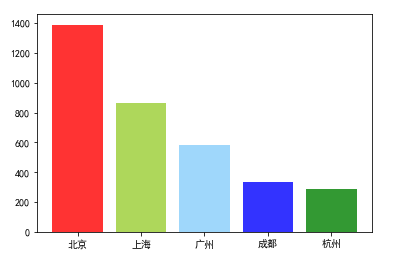
对工作城市进行了排序处理,发现北京第一,上海第二,广州第三