监控系统的入门搭建 Prometheus(普罗米修斯)
基础理论篇
对于普罗米修斯的介绍可以参考这篇文章,写的非常好,非常权威,不逊色于官方文档,可以说是中文环境下最好的参考资料
Prometheus 入门与实践
吴莉, 殷一鸣, 和蔡林
2018 年 5 月 30 日发布
我想写出一篇超过这篇文章显然以现在的实力是不太现实
毕竟是很权威的文章,这种文章的通病就是太过学术,没有了解过的人很难读过就能明确的理解。
那么就有我自己的理解来讲讲Prometheus的各个方面的问题
可能有的观点是错误的,所以还是把他当成茶余饭后的休闲文章看看吧
Prometheus到底在我的服务器,kvm,或者docker上做了什么?
首先要解答这个问题,我们必须了解一个重要的概念
Metric
这个官方文档出现频率的最高的单词
谷歌机翻翻译为度量,我觉得翻作指标可能更加贴切
其实它的本质就是存在某一款数据库的一条记录
什么是metric
这篇文章介绍的也很详细
总之就是监控系统通过服务将某个监控数据存入某个数据库的某条记录
这条记录可以动态的增加字段,最终得到了通用的metric结构,name,label(与tag{}同义仅名字不同,在Prometheus中为label),value,timestamp
我们将额外需要扩展增加的数据生成json存入label{} ,这样可以方便的扩展字段,而不用每次都修改数据库的表结构
(PS:在Prometheus中提供四种 Metric 类型 Counter, Gauge, Histogram,Summary)
具体的内容我就不再赘述,可以通过上文来了解Metric
那么了解Metric,我们还需要了解alert
Alert其实就是警报,我们的监控系统就是为了在集群出现问题的时候
及时向运维人员报告
那么Prometheus究竟对我们的机器做了什么?
它的组成
Prometheus Server:
用于收集和存储时间序列数据。
Client Library:
客户端库,为需要监控的服务生成相应的 metrics 并暴露给 Prometheus server。
当 Prometheus server 来 pull 时,直接返回实时状态的 metrics。Push Gateway: 主要用于短期的 jobs。
由于这类 jobs 存在时间较短,可能在 Prometheus 来 pull 之前就消失了。
为此,这次 jobs 可以直接向 Prometheus server 端推送它们的 metrics。
这种方式主要用于服务层面的 metrics,对于机器层面的 metrices,需要使用 node exporter。
Exporters:
用于暴露已有的第三方服务的 metrics 给 Prometheus。
Alertmanager:
从 Prometheus server 端接收到 alerts 后,会进行去除重复数据,分组,并路由到对收的接受方式,发出报警。
常见的接收方式有:电子邮件,pagerduty,OpsGenie, webhook 等。
一些其他的工具:
。。。。。。。。
Prometheus架构图
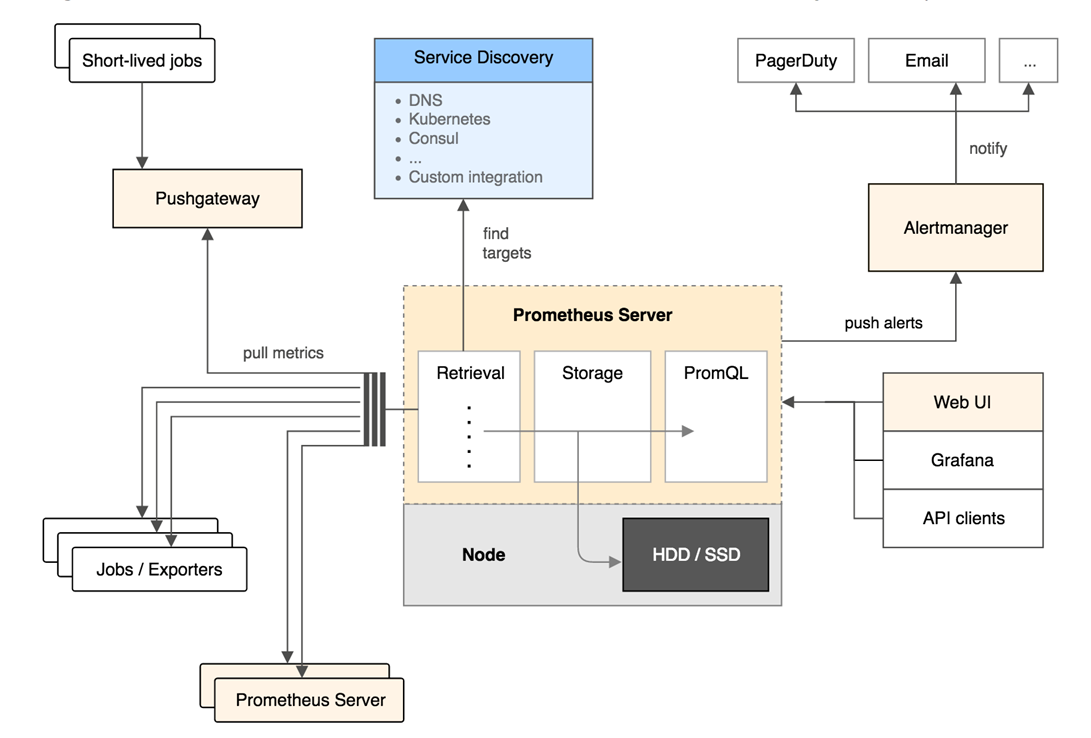
其中jobs/Eeporters就是生成metric的,然后我们的Prometheus server从它们那定期获取metrics,或者一些短暂的jobs生成的metric推送给Pushgateway
再由Pushgateway推送给Prometheus server,或者其他机器的Prometheus server发给本机的Prometheus server,
总之我们想获取的的数据源在Prometheus server中汇总后按照我们规定的报警机制(alert.rules)推送警报到Alertmanager或者刷新时间序列(就是不报警,相安无事)
最后Alertmanager 根据配置文件,对接收到的警报进行处理,发出告警。在图形界面中,可视化采集数据(这一步我们放在grafana上去做)
(PS:
instance 和 jobs.的区别
instance:
一个单独 scrape 的目标, 一般对应于一个进程。
jobs:
一组同种类型的 instances(主要用于保证可扩展性和可靠性))
例如:清单 1. job 和 instance 的关系
job: api-server instance 1: 1.2.3.4:5670 instance 2: 1.2.3.4:5671 instance 3: 5.6.7.8:5670 instance 4: 5.6.7.8:5671
当 scrape 目标时,Prometheus 会自动给这个 scrape 的时间序列附加一些标签以便更好的分别,例如: instance,job。
下面以实际的 metric 为例,对上述概念进行说明。

如上图所示,这三个 metric 的名字都一样,他们仅凭 handler 不同而被标识为不同的 metrics。这类 metrics 只会向上累加,是属于 Counter 类型的 metric,且 metrics 中都含有 instance 和 job 这两个标签
到此我们已经了解了Prometheus 最基础的个概念,下一篇我们就要小试牛刀,试试实际运行